こんにちは、データサイエンティストの島田です。今回は文章のベクトル化についてお話しようと思います。
実行環境
- Python 3.6.7
- Janome==0.3.6
- scikit-learn==0.20.1
- nltk==3.4
タスク設定
日本語の短い文章から分類問題や回帰問題を解く以下のようなタスクを想定しています。いずれも自然言語を入力として、機械学習を用いて処理できそうなタスクです。
- 映画のレビューから映画の評価を予測する
- Twitterの文章から感情の分類を推定する
- 商品名から商品カテゴリを推定する
自然言語を入力とする機械学習の流れ
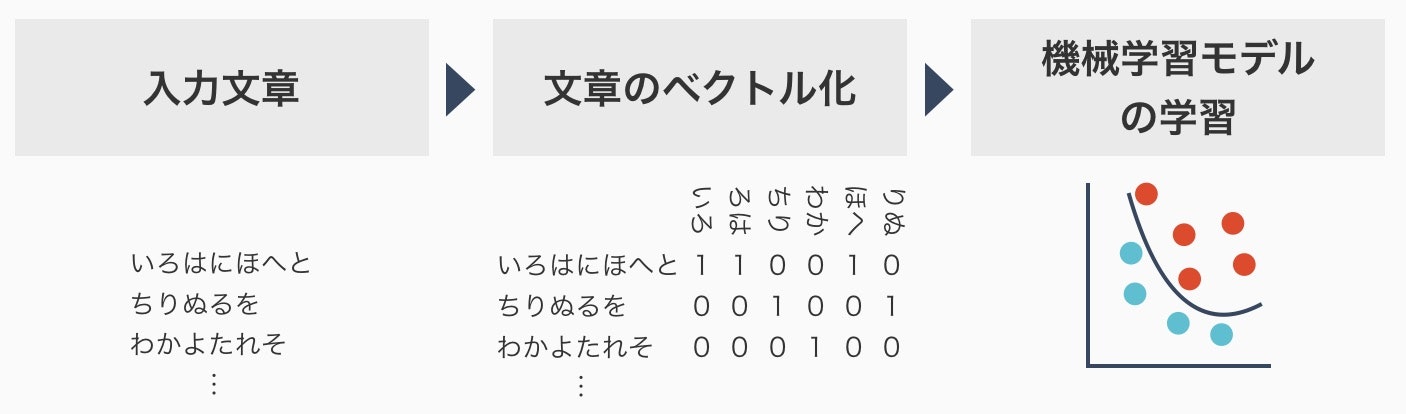
たとえば、「久しぶりに映画で感動しました」という文章があった場合に、これはそのままでは機械学習モデルの入力とすることはできません。機械学習モデルは基本的にベクトル化されたデータが入力されることを期待しています。では、文章をベクトル化するとはどういうことなのでしょうか?
形態素解析による文章のベクトル化
日本語の自然言語処理を調べると、「形態素解析」という言葉に行き当たると思います。さっそく形態素解析を実行してみましょう。今回は、形態素解析エンジンの一つであるjanomeを使用したいと思います。インストールはpip install janomeで実行できます。
形態素解析がうまくいく場合
形態素解析の実行
試しに、「久しぶりに映画で感動しました」という文章を形態素解析してみましょう。
from janome.tokenizer import Tokenizer
t = Tokenizer()
s = '久しぶりに映画で感動しました'
for token in t.tokenize(s):
print(token)
実行結果を見てみると、区切られた単語と共に、品詞や活用、フリガナなどが得られます。区切られた単語を得ることが文章のベクトル化に必要です。本当は、形態素解析に伴って正規化1やストップワード2の設定が必要ですが今回は省略します。
久しぶり 名詞,一般,*,*,*,*,久しぶり,ヒサシブリ,ヒサシブリ
に 助詞,格助詞,一般,*,*,*,に,ニ,ニ
映画 名詞,一般,*,*,*,*,映画,エイガ,エイガ
で 助詞,格助詞,一般,*,*,*,で,デ,デ
感動 名詞,サ変接続,*,*,*,*,感動,カンドウ,カンドー
し 動詞,自立,*,*,サ変・スル,連用形,する,シ,シ
まし 助動詞,*,*,*,特殊・マス,連用形,ます,マシ,マシ
た 助動詞,*,*,*,特殊・タ,基本形,た,タ,タ
文章のベクトル化
得られた形態素をベクトル化します。今回はscikit-learnのCountVectorizerを使用し、各単語の出現回数を数えるBag of Words3を使ってベクトル化します。scikit-learnはpip install scikit-learnでインストールできます。文章を分かち書き(単語の区切りに空白を挟んで記述すること)された状態にした上で、CountVectorizerに入力します。今回は、3つの文章を入力してみましょう。
from janome.tokenizer import Tokenizer
from sklearn.feature_extraction.text import CountVectorizer
t = Tokenizer()
s_list = [
'久しぶりに映画で感動しました',
'こんなに感動した映画は久しぶりです',
'アクションシーンが見物です'
]
# 分かち書きされた文章に変換する
# リストを返すと大量の文章ではメモリに載らない可能性があるため、
# 実装の際にはgeneratorにするようにした方が良いです
def tokenize(text):
tokens = [token.surface for token in t.tokenize(text)]
return ' '.join(tokens)
tokenized_list = [tokenize(text) for text in s_list]
# 分かち書きされた文章からベクトルを得る
cv = CountVectorizer()
matrix = cv.fit_transform(tokenized_list)
print(cv.get_feature_names())
# 得られるベクトルはscipyのsparse matrixです
# 可視化のためにdense matrixにしていますが、後続のモデルがsparse matrixでOKの場合は変換不要です
print(matrix.todense())
出力結果を成形するとこのようになります。「久しぶりに映画で感動しました」と「こんなに感動した映画は久しぶりです」という文章は0と1の箇所が似通っていて、近そうな文章だということが分かります。一方で「アクションシーンが見物です」は他の文章と共通点が少なく、別のことを言っていそうだということが分かると思います。これで、ベクトル化された文章を手に入れることができました。
| 文章 | こんなに | です | まし | アクション | シーン | 久しぶり | 感動 | 映画 | 見物 |
|---|---|---|---|---|---|---|---|---|---|
| 久しぶりに映画で感動しました | 0 | 0 | 1 | 0 | 0 | 1 | 1 | 1 | 0 |
| こんなに感動した映画は久しぶりです | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 0 |
| アクションシーンが見物です | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 1 |
形態素解析がうまくいかない場合
形態素解析の実行
先ほどは形態素解析がうまくいきましたが、次の例はどうでしょうか?
from janome.tokenizer import Tokenizer
t = Tokenizer()
s = 'ストロベリーチーズケーキ'
for token in t.tokenize(s):
print(token)
実行結果は「ストロベリーチーズケーキ」が固有名詞として1単語と出力されています。「ストロベリー」「チーズ」「ケーキ」には分けてくれませんでした。
ストロベリーチーズケーキ 名詞,固有名詞,組織,*,*,*,ストロベリーチーズケーキ,*,*
文章のベクトル化
もしかしたら嫌な予感がしているかもしれませんが、これもベクトル化してみましょう。
from janome.tokenizer import Tokenizer
from sklearn.feature_extraction.text import CountVectorizer
t = Tokenizer()
s_list = [
'ストロベリーチーズケーキ',
'ベリーベリーチーズケーキ',
'チーズケーキ'
]
# 分かち書きされた文章に変換する
def tokenize(text):
tokens = [token.surface for token in t.tokenize(text)]
return ' '.join(tokens)
tokenized_list = [tokenize(text) for text in s_list]
# 分かち書きされた文章からベクトルを得る
cv = CountVectorizer()
matrix = cv.fit_transform(tokenized_list)
print(cv.get_feature_names())
print(matrix.todense())
出力結果を見てみると、この3つをベクトル化すると共通点は一つもありません。直感的に考えても不自然なことですし、このまま機械学習モデルに入れたとしても学習への悪影響は避けられない気がします。
| 文章 | ケーキ | ストロベリーチーズケーキ | チーズ | ベリーベリーチーズケーキ |
|---|---|---|---|---|
| ストロベリーチーズケーキ | 0 | 1 | 0 | 0 |
| ベリーベリーチーズケーキ | 0 | 0 | 0 | 1 |
| チーズケーキ | 1 | 0 | 1 | 0 |
形態素解析の改善と課題
上記の様な事態は、形態素解析エンジンが良くないというよりも、形態素解析エンジンの本来のタスクから少し逸れた使い方をしているため発生していると言えるでしょう4。固有名詞や類語をまとめるにはユーザ定義辞書を使えばある程度は対処できます。しかし、新語や造語が頻繁に登場する分野においては、辞書を常に更新する必要があるため、辞書のメンテナンスコストが課題になります。そもそも、商品名や映画のタイトルのように短すぎる文章には、形態素解析は向いていないのかもしれません。形態素解析以外に、文章をベクトル化する手法はないのでしょうか?
n-gram
形態素解析以外の文章のベクトル化の方法として、n-gramを紹介します。
n-gramの種類
n-gramは隣接するn個の文字・単語の組合せを数え上げることで、文章の特徴量とする方法です。n=1はuni-gram、n=2はbi-gram、n=3はtri-gramという呼び方をされます。単語レベル(word level)と文字レベル(character level)のn-gramが混同して語られる場合がありますので、整理しておきます。
単語レベルのn-gram
単語レベルのn-gramは形態素解析などで分かち書きができている前提になります。たとえば、「久しぶりに映画で感動しました」を2単語のbi-gramでベクトル化する場合を考えてみます。隣接する2つの単語のペアがベクトルの要素になるので、以下のようにベクトル化できます。<s>は文頭、</s>は文末を示すシンボルです。
| 文章 | <s>_久しぶり |
久しぶり_に |
に_映画 |
映画_で |
で_感動 |
感動_し |
し_まし |
まし_た |
た_</s> |
|---|---|---|---|---|---|---|---|---|---|
| 久しぶりに映画で感動しました | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
文字レベルのn-gram
今回は形態素解析ができない場合ですので、文字レベルのn-gramを使用します。「久しぶりに映画で感動しました」を2文字のbi-gramでベクトル化する場合を考えてみます。隣接する2つの文字のペアがベクトルの要素になるので、以下のようにベクトル化できます。
| 文章 | <s>_久 |
久_し |
し_ぶ |
ぶ_り |
り_に |
に_映 |
映_画 |
画_で |
で_感 |
感_動 |
動_し |
し_ま |
ま_し |
し_た |
た_</s> |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 久しぶりに映画で感動しました | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
n-gramによる文章のベクトル化
それでは、文字レベルのn-gramで文章をベクトル化してみましょう。今回はNLTKというライブラリを使用しますので、pip install nltkでインストールしてください。
from nltk.util import ngrams
from sklearn.feature_extraction.text import CountVectorizer
s_list = [
'ストロベリーチーズケーキ',
'ベリーベリーチーズケーキ',
'チーズケーキ'
]
# 文章から文字レベルのngramを生成する
def generate_ngram(text, n):
characters = [c for c in text]
ngram_generator = ngrams(characters, n=n, pad_left=True, pad_right=True
, left_pad_symbol='<s>', right_pad_symbol='</s>')
return ' '.join(['_'.join(x) for x in ngram_generator])
ngram_list = [generate_ngram(text, 2) for text in s_list]
# 文字レベルのngramから文章をベクトル化する
cv = CountVectorizer()
matrix = cv.fit_transform(ngram_list)
print(cv.get_feature_names())
print(matrix.todense())
結果は以下の通りになります。形態素解析では全く共通点の無かった3つのチーズケーキに、ngramによる文章のベクトル化では共通点が生まれました。一方で、新たな問題として、解釈しにくい大量のngramが要素として生成されてしまいました。
| 文章 | </s>_ス |
<s>_チ |
<s>_ベ |
キ_</s> |
ケ_ー |
ス_ト |
ズ_ケ |
チ_ー |
ト_ロ |
ベ_リ |
リ_ー |
ロ_ベ |
ー_キ |
ー_ズ |
ー_チ |
ー_ベ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ストロベリーチーズケーキ | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 |
| ベリーベリーチーズケーキ | 0 | 0 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 2 | 2 | 0 | 1 | 1 | 1 | 1 |
| チーズケーキ | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 |
n-gramの課題

n-gramを現実の問題に適用しようとすると、辞書を作る必要がなくなった代わりに、入力するベクトルの次元数が数十〜数百万次元と巨大になることが問題になります。次元圧縮をしてからモデルに入力する流れを見ていると、次元圧縮もモデルもいっぺんに学習してくれそうな、Deep Learningに思い当たらないでしょうか?
もはや記号処理にも思えるn-gramによる文章のベクトル化の手法は、情報検索分野においてよく見かけます5。検索クエリに入力される文章は非常に短いながらも、そこからなんとか特徴量を抽出して合致する情報を引っ張ってくるかにおいて、n-gramによるベクトル化は重要な手法です。
文字コードとCNNによるベクトル化
Deep Learningで自然言語処理というと、どうしてもRNN(Recurrent Neural Network)が最初に思い浮かぶと思いますが、タスクによっては一文字ごとを入力とするCNN(Convolutional Neural Network)でも対応可能です6 7。たとえば、Twitterのように文字数制限がある場合は、入力を固定長の140文字として、文字が足りない部分は0で埋め、文字数が超過した場合は打ち切りをしてCNNに入力し、分類タスクを実行すると言うことも可能です。また、中間表現が人間に解釈不可能でも良いということであれば、入力をASCIIコードにしてしまうという方法もあります。
まとめ
今回は、形態素解析以外の文章ベクトル化の手法をご紹介しました。みなさんも、ご自身のタスクに合わせて文章のベクトル化を検討いただければと思います。
-
janomeの場合、正規化はCharFilterで対応可能 ↩
-
janoemの場合、ストップワードの設定はTokenFilterで対応可能 ↩
-
Bag of Wordsは単語の数え上げによるシンプルなベクトル化です。単語の重み付けも考慮したTF-IDFなども合わせて検討すると良いでしょう ↩
-
自然言語処理の大きなタスクとして言語モデルの生成があり、そのために単語分割や品詞特定を実施する形態素解析が使われてきました。今回の分類や回帰とは異なるタスクのための手法を流用していると考えてください。 ↩
-
例えば、A Multi-View Deep Learning Approach for Cross Domain User Modeling in Recommendation Systems ↩