概要
『Yukarinライブラリ』yukarin, become-yukarin リポジトリで、自分の音声をターゲット音声に変換する手順を紹介する。
yukarin は become-yukarin の改良版リポジトリであるが、2019/06/24 現在、become-yukarin での学習データを必要が必要になる。
よって、冗長となるが、 become-yukarin, yukarin 両方のコマンド解説を行う。
前提として『Yukarinライブラリ』 yukarin, become-yukarin 概要・リポジトリ関係を整理してみたを把握しているものとします。
◾️ Discord サーバ紹介
YukarinライブラリユーザのDiscordサーバを立ち上げました。
ご相談・エラー対応・ノウハウ共有などしたいと思っています。
ご気軽にご参加ください。
Yukarinライブラリ Discord サーバ 招待リンク
◾️ Yukarinライブラリとは?
**『自分の声(自声)』**を **『好きな音声(ターゲットボイス)』**に 1対1 対応で音質変換をする OSS です。
yukarin, become-yukarin ではオフラインでの音声変換しかできませんが、学習データを realtime-yukain で実行することで、リアルタイム変換することもできます。
詳細は下記を参照ください。
- 製作者のヒホ様の動画 : ディープラーニングの力で結月ゆかりの声になってみた
- 製作者のヒホ様のブログ: ディープラーニングの力で結月ゆかりの声になってみた
- まとめ情報記事 : ディープラーニング声質変換OSS「誰でも好きなキャラの声になれる」レポジトリ become-yukarinなどの関連記事等一覧
◾️ 用語
Yukarinライブラリ
『yukarin』 と 『become-yukarin』の 2つをひっくるめて『Yukarinライブラリ』と命名されています。
- Hiroshiba/yukarin : 誰でも好きなキャラの声になれるリポジトリ』
- Hiroshiba/become-yukarin : 旧名は『ディープラーニングの力で誰でも結月ゆかりになれるリポジトリ』
"ゆかり音声"
ターゲット音声は任意ですが、イメージしやすいように 『ターゲット音声 = 結月ゆかり』と仮定します。
よって、"ターゲット音声"を"ゆかり音声"と表現します。
◾️ GPU は何がいいの?
- realtime-yukarin を使う: GTX 1060(6G) 以上(readmeより)
- ただ変換するだけ: GTX 970(4G) 以上(become-yukarinの第2段では GPUメモリが 4G必要)
- 個人的なおすすめ : GTX 1070(8G) 中古(安くて・そこそこ早くて、GPUメモリが 8Gある)
◾️ 環境構築方法
・ Ubuntu v19.04 (RTX対応)
・ Ubuntu v18.10 LTS : @sakamotothogo 様
補足
Yukarinライブラリの推奨実行環境は、Linux ですが Windowsや Google Colaboratoryでも実行可能です。
-
Windowsでの実行記事
Windowsで誰でも好きなキャラの声になれるyukarinライブラリを動かしてみた。
・メリット : Windows PCだけで学習・変換ができるので Linuxが必要ない。
・デメリット: 学習速度が遅めで、ソース修正などが必要。エラー対応のノウハウが少ない。 -
Google Colaboratoryでの実行記事
「GPU・Linuxがなくても、Google Colaboratoryで『Yukarinライブラリ』を使いたい」
・メリット: 環境構築が必要なく、ブラウザだけで学習・変換ができる。
・デメリット: 全般的に処理が遅め、学習時間に12時間上限がある。
◾️ 知っていると便利な知識
- git : 簡単に最新リポジトリに更新できる
- PyCharm コミュニティ版(無料) : Python・機械学習を勉強するなら強く推奨
◾️ エラーなどで困った時は?
- 気軽にコメントに書いてください!
- 『Yukarinライブラリ』 become-yukarin, yukarin のトラブルシューティング を見てみる
-
yukarinコマンドジェネレーター!
も参考になります
◾️ 目次

Z. become-yukarin, yukarin共通の事前作業
Z.0 念のためのソフトインストール
git, ffmpeg, sox, tree などのインストールコマンドを実行してください。
コマンド(Ubuntu)
sudo apt install git
sudo apt install tree
sudo apt install ffmpeg
sudo apt install sox
Z.1 ディレクトリ作成
作業ディレクトリを決定する
任意で構いませんが、後でディレクトリ移動させると環境変数の書き換えが必要となるので、気をつけてください。
この記事では HOME 直下の deep_yukarin ディレクトリで作業をすると仮定します。
以下で説明する各種コマンドは、 deep_yukarin 直下で実行すると想定しています。
mkdir ~/deep_yukarin
cd deep_yukarin
ディレクトリ作成
本記事では以下のディレクトリ構造を前提にコマンド解説します。
リポジトリの相関や音声データの依存関係を考慮して、独断と偏見で決めてました。
作業ディレクトリに移動したあと、下記コマンドをコピペで実行してください。
コマンド
mkdir dat
mkdir dat/1st_models_by
mkdir dat/2nd_models_by
mkdir dat/1st_models_y
mkdir dat/1st_models_by/yukari
mkdir dat/1st_models_by/yukari/npy_pair
mkdir dat/1st_models_by/yukari/npy_pair/own
mkdir dat/1st_models_by/yukari/npy_pair/target
mkdir dat/2nd_models_by/yukari
mkdir dat/1st_models_y/yukari
mkdir dat/1st_models_y/yukari/aligned_indexes
mkdir dat/1st_models_y/yukari/aligned_wav
mkdir dat/1st_models_y/yukari/statistics
mkdir dat/1st_models_y/yukari/npy_pair
mkdir dat/input
mkdir dat/output
mkdir dat/voice_src
mkdir dat/voice_src/voice_24000
mkdir dat/voice_src/voice_44100
mkdir dat/voice_src/voice_24000/yukari_pair
mkdir dat/voice_src/voice_24000/yukari_pair/own
mkdir dat/voice_src/voice_24000/yukari_pair/target
mkdir dat/voice_src/voice_24000/yukari_single
mkdir dat/voice_src/voice_44100/yukari_pair
mkdir dat/voice_src/voice_44100/yukari_pair/own
mkdir dat/voice_src/voice_44100/yukari_pair/target
mkdir dat/voice_src/voice_44100/yukari_single
チェック
tree コマンドで下記のようになっているか確認してください。
tree dat
dat
├── 1st_models_by
│ └── yukari
├── 1st_models_y
│ └── yukari
├── 2nd_models_by
│ └── yukari
├── input
├── output
└── voice_src
├── voice_24000
│ ├── yukari_pair
│ │ ├── own
│ │ └── target
│ └── yukari_single
└── voice_44100
├── yukari_pair
│ ├── own
│ └── target
└── yukari_single
Z.2 各種リポジトリの取得
- yukarin
- become-yukarin
- 筆者自作のチェックツール
- 日本声優統計学会の音素バランス文
を git で取得します。
* git を使わずサイトからダウンロードでもいいが、更新があった場合修正が面倒です。
* 筆者のチェックツールは必須ではありませんが、あること前提で解説します。
コマンド
git clone https://github.com/Hiroshiba/become-yukarin
git clone https://github.com/Hiroshiba/yukarin
git clone https://YoshikazuOota@bitbucket.org/YoshikazuOota/yukarin-tools.git
git clone https://github.com/YoshikazuOota/balance_sentences.git
チェック
tree -L 1
.
├── balance_sentences
├── become-yukarin
├── dat
├── yukarin
└── yukarin-tools
補足: 各種リポジトリを最新版を反映する場合
yukarin, become-yukarin 等の各種のディレクトリに移動して、git pull を実行する
cd ~/deep_yukarin
cd [yukarin, become-yukarin]
git pull
さらに yukarin-tools 用に下記コマンドを実行してください。
sudo apt install nodejs
sudo apt install lm-sensors
cd yukarin-tools
npm install
cd ~/deep_yukarin
Z.3 音声データの収録
Z.3.1 音声データ作成におすすめする"音素バランス文"
CC BY-SA 4.0で公開されている、日本声優統計学会の音素バランス文(100文)がおすすめです。
※より高精度を期待したい場合は、500文程度まで増やす必要があります。
balance_sentences/balance_sentences.txt に読み上げ文がありますので、必要に応じて利用してください。
利用の際には 日本声優統計学会 から継承されている CC BY-SA 4.0 にしたがってください。
Z.3.2 第1段のゆかり・自声の収録
下記動画を参照してください。
動画では妥協していますが、『ハモって聞こえる』レベルに合わせるのがベストです
この音声データが精度を左右します!
また、収録したファイル名は先頭に"v-"を付けてください。これを付けないと、後の処理でエラーが出てしまいます。
Yukarinライブラリ用の音声収録方法の紹介
収録は 44100Hz / 16bit で行なっていますが、学習時には 24000Hz / 16bit にリサンプリングします。
(後々、高いサンプリングで学習したい場合があるかもしれないので、収録時は高サンプリングでいいと思います)
ごめんなさい!
以前の記事では、『voiceroid2 などは 44100Hzがデフォルトなので、44100Hz で音声変換すればいい』と、書きましたがあまり適切では無いようです。
人間の音声はほぼ 10000Hz 以下に収まるそうなので、 学習音声のサンプリングはデフォルトの 24000Hzで良さそうです。
(シャノンのサンプリング定義より、24000Hz でサンプリングすれば 12000Hz 以下の音声解析ができます)
Z.3.3 第2段のゆかりボイスの生成
自分は第1段で使ったゆかりボイス + 自分の動画で使った調教済み音声を使用しました(約2時間)。
ヒホ様の issueによると『私はJNASを読ませたものを用いました。』とのことです(約60時間)。
経験則的では、大量にボイスを用意すれば、内容は適当で良さそうです(違ったらごめんなさい)。
Z.4 音声データの配置とリサンプリング
Z.4.1 音声データの配置
Z.4 で収録した音声データをそれぞれ下記のディレクトリに配置してください
- dat/voice_src/voice_44100/yukari_pair/own : Z.4 で収録した第1段の自声
- dat/voice_src/voice_44100/yukari_pair/target : Z.4 で生成した第1段のゆかり音声
- dat/voice_src/voice_44100/yukari_single : Z.4 で生成した第2段のゆかり音声
Z.4.2 ファイル数チェック(チェックサム)
下記の2ディレクトリには、同じ名前で同数のファイルを設置する必要があります。
- dat/voice_src/voice_44100/yukari_pair/own : Z.4 で収録した第1段の自声
- dat/voice_src/voice_44100/yukari_pair/target : Z.4 で生成した第1段のゆかり音声
手戻りが無いように下記コマンドで、ファイル数をチェックします。
./yukarin-tools/count_checker.js -b dat/voice_src/voice_44100/yukari_pair/own -d dat/voice_src/voice_44100/yukari_pair/target
Z.4.3 フォーマットチェック
自作ツールで、wav ファイルのフォーマットをチェックします。
-s でチェックするサンプリングレートを指定します
./yukarin-tools/format_checker.js dat/voice_src/voice_44100/yukari_pair/own -s 44100
./yukarin-tools/format_checker.js dat/voice_src/voice_44100/yukari_pair/target -s 44100
./yukarin-tools/format_checker.js dat/voice_src/voice_44100/yukari_single -s 44100
問題がなければ下記のようなメッセージが表示されます。
./yukarin-tools/format_checker.js dat/voice_src/voice_44100/yukari_single -s 44100
debug : {"src":"dat/voice_src/voice_44100/yukari_pair/own","sampling":44100}
all files format :
> channels : 1
> bits per sample : 16
> encoding : Signed Integer PCM
> sampling : 44100
result : OK
Z.4.4 リサンプリング
収録音声を Yukarinライブラリのデフォルトフォーマット 24000Hz /16 bit に変換します。
-
-bサンプリングする元データディレクトリ -
-dサンプリングしたデータを入れるディレクトリ(念の為、上書きできないようにしています) -
-sでチェックするサンプリングレートを指定します
./yukarin-tools/resampling.js -b dat/voice_src/voice_44100/yukari_pair/own -d dat/voice_src/voice_24000/yukari_pair/own -s 24000
./yukarin-tools/resampling.js -b dat/voice_src/voice_44100/yukari_pair/target -d dat/voice_src/voice_24000/yukari_pair/target -s 24000
./yukarin-tools/resampling.js -b dat/voice_src/voice_44100/yukari_single -d dat/voice_src/voice_24000/yukari_single -s 24000
自声(own)のリサンプリングで下記のような Warnが出るかもしれません。
これは、『ボリュームMAX超えているのがあるけどええんか?』的な、注意です。
アラートで、 5 samplesの部分が 100 samplesとか大きな数字になっていなければ、大丈夫です。
sox WARN rate: rate clipped 5 samples; decrease volume?
sox WARN dither: dither clipped 5 samples; decrease volume?
Z.4.5 リサンプリングのチェック
しつこいですが、リサンプリング結果をチェックします。
./yukarin-tools/format_checker.js dat/voice_src/voice_24000/yukari_pair/own -s 24000
./yukarin-tools/format_checker.js dat/voice_src/voice_24000/yukari_pair/target -s 24000
./yukarin-tools/format_checker.js dat/voice_src/voice_24000/yukari_single -s 24000
Z.5 うっかり削除対策・バックアップ
収録音声など、せっかく作った音声データを削除してしまわないように、データをリードオンリーにします。
念の為、別ストレージへバックアップもおすすめします。
chmod -R 555 dat/voice_src
書き込みできるように戻す場合は下記コマンドを実行してください
chmod -R 755 dat/voice_src
Z.6 環境変数の設定
emacs, vim 等で ~/.bashrc を開き、下記の一行を付け加えてください。
[user_name]の箇所は、アカウントに応じて適宜変更してください。
export PYTHONPATH=/home/[user_name]/deep_yukarin/become-yukarin:/home/[user_name]/deep_yukarin/yukarin
修正後、下記コマンドを実行してください。
このコマンドを実行しないと上記修正が反映されません。
source ~/.bashrc
下記コマンドで、先ほどの設定が表示されるか確認してください。
echo $PYTHONPATH
> /home/[user_name]/deep_yukarin/become-yukarin:/home/[user_name]/deep_yukarin/yukarin
Z.7 ライブラリのインストール
yukarin, become-yukarin に必要なライブラリをインストールします。
pip install world4py
pip install -r become-yukarin/requirements.txt
pip install -r yukarin/requirements.txt
* yukarin のライブラリインストールで、CUDA周りの再インストールされます。
A become-yukarin リポジトリ
A.1 音声の特徴量抽出
become-yukarin の第1段の学習モデル作成は主に dat/1st_models_by/yukarin で作業をします。
第1段の音声ファイルは少ないので、コピーして使うことにします。
cp -r dat/voice_src/voice_24000/yukari_pair dat/1st_models_by/yukari/voice_pair
コピーした音声ファイルから、音声の特徴量を抽出します。
(オプションの解説はしません。各種コマンドオプションは -hを付けて確認してください。 (ex python become-yukarin/scripts/extract_acoustic_feature_arg -h )
python become-yukarin/scripts/extract_acoustic_feature.py \
-i1 dat/1st_models_by/yukari/voice_pair/own \
-i2 dat/1st_models_by/yukari/voice_pair/target \
-o1 dat/1st_models_by/yukari/npy_pair/own \
-o2 dat/1st_models_by/yukari/npy_pair/target
念の為、生成した npyファイルのチェックサムをとる。
./yukarin-tools/count_checker.js -b dat/1st_models_by/yukari/npy_pair/own -d dat/1st_models_by/yukari/npy_pair/target
A.2 第1段の学習(become-yukarin)
学習前に設定ファイルをコピーして書き換えます。
cp become-yukarin/recipe/config.json dat/1st_models_by/yukari/
エディタで config.json を開き
emacs dat/1st_models_by/yukari/config.json
下記の6行を、書き換えてください。
その際、input_glob, target_glob 音声収録をした時のプリフィックス "v-" などを忘れずにしてください。
"input_glob": "dat/1st_models_by/yukari/npy_pair/own/v-*.npy",
"input_mean_path": "dat/1st_models_by/yukari/npy_pair/own/mean.npy",
"input_var_path": "dat/1st_models_by/yukari/npy_pair/own/var.npy",
"target_glob": "dat/1st_models_by/yukari/npy_pair/target/v-*.npy",
"target_mean_path": "dat/1st_models_by/yukari/npy_pair/target/mean.npy",
"target_var_path": "dat/1st_models_by/yukari/npy_pair/target/var.npy",
さらに、GPUを使いための下記の設定をしてください。(cpu -1, gpu 0)
"gpu": 0,
設定が終わったら、下記コマンドで学習を行います。
python become-yukarin/train.py dat/1st_models_by/yukari/config.json dat/1st_models_by/yukari/1st_yukari_model_by
エラーがなければ、predictor_XXXX.npz と言う学習済みファイルが生成されます。
predictor_250000.npz 程度が出力されるのを待ちます(GTX 1070で 7時間ぐらい)。
進捗チェックコマンド
watch -n 60 ls -latr dat/1st_models_by/yukari/1st_yukari_model_by
蛇足
CPU,GPUの温度は以下でチェックできます。
熱暴走にはお気をつけて! (筆者は2回、熱保護でPCをクラッシュさせました)
./yukarin-tools/watch_temperature.sh
A.3 第1段を使った音声変換
音声変換に使う入力・出力ファイルを格納するディレクトリを作成します。
test_data には Z.4.2 で作った学習データとは、違う自声の音声データ(24000Hz / 16bit)を配置します。
mkdir ./test_data
mkdir ./output
mkdir ./output/1st_yukari_model_by
次に、上手く学習できていそうなデータの目星を付けます。
ヒホ様は train.pyの学習数について #10 のように選んでいるそうです。
以下の選び方は我流です。参考までの一例です!
下記で、 5000ステップごとの discriminator/accuracy と discriminator/loss を出力します
./yukarin-tools/log2accuracy.js dat/1st_models_by/yukari/1st_yukari_model_by/log
ここで着目するのは acc(discriminator/accuracy) と loss(discriminator/loss) です。
acc は問題なければ、90% 〜 97% ぐらいまで上がります。
これが 80% 程度から上がっていなければ、学習用音声の質が悪いか、手順にミスがあるかと思います。
経験則では下記のデータが変換精度が高かったです。
- イテレーションが少ない
-
accが大きい -
lossが小さい
下記の結果から、選ぶなら下記 3つほどが候補になります。
(学習回数のイテレーションは大きければ大きいほどいいと言うことはありません。過学習と言う精度が下がる現象が起こります。)
- 145000 :: train > acc : 0.95, loss 0.283 :: test > acc 0.53 ( 4:13:21)
- 180000 :: train > acc : 0.95, loss 0.273 :: test > acc 0.63 ( 5:14:42)
- 220000 :: train > acc : 0.96, loss 0.227 :: test > acc 0.52 ( 6:24:50)
{ acc: 0.85,
skip: 5000,
full: false,
src: 'dat/1st_models_by/yukari/1st_yukari_model_by/log' }
- 15000 :: train > acc : 0.86, loss 0.654 :: test > acc 0.53 ( 0:26:06)
- 25000 :: train > acc : 0.87, loss 0.627 :: test > acc 0.67 ( 0:43:32)
- 30000 :: train > acc : 0.88, loss 0.552 :: test > acc 0.48 ( 0:52:15)
- 35000 :: train > acc : 0.89, loss 0.538 :: test > acc 0.66 ( 1:00:58)
- 40000 :: train > acc : 0.89, loss 0.521 :: test > acc 0.55 ( 1:09:41)
- 45000 :: train > acc : 0.90, loss 0.489 :: test > acc 0.58 ( 1:18:25)
- 50000 :: train > acc : 0.90, loss 0.511 :: test > acc 0.56 ( 1:27:08)
- 55000 :: train > acc : 0.89, loss 0.499 :: test > acc 0.53 ( 1:35:52)
- 60000 :: train > acc : 0.91, loss 0.472 :: test > acc 0.70 ( 1:44:35)
- 65000 :: train > acc : 0.90, loss 0.483 :: test > acc 0.66 ( 1:53:19)
- 70000 :: train > acc : 0.89, loss 0.513 :: test > acc 0.63 ( 2:02:03)
- 75000 :: train > acc : 0.90, loss 0.485 :: test > acc 0.58 ( 2:10:47)
- 80000 :: train > acc : 0.91, loss 0.457 :: test > acc 0.55 ( 2:19:31)
- 85000 :: train > acc : 0.90, loss 0.472 :: test > acc 0.52 ( 2:28:15)
- 90000 :: train > acc : 0.91, loss 0.450 :: test > acc 0.59 ( 2:37:00)
- 95000 :: train > acc : 0.89, loss 0.510 :: test > acc 0.50 ( 2:45:44)
- 100000 :: train > acc : 0.91, loss 0.437 :: test > acc 0.70 ( 2:54:30)
- 105000 :: train > acc : 0.90, loss 0.483 :: test > acc 0.61 ( 3:03:14)
- 110000 :: train > acc : 0.91, loss 0.422 :: test > acc 0.63 ( 3:12:03)
- 115000 :: train > acc : 0.92, loss 0.383 :: test > acc 0.64 ( 3:20:48)
- 120000 :: train > acc : 0.91, loss 0.418 :: test > acc 0.58 ( 3:29:33)
- 125000 :: train > acc : 0.92, loss 0.385 :: test > acc 0.41 ( 3:38:19)
- 130000 :: train > acc : 0.93, loss 0.354 :: test > acc 0.39 ( 3:47:04)
- 135000 :: train > acc : 0.94, loss 0.327 :: test > acc 0.58 ( 3:55:50)
- 140000 :: train > acc : 0.92, loss 0.391 :: test > acc 0.61 ( 4:04:35)
- 145000 :: train > acc : 0.95, loss 0.283 :: test > acc 0.53 ( 4:13:21)
- 150000 :: train > acc : 0.93, loss 0.379 :: test > acc 0.45 ( 4:22:06)
- 155000 :: train > acc : 0.94, loss 0.326 :: test > acc 0.41 ( 4:30:52)
- 160000 :: train > acc : 0.94, loss 0.330 :: test > acc 0.58 ( 4:39:38)
- 165000 :: train > acc : 0.93, loss 0.360 :: test > acc 0.50 ( 4:48:24)
- 170000 :: train > acc : 0.93, loss 0.348 :: test > acc 0.64 ( 4:57:10)
- 175000 :: train > acc : 0.94, loss 0.321 :: test > acc 0.58 ( 5:05:56)
- 180000 :: train > acc : 0.95, loss 0.273 :: test > acc 0.63 ( 5:14:42)
- 185000 :: train > acc : 0.94, loss 0.278 :: test > acc 0.72 ( 5:23:28)
- 190000 :: train > acc : 0.94, loss 0.295 :: test > acc 0.64 ( 5:32:14)
- 195000 :: train > acc : 0.94, loss 0.279 :: test > acc 0.66 ( 5:41:00)
- 200000 :: train > acc : 0.94, loss 0.308 :: test > acc 0.50 ( 5:49:46)
- 205000 :: train > acc : 0.95, loss 0.268 :: test > acc 0.69 ( 5:58:32)
- 210000 :: train > acc : 0.93, loss 0.326 :: test > acc 0.56 ( 6:07:18)
- 215000 :: train > acc : 0.94, loss 0.290 :: test > acc 0.64 ( 6:16:04)
- 220000 :: train > acc : 0.96, loss 0.227 :: test > acc 0.52 ( 6:24:50)
- 225000 :: train > acc : 0.95, loss 0.251 :: test > acc 0.59 ( 6:33:37)
- 230000 :: train > acc : 0.96, loss 0.238 :: test > acc 0.72 ( 6:42:23)
- 235000 :: train > acc : 0.96, loss 0.216 :: test > acc 0.53 ( 6:51:09)
- 240000 :: train > acc : 0.95, loss 0.259 :: test > acc 0.55 ( 6:59:56)
- 245000 :: train > acc : 0.96, loss 0.228 :: test > acc 0.70 ( 7:08:43)
- 250000 :: train > acc : 0.95, loss 0.253 :: test > acc 0.67 ( 7:17:29)
変換の実行は下記コマンドで実行します。
[イテレーション数] には 変換したい数字を入れてください。
python become-yukarin/scripts/voice_conversion_test.py 1st_yukari_model_by \
-iwd dat/1st_models_by/yukari/voice_pair/own \
-md dat/1st_models_by/yukari \
-it [イテレーション数]
成功した場合
-
test_dataのすべての音声データ -
dat/1st_models_by/yukari/voice_pair/ownからランダムに選ばれた音声変換結果
の、変換音声が output/1st_yukari_model_by に保存されます。
生成したwavファイルは VLCなどで、再生してください。MSのメディアプレーヤーでは再生できません。
筆者の変換結果(葵音声)
個人的には predictor_145000.npz が一番いい様に思います。
ちなみに、ヒホ様のデモでは 19万 イテレーションの学習データを使用したそうです(train.pyの学習数について)。
あと、理屈はわかりませんが、音声の後半にノイズ入ります。変換前データの後方の無音時間をカットすれば問題ないと思います。
- predictor_95000.npz
- predictor_145000.npz
- predictor_180000.npz
- predictor_220000.npz
- predictor_235000.npz
A.4 第2段学習
voice ソース から直接参照して(データ数が多いのでコピーしません)、音声特徴量を抽出します。
python become-yukarin/scripts/extract_spectrogram_pair.py \
-i dat/voice_src/voice_24000/yukari_single \
-o dat/2nd_models_by/yukari/npy_single
LLVM ERROR: out of memory 等で、出てハングアップすることがあります。
その時は ctrl + c で処理を中断して、、2回、3回と繰り返すことで、全ての音声を変換できると思います。
変換後、下記コマンドで全ファイルが変換されているかチェックします。
数が合わなければ、上記処理を繰り返しましょう。
./yukarin-tools/count_checker.js -b dat/2nd_models_by/yukari/npy_single -d dat/voice_src/voice_24000/yukari_single
cp become-yukarin/recipe/config_sr.json dat/2nd_models_by/yukari/
A.2 同様に、config_sr.py をコピーして、データ置き、三行修正をします。
batchsizeは GPU Mem 4G なら 1, GPU Mem 8G なら 2
"input_glob": "dat/2nd_models_by/yukari/npy_single/*.npy",
"batchsize": 1
"gpu": 0,
設定が終われば、下記コマンドで学習します。
こちらは、第1段に比べてかなりの時間がかかります。
自分は 100,000イテレーションほどのデータを使用していますが、どの程度が適切なのかはわかりません。
python become-yukarin/train_sr.py \
dat/2nd_models_by/yukari/config_sr.json \
dat/2nd_models_by/yukari/2nd_yukari_model_by
進捗チェックコマンド
watch -n 60 ls -latr dat/1st_models_by/yukari/2nd_yukari_model_by
A.5 第2段を使った音質向上
A.3 で変換したデータを test_data_sr にコピーします。
mkdir test_data_sr
cp output/1st_yukari_model_by/* test_data_sr
python become-yukarin/scripts/super_resolution_test.py 2nd_yukari_model_by/ \
-md dat/2nd_models_by/yukari \
-iwd dat/voice_src/voice_24000/yukari_single
第2段のプレディクターは 2nd_yukari_model_by 内で一番、イテレーションが大きいものが使われます。
変換結果はoutput/2nd_yukari_model_byに出力されます
筆者の変換結果(葵音声)
predictor_145000.npz の第1段音声が割と綺麗に取れているので、差がわかりにくいですが、多少音質がよくなっていると思います。
predictor_145000.npz の第1段に第2段を適用した音声
B. yukarin リポジトリ
yukarinって何が違うの?
現状では、基本リファクタリングがメインで、新規点は 声のピッチを調整が簡単になった とのことです。
また、音声変換の精度も少し変わるようです。
B.1 音声変換のための特徴量抽出
ざっくり言うと、B.1, B.2 の処理は、A.1 を分割しているだけで処理内容はほとんど同じっぽいです。
A.1 同様音声ファイルはコピーして使います。
cp -r dat/voice_src/voice_24000/yukari_pair dat/1st_models_y/yukari/voice_pair
自声の特徴量抽出
python yukarin/scripts/extract_acoustic_feature.py \
-i './dat/1st_models_y/yukari/voice_pair/own/*.wav' \
-o './dat/1st_models_y/yukari/npy_pair/own'
注: readmeの * -> *.wav に変更しているのは安全のため
ゆかりの特徴量抽出
python yukarin/scripts/extract_acoustic_feature.py \
-i './dat/1st_models_y/yukari/voice_pair/target/*.wav' \
-o './dat/1st_models_y/yukari/npy_pair/target'
npyのチェックサム
./yukarin-tools/count_checker.js -b dat/1st_models_y/yukari/npy_pair/own -d dat/1st_models_y/yukari/npy_pair/target
B.2 音響特徴量のアライメント
自声とゆかり音声の微妙なずれを補償する。
python yukarin/scripts/extract_align_indexes.py \
-i1 './dat/1st_models_y/yukari/npy_pair/own/*.npy' \
-i2 './dat/1st_models_y/yukari/npy_pair/target/*.npy' \
-o './dat/1st_models_y/yukari/aligned_indexes/'
B.3 周波数の統計量を求める
声の高さの平均、分散を求める。
この平均値をいじることで、変換後の音声のピッチを調整できるようです。
python yukarin/scripts/extract_f0_statistics.py\
-i './dat/1st_models_y/yukari/npy_pair/own/*.npy' \
-o './dat/1st_models_y/yukari/statistics/own.npy'
python yukarin/scripts/extract_f0_statistics.py\
-i './dat/1st_models_y/yukari/npy_pair/target/*.npy' \
-o './dat/1st_models_y/yukari/statistics/target.npy'
B.4 第1段学習(yukarin)
cp yukarin/sample_config.json ./dat/1st_models_y/yukari/config.json
emacs ./dat/1st_models_y/yukari/config.json で編集
"input_glob": "./dat/1st_models_y/yukari/npy_pair/own/*.npy",
"target_glob": "./dat/1st_models_y/yukari/npy_pair/target/*.npy",
"indexes_glob": "./dat/1st_models_y/yukari/aligned_indexes/*.npy",
python yukarin/train.py \
./dat/1st_models_y/yukari/config.json \
./dat/1st_models_y/yukari/1st_yukari_model_y
学習進行チェックコマンド
watch -n 60 "ls -ltr dat/1st_models_y/yukari/1st_yukari_model_y"
B.5 yukarin での音声変換(第1,2段)
become-yukarin で使用したテストデータを移動させます。
cp test_data/*.wav dat/input/
A.3 同様に音質が良さそうな学習データをピックアップします。
./yukarin-tools/log2accuracy.js dat/1st_models_y/yukari/1st_yukari_model_y/log
yukarinは become-yuakrin に比べて、acc が高めになりました。
- 120000 :: train > acc : 0.98, loss 0.121 :: test > acc 0.57 ( 3:36:31)
- 160000 :: train > acc : 0.98, loss 0.116 :: test > acc 0.57 ( 4:48:56)
- 210000 :: train > acc : 0.98, loss 0.107 :: test > acc 0.65 ( 6:19:33)
{ acc: 0.85,
skip: 5000,
full: false,
src: 'dat/1st_models_y/yukari/1st_yukari_model_y/log' }
- 5000 :: train > acc : 0.95, loss 0.379 :: test > acc 0.51 ( 0:09:00)
- 10000 :: train > acc : 0.97, loss 0.232 :: test > acc 0.59 ( 0:18:01)
- 15000 :: train > acc : 0.97, loss 0.200 :: test > acc 0.52 ( 0:27:03)
- 20000 :: train > acc : 0.97, loss 0.199 :: test > acc 0.56 ( 0:36:03)
- 25000 :: train > acc : 0.98, loss 0.170 :: test > acc 0.57 ( 0:45:04)
- 30000 :: train > acc : 0.98, loss 0.164 :: test > acc 0.57 ( 0:54:05)
- 35000 :: train > acc : 0.98, loss 0.155 :: test > acc 0.63 ( 1:03:07)
- 40000 :: train > acc : 0.98, loss 0.157 :: test > acc 0.59 ( 1:12:09)
- 45000 :: train > acc : 0.98, loss 0.158 :: test > acc 0.56 ( 1:21:09)
- 50000 :: train > acc : 0.98, loss 0.152 :: test > acc 0.57 ( 1:30:09)
- 55000 :: train > acc : 0.98, loss 0.146 :: test > acc 0.52 ( 1:39:10)
- 60000 :: train > acc : 0.98, loss 0.153 :: test > acc 0.66 ( 1:48:11)
- 65000 :: train > acc : 0.98, loss 0.143 :: test > acc 0.54 ( 1:57:11)
- 70000 :: train > acc : 0.98, loss 0.147 :: test > acc 0.57 ( 2:06:13)
- 75000 :: train > acc : 0.98, loss 0.137 :: test > acc 0.62 ( 2:15:15)
- 80000 :: train > acc : 0.98, loss 0.140 :: test > acc 0.57 ( 2:24:16)
- 85000 :: train > acc : 0.98, loss 0.142 :: test > acc 0.61 ( 2:33:18)
- 90000 :: train > acc : 0.98, loss 0.137 :: test > acc 0.50 ( 2:42:20)
- 95000 :: train > acc : 0.98, loss 0.133 :: test > acc 0.68 ( 2:51:22)
- 100000 :: train > acc : 0.98, loss 0.138 :: test > acc 0.56 ( 3:00:23)
- 105000 :: train > acc : 0.98, loss 0.145 :: test > acc 0.68 ( 3:09:25)
- 110000 :: train > acc : 0.98, loss 0.132 :: test > acc 0.71 ( 3:18:27)
- 115000 :: train > acc : 0.98, loss 0.152 :: test > acc 0.64 ( 3:27:29)
- 120000 :: train > acc : 0.98, loss 0.121 :: test > acc 0.57 ( 3:36:31)
- 125000 :: train > acc : 0.98, loss 0.113 :: test > acc 0.58 ( 3:45:35)
- 130000 :: train > acc : 0.98, loss 0.136 :: test > acc 0.59 ( 3:54:38)
- 135000 :: train > acc : 0.98, loss 0.130 :: test > acc 0.63 ( 4:03:41)
- 140000 :: train > acc : 0.98, loss 0.123 :: test > acc 0.63 ( 4:12:45)
- 145000 :: train > acc : 0.98, loss 0.123 :: test > acc 0.60 ( 4:21:48)
- 150000 :: train > acc : 0.98, loss 0.131 :: test > acc 0.60 ( 4:30:51)
- 155000 :: train > acc : 0.98, loss 0.110 :: test > acc 0.63 ( 4:39:53)
- 160000 :: train > acc : 0.98, loss 0.116 :: test > acc 0.57 ( 4:48:56)
- 165000 :: train > acc : 0.98, loss 0.139 :: test > acc 0.56 ( 4:57:59)
- 170000 :: train > acc : 0.98, loss 0.121 :: test > acc 0.59 ( 5:07:01)
- 175000 :: train > acc : 0.97, loss 0.205 :: test > acc 0.61 ( 5:16:05)
- 180000 :: train > acc : 0.98, loss 0.112 :: test > acc 0.62 ( 5:25:08)
- 185000 :: train > acc : 0.98, loss 0.119 :: test > acc 0.64 ( 5:34:12)
- 190000 :: train > acc : 0.98, loss 0.136 :: test > acc 0.64 ( 5:43:15)
- 195000 :: train > acc : 0.98, loss 0.116 :: test > acc 0.73 ( 5:52:19)
- 200000 :: train > acc : 0.98, loss 0.109 :: test > acc 0.59 ( 6:01:23)
- 205000 :: train > acc : 0.99, loss 0.104 :: test > acc 0.61 ( 6:10:28)
- 210000 :: train > acc : 0.98, loss 0.107 :: test > acc 0.65 ( 6:19:33)
- 215000 :: train > acc : 0.98, loss 0.110 :: test > acc 0.66 ( 6:28:38)
- 220000 :: train > acc : 0.98, loss 0.114 :: test > acc 0.65 ( 6:37:42)
- 225000 :: train > acc : 0.99, loss 0.107 :: test > acc 0.68 ( 6:46:46)
- 230000 :: train > acc : 0.98, loss 0.108 :: test > acc 0.60 ( 6:55:51)
- 235000 :: train > acc : 0.98, loss 0.108 :: test > acc 0.70 ( 7:04:54)
- 240000 :: train > acc : 0.99, loss 0.110 :: test > acc 0.74 ( 7:13:58)
- 245000 :: train > acc : 0.98, loss 0.107 :: test > acc 0.63 ( 7:23:03)
変換候補イテレーション
- 120000 :: train > acc : 0.98, loss 0.121 :: test > acc 0.57 ( 3:36:31)
- 160000 :: train > acc : 0.98, loss 0.116 :: test > acc 0.57 ( 4:48:56)
- 210000 :: train > acc : 0.98, loss 0.107 :: test > acc 0.65 ( 6:19:33)
音声変換実行コマンド
第1段学習データ(B.4)の指定は、voice_changer_model_iterationの [イテレーション数] で指定します。
第2段学習データ(A.4)の指定は super_resolution_modelオプションで指定してください。
* 2019/06/11 でコマンド名が変わりました voice_change.py -> voice_change_with_second_stage.py
python yukarin/scripts/voice_change_with_second_stage.py \
--voice_changer_model_dir './dat/1st_models_y/yukari/1st_yukari_model_y' \
--voice_changer_config './dat/1st_models_y/yukari/1st_yukari_model_y/config.json' \
--voice_changer_model_iteration [イテレーション数] \
--super_resolution_model './dat/2nd_models_by/yukari/2nd_yukari_model_by/predictor_100000.npz' \
--super_resolution_config './dat/2nd_models_by/yukari/2nd_yukari_model_by/config.json' \
--input_statistics './dat/1st_models_y/yukari/statistics/own.npy' \
--target_statistics './dat/1st_models_y/yukari/statistics/target.npy' \
--out_sampling_rate 24000 \
--dataset_input_wave_dir './dat/1st_models_y/yukari/voice_pair/own' \
--dataset_target_wave_dir './dat/1st_models_y/yukari/voice_pair/target' \
--test_wave_dir './dat/input' \
--output_dir './dat/output' \
--gpu 0
出力結果
第2段の学習モデルは A.5 と同じものを使用しています。
@AI_Kiritan 様の場合は、変換精度が向上しているようですが、自分はノイズが増えてしまいました。
手順は同じはずなので、学習用音声が yukarin のアルゴリズムにあっていないのかと思います(調査したいところです)。
どんぐりの背比べですが、イテレーション 120000が一番良いかと思います。
自分の場合 サ行、タ行 の発話でノイズになりやすい様です。これは発話の癖なのでしょうか・・・?
サ行の音は「歯擦音(しさつおん)」と呼ばれて、この音はプロのミキサーも、綺麗に聞こえる用に調整するのが難しいそうです。
もしかして、音声変換もしにくい音なのかもしれません。
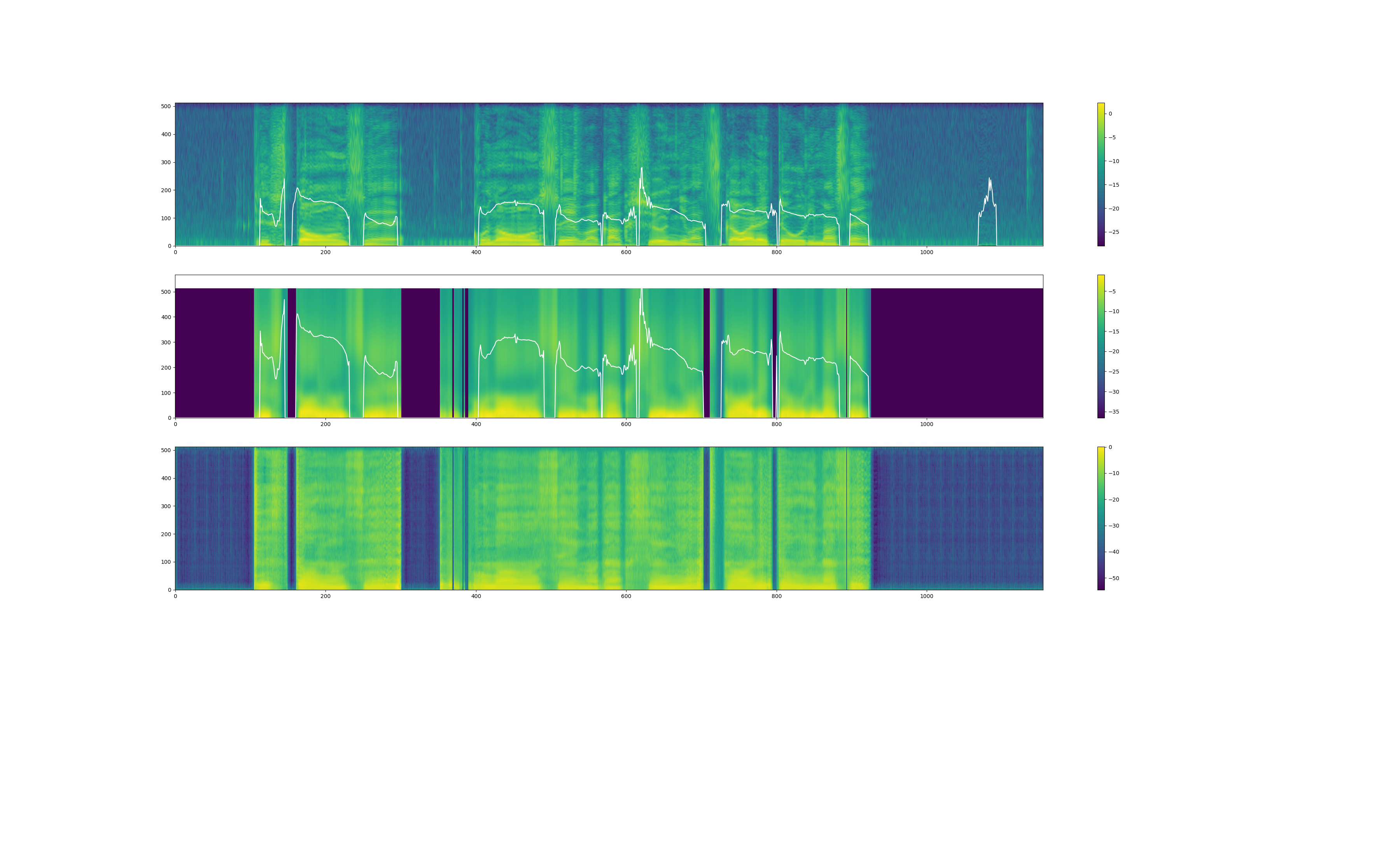
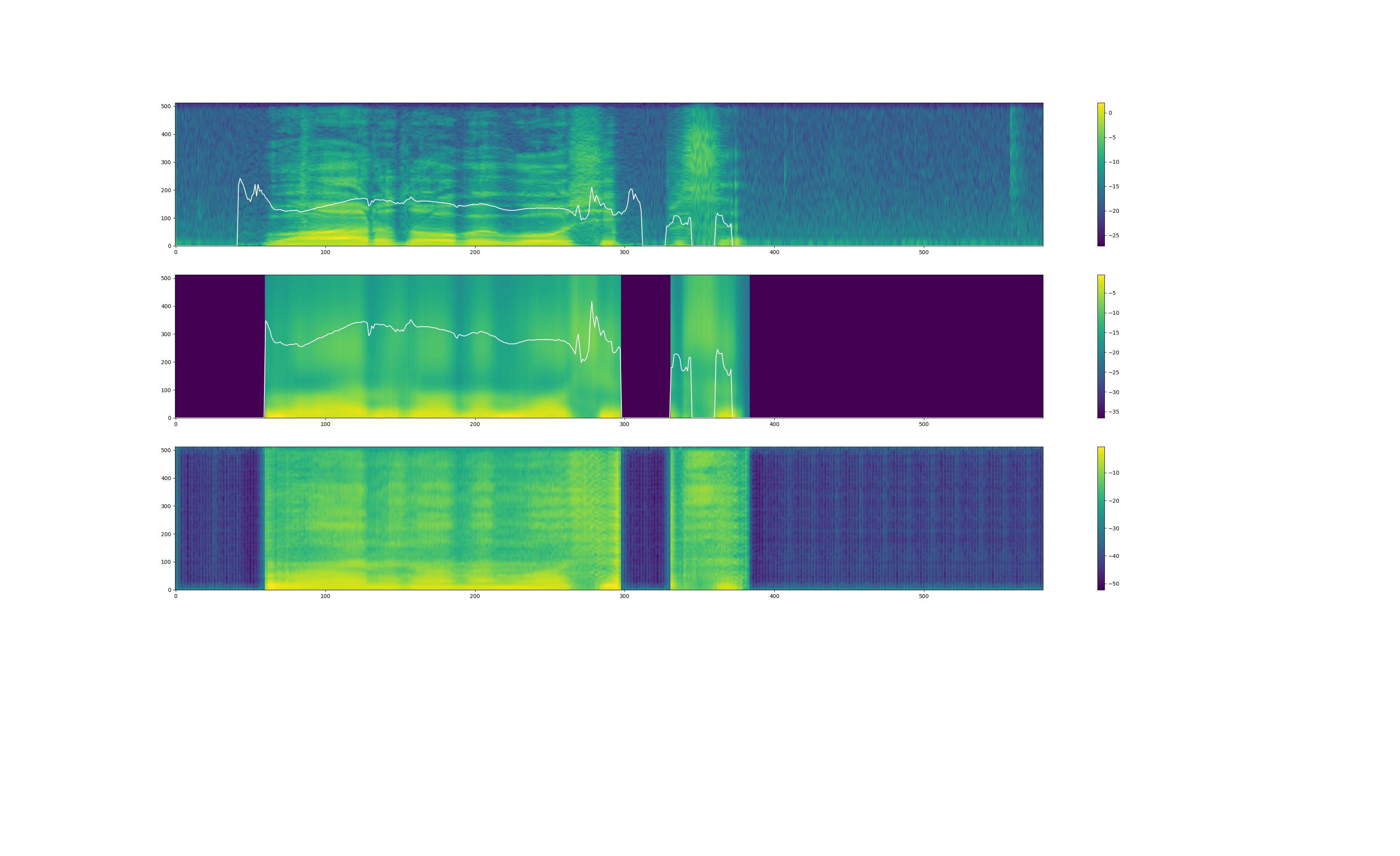
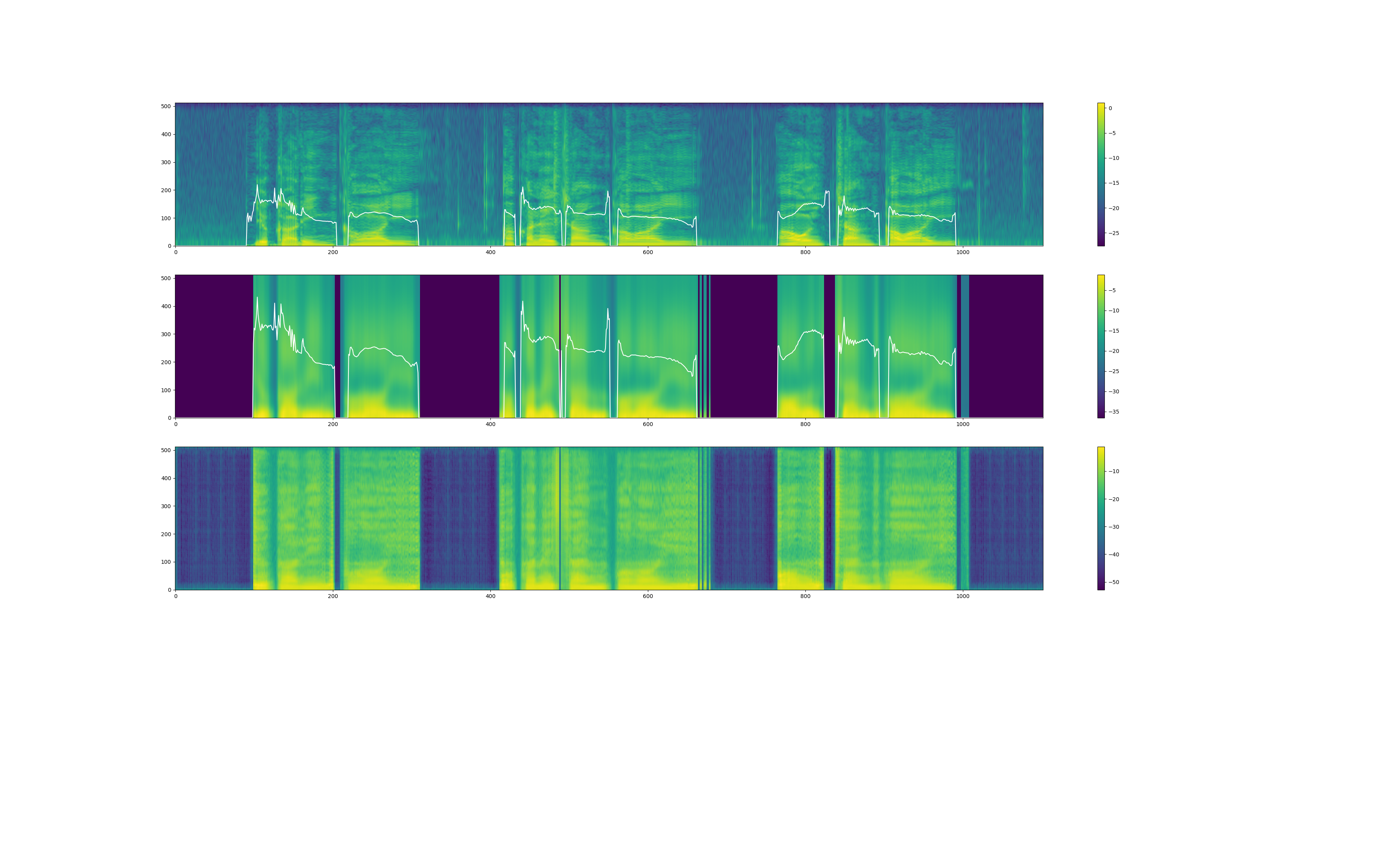
また、yukarin の音声出力時には、変換音声の"スペクトラム" & "f0(基本周波数)" のプロットらしきものが出力されます(まだ詳しく見てないです)。
プロット図(yukarin_120000)
-
test01.png
-
test02.png
-
test03.png
B.6 追記: yukarin での音声変換(第1段のみ)
最新のyukarinリポジトリでは、第1段のみの変換スクリプトが追加されました。
コマンド自体は B.5 から第2段のパラメータを抜いたもで、下記のようなコマンドになります。
python yukarin/scripts/voice_change.py \
--model_dir './dat/1st_models_y/yukari/1st_yukari_model_y' \
--model_iteration [イテレーション数] \
--config_path './dat/1st_models_y/yukari/config.json' \
--input_statistics 'dat/1st_models_y/yukari/statistics/own.npy' \
--target_statistics 'dat/1st_models_y/yukari/statistics/target.npy' \
--output_sampling_rate 24000 \
--test_wave_dir './dat/input' \
--output_dir './dat/output'
終わりに
realtime-yukarin は B.5 のコマンドと同じ要領で実行できます。(readmeを見るだけで済むと思うので、記事にしないと思います)
はやり、リアルタイムで音声変換するのは夢ですよね!
よくわからないところが、あればコメントよろしくお願いします!
それでは、良い音声変換ライフを!