機械学習を使って、人間対機械で対局可能なリバーシを作りました。

前提
環境
- Unity 2019.4.11f1 (LTS)
- ML Agents 1.3.0 (Preview)
- ML Agents Extension 0.0.1 (Preview)
- Anaconda Python 3.8
- Windows 10
記事の範囲
- ML-Agentsをターン制ゲームへ応用できることを実証します。
- 具体的には、人間対機械で対局可能なリバーシを作成します。
- 参考
- ML-Agents のセルフプレイを使用したインテリジェントな対戦相手のトレーニング (公式 Unity Blog)
- リバーシの戦術については、この記事では扱いません。
- 筆者は、今回初めてリバーシのルールを正確に把握しました。
- セオリーとして知っているのは四隅や四辺を取ると有利という程度のド素人です。
- ML-Agentsの基礎については、この記事では扱いません。
- 下敷きとなる記事 ⇒ 「Unity ML-Agentsを試してみた」
- リソースについても、上の記事を参照してください。
アセットの入手
- ダウンロード ⇒ mla-Reversi.zip (GitHub)
- 下記リポジトリの一括ダウンロードです。
- リポジトリ ⇒ mla-Reversi (GitHub)
- プロジェクトの全てのソースとUnityの設定ファイルやトレーニングの構成ファイルを含みます。
- Android App ⇒ AI-Reversi (Google Play)
- 人間対機械で対局できるようにAndroid向けにビルドしただけのものです。
- 広告、アナリティクス、必要な権限などはありません。
このプロジェクトで扱うリバーシのルール
- 8×8マスの正方形の盤を使用して、黒と白に分かれ石を交互に置いていきます。
- 黒が先手です。
- 盤中央には、あらかじめ、各色2個(計4個)の石を市松配置で置いておきます。
- 新たに置かれる石と同色の石に直線上で挟まれた他色の石は色が反転します。
- 縦横斜め方向に複数同時に挟むことができます。
- 挟んで反転可能な石のあるマスにしか石を置けません。
- 置けるマスがない場合は手番がパスされて相手の手番になります。
- 両者とも石が置けるマスがなくなったら終局となり、色の多い方が勝者となります。
学習環境の設計
- マスの基礎状態として「空、黒、白」の3値を正規化し、8×8=64マスをリニアに並べて(0~63)観測させます。
- マスの状態を5値(空、黒、白、黒可、白可)として観測させる方法も考えられます。
- 離散アクションスペースとして、石を置くマスのリニアインデックス(0~63)を使います。
- ルール的に置けないマスをマスクして、行動の無駄を省きます。
- 行動を制限せず、置けないマスを選んだらマイナス報酬を与えて、ルールから学習させる方法も考えられます。
- 一手ごとに微かな報酬を加え、勝利した場合は最大報酬、敗北した場合は最低報酬に置き換えます。
- 「強化学習の報酬は、結果に対して与える」ものなので、取ったマスの価値や一時的なスコアは考慮しません。
アプリの概略設計
目的
- ML-Agentsのターン制ゲームへの応用を検証します。
- そのため、ユーザを楽しませるための機能は実装しません。(リバーシの対局自体は楽しめます。)
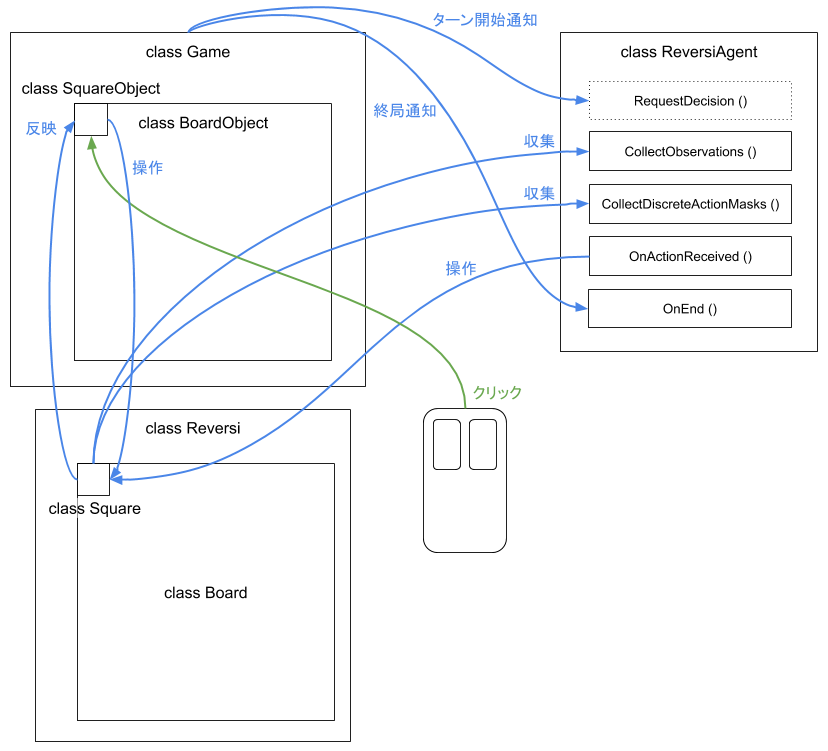
クラス構成
- 論理層
namespace ReversiLogic- 論理ゲーム
class Reversi- 論理盤面の制御、ターンの制御、対局の制御
- 論理盤面
class Board- 論理マスの制御、マスの状態(空、黒、白、黒可、白可)の判定、局面(黒可、白可、終局)の判定、ルールの制御
- 論理マス
class Square- マスの基礎状態(空、黒、白)の制御、石を設置した順序の記録
- 論理ゲーム
- 物理層
namespace ReversiGame- ローダー
class Loader- 物理ゲームの構築と制御、モードの制御、コマンドラインの処理
- 物理ゲーム
class Game- 物理盤面の構築と制御、ゲームの制御、エージェントとの通信
- 物理盤面
class BaordObject- 物理マスの構築と制御、ステータス表示、オプションUIの制御
- 物理マス
class SquareObject- 論理マス状態の表示、クリックの受付
- 確認ダイアログ
class Confirm- 再初期化などの確認UIの制御
- リバーシエージェント
class ReversiAgent-
Unity.MLAgents.Agentsのサブクラス
-
- ローダー
段階的な実装
- 論理層を実装して、ログ出力によって動作を確認します。
- 物理層を実装して、論理層の挙動をゲーム画面で確認可能にします。
- 物理層を拡張して、人間対人間プレイの挙動を確認可能にします。
- エージェントを実装して、機械対機械プレイを可能にします。
- 学習を実施します。
- 学習結果を取り込んで、人間対機械プレイを可能にします。
- スコアの表示や手番の選択など、人間対機械プレイ用のUIを整備します。
- 思考の練度を評価し、トレーニングの構成を試行錯誤します。
1~7は1日でできましたが、8は際限なくかかります。
実装された仕様
機能
- 人間対機械(プレイモード)と機械対機械 (トレーニングモード)のみで、相手を選択するUIはありません。
- 起動時にモードを切り替えられます。 (コマンドライン引数)
- 内部機構的には人間対人間も可能です。 (エージェントのパラメータを双方とも
BehaviorType.HeuristicOnlyに固定)
- プレイモード
- 先手/後手の選択が可能です。 (UIで選択)
- 次にコマの置けるマスと、コマを置いた順番が表示可能です。 (UIで切り替え)
- 「待った」が可能です。
- トレーニングモード
- 画面を更新しません。 (UIで切り替え)
- 起動時に使用する盤面数を指定できます。 (コマンドライン引数)
- 次の手番、最後に置いたコマ、現在のコマ数、累積勝敗数が随時表示されます。
- 勝敗数が蓄積されます。
- 「黒と白」、「人間と機械」、「チームの別」が独立して記録され、状況に合わせた一つが表示されます。
- 3種全てを確認可能です。(UIで切り替え)
- 「黒と白」、「人間と機械」、「チームの別」が独立して記録され、状況に合わせた一つが表示されます。
- 局面や棋譜のセーブはできません。
コマンドライン引数
-
-trainer- トレーニングモードで起動します。デフォルトはプレイモードです。
-
-player- プレイモードで起動します。デフォルトはプレイモードです。
- デフォルトを変更しない限り不要です。
-
-width <整数>- トレーニング時に横に並べる盤面の数です。デフォルトは
7です。
- トレーニング時に横に並べる盤面の数です。デフォルトは
-
-height <整数>- トレーニング時に縦に並べる盤面の数です。デフォルトは
7です。
- トレーニング時に縦に並べる盤面の数です。デフォルトは
-
-change- トレーニング時に一局毎の手番の切り替えを行います。デフォルトは切り替えます。
- デフォルトを変更しない限り不要です。
-
-fix- トレーニング時に手番を固定します。デフォルトは切り替えます。
なお、エディタでトレーニングする場合のために、TRAINER_TESTシンボルで、コマンドライン引数のシミュレーションが可能です。
思考の評価
- 私は、勝てることもありますが、負け越してます。(弱すぎて評価不能)
- 複数の難易度が選べる無料アプリと対局させたところ、最弱レベルに辛勝する程度でした。(弱い)
制御機構概要
チーム
- 対称な二系統の独立した行動決定が必要になるので、エージェントのインスタンスを二つ実装します。
-
TeamIDは、一方を0、他方を1に設定します。
-
先手、後手
- デフォルトで、エージェント
0を白(後手)、エージェント1を黒(先手)に割り当てます。 - プレイモードでは、人間がプレイする色を担当するエージェントの
BehaviorParameters.BehaviorTypeをHeuristicOnlyに、他方をInferenceOnlyに設定します。 - トレーニングモードでは、
BehaviorParameters.BehaviorTypeは双方ともInferenceOnlyになります。- 先手・後手を交代する場合は、二つのエージェントの担当色を入れ替えます。
- 両者とも人間(
HeuristicOnly)の場合は、ML-Agentsは何もしません。- 単一のマウスクリックが局面に応じた手番の行動として扱われるため区別は不要です。
ターン
- 物理ゲームの
Update ()で、ターンを回します。- 「物理ゲーム」コンポーネントは、一種のステートマシンを構成していて、以下は「プレイ中」ステータスの場合の処理です。
- 前のターンを担ったエージェントが処理を終えて担当から外れる(
TurnAgent == null)まで待ちます。 - 局面をチェックして終局していたら、「プレイ中」ステータスを終えて「終局」へ移行します。
- 次のターンを担うエージェントを算定して担当者に設定します。
TurnAgent = IsBlackTurn ? BlackAgent : WhiteAgent;
- ターンの担当エージェントに行動決定を要求します。
- 要求を受けてエージェント側で観測と行動が順次行われます。(学習サイクル)
- ターンの全ての処理が終了すると自ら担当を外れます。
game.TurnAgent = null;
マスと盤面
- 盤面は8×8マスのマトリクスですが、リニアに0~63のインデックスでもアクセスできるようにしています。
- 個々のマスは、石がない、黒石がある、白石があるという3種の基礎状態があり、石がない場合には、石は置けない、黒石が置ける、白石が置ける、黒石でも白石でも置けるという4種の拡張状態が存在します。
- また、盤面全体の状態として、終局、黒石が置ける、白石が置ける、黒石でも白石でも置けるという4種の状態が存在します。
- さらに、盤面には、白黒どちらのターンであるかという情報が存在します。
- 黒のターンで黒石が置けないなら、黒はパスすることになります。
エージェントのコードと解説
学習サイクル
- ターンが廻ってきたエージェントにゲーム制御側から決定要求
RequestDecision ()が届きます。 - エピソード(=対局)が開始されていない場合、エピソードの開始
OnEpisodeBegin ()が呼ばれます。 - 環境の観測
CollectObservations ()が呼ばれ、マスの状態がスキャンされます。 - 行動のマスク
CollectDiscreteActionMasks ()が呼ばれ、ルール上選択できない行動がマスクされます。 - 行動の割り当て
OnActionReceived ()が呼ばれ、石を置くかパスします。- 行動に応じた一時報酬を与えます。
- 終局するとゲーム制御側から
OnEnd ()が呼ばれます。- 結果に応じた最終報酬を与えます。
- エピソードの終結
EndEpisode ()を行います。
class ReversiAgent リバーシ・エージェント
- これは、リバーシの思考を担う
Agentのサブクラスです。-
AgentはMonoBehaviourのサブクラスです。
-
- 一つの物理ゲームに、黒と白を担当する二つの
ReversiAgentインスタンスが作られます。 - 本来は、エージェント自身がゲームの進行を制御するのでしょうが、このプロジェクトでは外部で進行が制御され、エージェントは思考のみを担うようになっています。
ReversiAgent.cs
using System.Collections.Generic;
using System;
using UnityEngine;
using Unity.MLAgents;
using Unity.MLAgents.Sensors;
using Unity.MLAgents.Policies;
using ReversiLogic;
namespace ReversiGame {
/// <summary>リバーシ・エージェント</summary>
public class ReversiAgent : Agent {
/// <summary>チーム識別子</summary>
public enum Team {
Black = 1,
White = 0,
}
/// <summary>盤面のマス数</summary>
private const int Size = ReversiLogic.Board.Size;
/// <summary>物理ゲーム</summary>
private Game game = null;
/// <summary>論理ゲーム</summary>
private Reversi reversi => game.Reversi;
/// <summary>挙動パラメータ</summary>
private BehaviorParameters Parameters => _parameters ?? (_parameters = gameObject.GetComponent<BehaviorParameters> ());
private BehaviorParameters _parameters;
/// <summary>チームID</summary>
public int TeamId => Parameters.TeamId;
/// <summary>チームカラー</summary>
public Team TeamColor { get; private set; }
/// <summary>黒である</summary>
public bool IsBlack => TeamColor == Team.Black;
/// <summary>白である</summary>
public bool IsWhite => TeamColor == Team.White;
/// <summary>自分が優勢</summary>
public bool IWinner => (TeamColor == Team.Black && reversi.BlackWin) || (TeamColor == Team.White && reversi.WhiteWin);
/// <summary>自分が劣勢</summary>
public bool ILoser => (TeamColor == Team.Black && reversi.WhiteWin) || (TeamColor == Team.White && reversi.BlackWin);
/// <summary>VectorAction Branch 0 Size</summary>
public bool Passable => Parameters.BrainParameters.VectorActionSize [0] > Size * Size;
/// <summary>挙動タイプ</summary>
public BehaviorType BehaviorType {
get => Parameters.BehaviorType;
set => Parameters.BehaviorType = value;
}
/// <summary>人間が操作</summary>
public bool IsHuman {
get => (Parameters.BehaviorType == BehaviorType.HeuristicOnly);
set {
if (reversi.Step == 0 || reversi.IsEnd) {
Parameters.BehaviorType = value ? BehaviorType.HeuristicOnly : BehaviorType.InferenceOnly;
}
}
}
/// <summary>機械が操作 (推論時のみ)</summary>
public bool IsMachine {
get => (Parameters.BehaviorType != BehaviorType.HeuristicOnly);
set {
if (reversi.Step == 0 || reversi.IsEnd) {
Parameters.BehaviorType = value ? BehaviorType.InferenceOnly : BehaviorType.HeuristicOnly;
}
}
}
/// <summary>トレーニング中の可能性が高い</summary>
public bool IsTraning => Parameters.BehaviorType == BehaviorType.Default;
/// <summary>チームカラーの入れ替え (チームIDは変更しない)</summary>
public bool ChangeTeam () {
if (reversi.Step == 0 || reversi.IsEnd) {
TeamColor = (TeamColor == Team.Black) ? Team.White : Team.Black;
return true;
}
return false;
}
/// <summary>人間と機械の入れ替え</summary>
public bool ChangeActor () {
if ((reversi.Step == 0 || reversi.IsEnd) && Parameters.BehaviorType != BehaviorType.Default) {
Parameters.BehaviorType = (Parameters.BehaviorType == BehaviorType.HeuristicOnly) ? BehaviorType.InferenceOnly : BehaviorType.HeuristicOnly;
return true;
}
return false;
}
/// <summary>オブジェクト初期化</summary>
private void Awake () => Init ();
/// <summary>初期化</summary>
public void Init () {
if (!game) { // 一度だけ
game = GetComponentInParent<Game> ();
TeamColor = (Team) TeamId;
}
}
/// <summary>エピソードの開始</summary>
public override void OnEpisodeBegin () {
Debug.Log ($"OnEpisodeBegin ({TeamColor}): step={reversi.Step}, turn={(reversi.IsBlackTurn ? "Black" : "White")}, status={reversi.Score.Status}");
if (reversi.Step > 0 && game.State == GameState.Play) { Debug.LogError ("Not Reseted"); }
}
/// <summary>環境の観測</summary>
public override void CollectObservations (VectorSensor sensor) {
Debug.Log ($"CollectObservations ({TeamColor}): step={reversi.Step}, turn={(reversi.IsBlackTurn ? "Black" : "White")}, status={reversi.Score.Status}");
var statuses = new float [Size * Size];
for (var i = 0; i < Size * Size; i++) {
//statuses [i] = (float) reversi [i].Status; // 正規化なし、基本
statuses [i] = (float) reversi [i].Status / (float) SquareStatus.MaxValue; // 正規化あり、基本
//statuses [i] = (float) reversi.SquareStatus (i) / (float) SquareStatus.MaxValue; // 正規化あり、拡張
}
sensor.AddObservation (statuses);
}
/// <summary>行動のマスク</summary>
public override void CollectDiscreteActionMasks (DiscreteActionMasker actionMasker) {
Debug.Log ($"CollectDiscreteActionMasks ({TeamColor}): step={reversi.Step}, turn={(reversi.IsBlackTurn ? "Black" : "White")}, status={reversi.Score.Status}");
var actionIndices = new List<int> { };
for (var i = 0; i < Size * Size; i++) {
var status = reversi.SquareStatus (i);
if ((IsBlack && !status.BlackEnable ()) || (IsWhite && !status.WhiteEnable ())) { // 自分が置けない場所
actionIndices.Add (i);
}
}
if (Passable && reversi.TurnEnable) { // 打てるならパスできない
actionIndices.Add (Size * Size);
}
actionMasker.SetMask (0, actionIndices);
}
// 例外
public class AgentMismatchException : Exception { }
public class TeamMismatchException : Exception { }
/// <summary>行動と報酬の割り当て</summary>
public override void OnActionReceived (float [] vectorAction) {
Debug.Log ($"OnActionReceived ({TeamColor}) [{vectorAction [0]}]: step={reversi.Step}, turn={(reversi.IsBlackTurn ? "Black" : "White")}, status={reversi.Score.Status}");
if (IsMachine) {
var index = Mathf.FloorToInt (vectorAction [0]); // 整数化
if (index == Size * Size) { index = -1; } // パス
try {
if (game.TurnAgent != this) throw new AgentMismatchException (); // エージェントの不一致
if ((reversi.IsBlackTurn && TeamColor != Team.Black) || (reversi.IsWhiteTurn && TeamColor != Team.White)) throw new TeamMismatchException (); // 手番とチームの不整合
if (reversi.Enable (index)) {
game.Move (index);
Debug.Log ($"Moved ({TeamColor}) [{index}]: step={reversi.Step}, turn={(reversi.IsBlackTurn ? "Black" : "White")}, status={reversi.Score.Status}");
AddReward ((index < 0) ? -0.0006f : -0.0003f); // パス、通常
} else {
Debug.LogWarning ($"DisableMove ({TeamColor}) [{index}]: step={reversi.Step}, turn={(reversi.IsBlackTurn ? "Black" : "White")}, status={reversi.Score.Status}\n{reversi}");
AddReward (-0.001f); // 置けない
}
} catch (AgentMismatchException) {
EndEpisode ();
Debug.LogError ($"Agent mismatch ({TeamColor}): Step={reversi.Step}, Turn={(reversi.IsBlackTurn ? "Black" : "White")}, Status={reversi.Score.Status}\n{reversi}");
} catch (TeamMismatchException) {
EndEpisode ();
Debug.LogWarning ($"Team mismatch ({TeamColor}): Step={reversi.Step}, Turn={(reversi.IsBlackTurn ? "Black" : "White")}, Status={reversi.Score.Status}\n{reversi}");
} finally {
game.TurnAgent = null; // 要求を抹消
}
} else {
Debug.LogError ($"{TeamColor}Agent is not Human: step={reversi.Step}, turn={(reversi.IsBlackTurn ? "Black" : "White")}, status={reversi.Score.Status}");
}
}
/// <summary>終局処理と最終的な報酬の割り当て</summary>
public void OnEnd () {
Debug.Log ($"AgentOnEnd ({TeamColor}, {(IWinner ? "winner" : ILoser ? "loser" : "draw")}): step={reversi.Step}, turn={(reversi.IsBlackTurn ? "Black" : "White")}, status={reversi.Score.Status}");
if (IsMachine) {
if (IWinner) {
SetReward (1.0f); // 勝利報酬
} else if (ILoser) {
SetReward (-1.0f); // 敗北報酬
} else {
SetReward (0f); // 引き分け報酬
}
EndEpisode ();
} else {
Debug.LogError ($"{TeamColor}Agent is not Human: step={reversi.Step}, turn={(reversi.IsBlackTurn ? "Black" : "White")}, status={reversi.Score.Status}");
}
}
}
}
using ReversiLogic; 論理ゲーム
- これは、論理ゲームの名前空間です。
-
class Reversi、class Board、class Squareなどが含まれます。 - ここに含まれるクラスは
MonoBehaviourを継承せず、Unityに依存しません。
-
- リバーシのルールや盤面の状態などは、全てこの中にあります。
namespace ReversiGame 物理ゲーム
- これは、物理ゲームの名前空間で、画面表示とUIが含まれます。
-
class Loader、class Game、class Board、class Squareなどが含まれます。 - ここに含まれるクラスは
MonoBehaviourを継承したUnityコンポーネントです。
-
enum TeamColor チーム識別子
- ML-Agentsでは、複数のチームに分かれて対戦や対局が可能なように、エージェントの挙動パラメータに
TeamIdという整数値があります。 - このプロジェクトでは、黒のチームと白のチーム(各ひとつのエージェント)があります。
- トレーニング時、先手と後手それぞれの担当エージェントの
TeamIdは固定されています。これは、バックエンド側で担当チームの交代が行われることを前提にしているためです。
- トレーニング時、先手と後手それぞれの担当エージェントの
- これは、
TeamIdの数値に合わせたシンボルです。
bool Passable パス可能
- 行動が64種の場合は自身でパスができませんが、65種の場合は「パス可能」と判定されます。
-
BehaviorParameters.BrainParametersを参照して、ActionSpace0のサイズを確認しています。 - パス不能の場合は、外部でパスを制御されます。
ChangeTeam () チームカラーの入れ替え (チームIDは変更しない)
- これは、先手と後手(黒と白)を交代する仕組みのひとつで、
TeamIdの担当する色を入れ替えます。- 「エージェント0 = 白担当、エージェント1 = 黒担当」⇒「エージェント0 = 黒担当、エージェント1 = 白担当」
-
TeamIdとTeamColorが一致しない状態が生じます。
- 機械対機械の場合は、一局毎に先手後手を入れ替えています。
ChangeActor () 人間と機械の入れ替え
- これは、人間と機械の担当する色を入れ替える仕組みで、エージェントの挙動タイプを入れ替えます。
- 「エージェント黒 = 人間担当、エージェント白 = 機械担当」⇒「エージェント黒 = 機械担当、エージェント白 = 人間担当」
- エージェントの挙動タイプは、人間操作(
HeuristicOnly)、機械推論(InferenceOnly)、機械学習(と推論の自動切り替えDefault)の別です。
Init () 初期化
- 一度だけ必要な初期化を行います。
- 外部からの使用前に明示的に呼んでいますが、一応、
Awake ()からも呼ばれます。
OnEpisodeBegin () エピソードの開始
- このプロジェクトでの「エピソード」は「一局」に相当します。
- 開始していない状態で、行動の決定を要求(
RequestDecision ())されると、最初に呼び出されます。 - あるいは、エピソードの終了(
EndEpisode ())を行うと中で呼ばれます。 - 本来はここでゲームを初期化するのですが、このプロジェクトは外部で初期化するため、チェックを行うのみで何もしていません。
CollectObservations () 環境の観測
- 行動の決定を要求(
RequestDecision ())される毎に呼ばれます。 - 単純に盤面の8×8マスの石の配置状態を観測させます。
CollectDiscreteActionMasks () 行動のマスク
- 環境の観測後に呼ばれ、選択不能な行動の選択肢をエージェントに示唆します。
- ここでは、ルール上、石を置けないマスをマスクしています。
- パス可能の場合は、石が置けるマスが存在する場合にパスをマスクしています。
OnActionReceived () 行動と報酬の割り当て
- 決定された行動に基づいて実際に石を打ち、その結果に応じた報酬を出します。
- このプロジェクトでは、行動(一手)は単一のスカラー値、中身はマスのインデックス(
(int) 0~63)、または、それに加えて「パス」((int) 64)で表されます。 - 行動を整数値で生成するために、エージェントの挙動パラメータ
VectorAction SpaceTypeに対してDiscreteを指定しています。 - 処理のほとんどはエラーチェックで、作用としては、決定された行動「石を置く位置(マスのインデックス)」または「パス(
-1)」を論理ゲームに渡し、微量の継続報酬を加算するだけです。- この継続報酬は、終局に至ると上書きされて捨てられます。
- 本来は、終局の判定と勝敗に対する報酬の支払い、エピソードの終了などを、ここで処理するのですが、このプロジェクトでは
OnEnd ()に分離しています。- 人間の操作を外部で受け付けて処理している関係で、独立して呼び出せるようにしてあります。
OnEnd () 終局処理と最終的な報酬の割り当て
- 本来は、
OnActionReceived ()の中で行われる処理ですが、人間の操作を外部で受け付けて処理している関係で分離されています。 - 終局を判定した際に外部から呼び出されます。
- ここでの報酬は、それまでの報酬を上書きして、単純に勝てば
1、負ければ-1になります。
Heuristic () 人間の入力
- このプロジェクトでは、このメソッドを実装しません。
- 人間の操作は、エージェントの外で制御されています。
- ML-Agentsに依存して人間の選択が必要な状況になるとエラーが生じます。
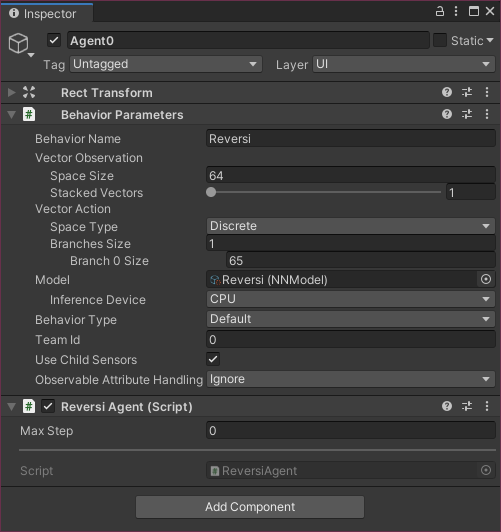
ReversiAgentのBehaviorParameters
トレーニングの構成
次の記事 ⇒ Unity ML-Agentsで作ったターン制ゲームを鍛える (Qiita)
課題
以下のような課題が生じ、対処済み、あるいは、対処中です。
トレーニング時にブレインに接続できない
- Windows版の実行ファイルをビルドしてトレーニングする際に、'Instructions for updating: ~ non-resource variables are not supported in the long term'の後、
Connected to Unity environmentが出ず、UnityEnvironment worker 0: environment stopping.と出て終わってしまいます。
対処
- ProjectSettings>Playerで、
ScriptingBackendをデフォルトのMonoにしておけば接続できるようです。
脈略なくOnEpisodeBegin ()が呼ばれる
-
学習サイクルの途中で、ML-Agentsのバックエンド側からの制御で
OnEpisodeBegin ()が呼ばれる場合があります。- 既に
RequestDecision ()が行われていると、過去のエピソードに対するOnActionReceived ()が呼ばれます。 - 盤面の初期化後に、過去の局面に対しての行動要求が届くので、不整合が生じます。
- 既に
対処
-
config.yamlのthreadedをfalseにすれば、学習サイクル中の割り込みはなくなります。
弱い
- 私が勝てるのだから弱いのは間違いありません。
対処
-
TensorBoardでモニターしています。 - トレーニングの構成を見直しています。