はじめに
IBM Cloudでは、Cloud Logsというログ機能が従来のLogAnalysisの後継としてリリースされています。新しいUIなので、全く馴染みのない人のためにすごく簡単なログの探し方を書いてみました。
1. ログを表示させる
まず、超初心者が1番ありがちなのは、初めてコンソールにアクセスした際に、以下のように表示されて"ログが表示されていない!?"って思うことです。これは、
- Priority Insights(管理者が特に重要とみなしているログだけを優先的に表示する機能)が選択されているから
- 正しい時間軸が選択されていないから
の可能性が高いです。それを修正してみると、、、

以下のようにログがずらずらと出てきましたね。
また、画面を広く使いたい場合は、適宜左側に表示されるフィルターを隠しましょう。
- Before
- After

2. タイムゾーンとログ日付フォーマットのカスタマイズ
表示されるログのTimestampは、デフォルトでDD/MM/YYYYのようになっています。つまり、2024年12月6日だと06/12/2024のように表示されます。初見の人にとっては、これに違和感を感じるはずです。必要に応じてこの表示方式は修正しましょう。また、タイムゾーンもデフォルトではLocal timeではなくGMTの方が良いという人は、そちらも変更することも可能です。
- Preferencesを選択。

- 必要に応じて
MM/DD/YYYY方式に変更する。
3. ログ表示のカスタマイズ
次に触ってみるべき箇所は、ログの表示方法です。今は1行ずつ表示されていますね。1つのログを隅々まで見る前に、まずはログを探さなければいけません。将来的にフィルタリングをして探していくにしても、そもそも1つ1つのログの違いの概要をざっと目視で把握する必要があります。そのためには、1つ1つのログをどのように一覧表示すると良さそうかを適宜その時々で使いやすいものに切り替えて利用すると良いでしょう。
(ちなみに私は普段は1 Lineを使っており、必要に応じてログを展開して確認するようにしています)

- 1 Line:

ちなみに、>をクリックすることでログを展開し、以下のように詳細を表示させることも可能です。
- 2 Line:

- Condensed:

- JSON:

- List:

4. グラフ表示のカスタマイズ
グラフは、Severityごとの数で表示されています。
-
Count all grouped by Severityのあたりをクリックすると、
- 以下のように表示される形式が指定できることがわかる。

- 例えば以下のように、
initiator.authNameごとの集計に変更すると
- 直近で誰がどれぐらいアクセスしているのかな?ということも簡単にグラフ化できます。

また、異なる期間のデータを比較することも可能であり、Severityごとの集計にするにしても、Compare toの設定で1日前を指定すれば、以下のように上に今日の、下に比較先(一日前)のグラフを表示させるようなことも可能です。
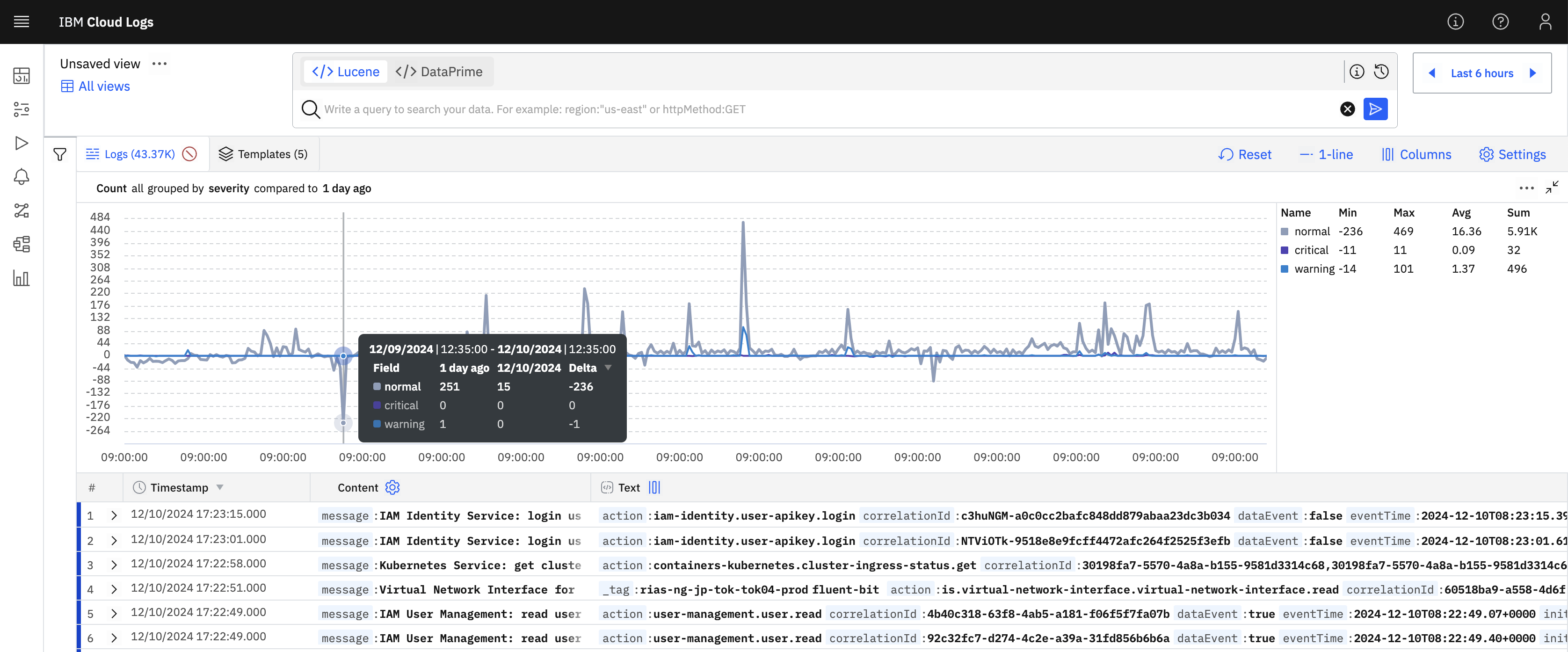
5. カラムの追加
このログ一覧をよく見てみると、Timestamp, Content, Textという3つのカラムしかありません。ログによっては、もっと特徴的な情報を表示させた方が良い場合があります。
ログを見てみるとわかりますが、このContentも単にmessage欄を引き抜いてきているだけだということがわかります。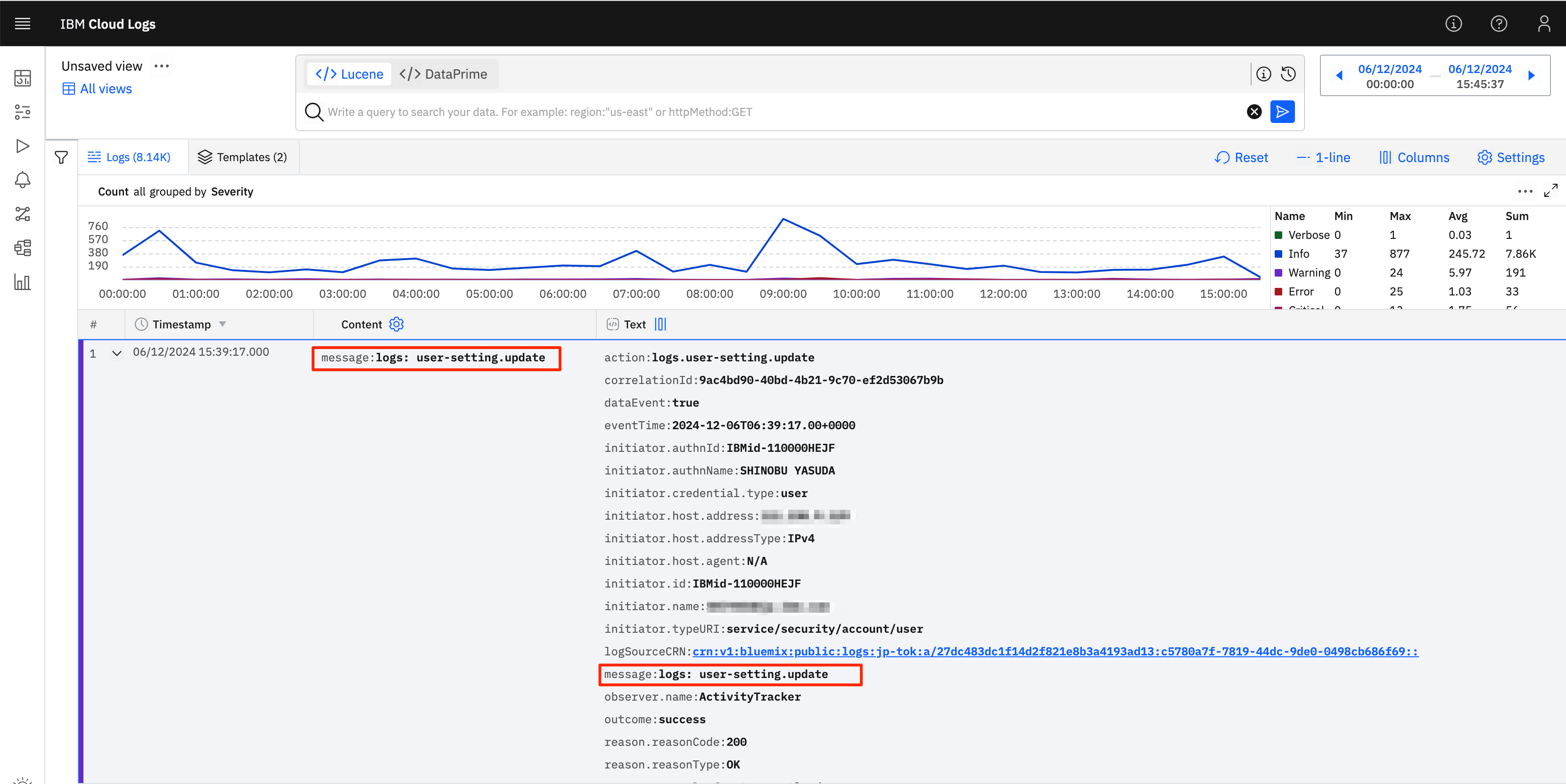
よって、必要に応じてカラムを追加すると分かりやすくなるでしょう。例えば、今回は監査目的でログを探索しており、「誰が作業を実施したのか」というログを確認したいので、ログの中でも誰が操作をしたかを記録していると思われるInitiator.authNameをカラムに追加したいと思います。ログ内のInitiator.authNameの箇所を以下のようにクリックするとメニューが表示されるので、そこでAdd As Columnを選択します。

そうすると、誰が実施した作業なのかが容易に判別可能になりました。
6. ログを探す1(UI+単純検索)
いよいよ、該当のログを探したいと思います。今回は、ICOSの操作ログを追いかけたいと思います。
今回は、以下のようにICOSへのデータアクセスをイベントとしてトラッキングする構成にしているため、ICOSへのデータアップロードなどはイベントに記録されています。

先ほど、直近でアップロードしたファイル名はtest3.txtだったので、まずはあまり深く考えずにtest3.txtでフィルターしてみたいと思います。すると以下のように出てきました。
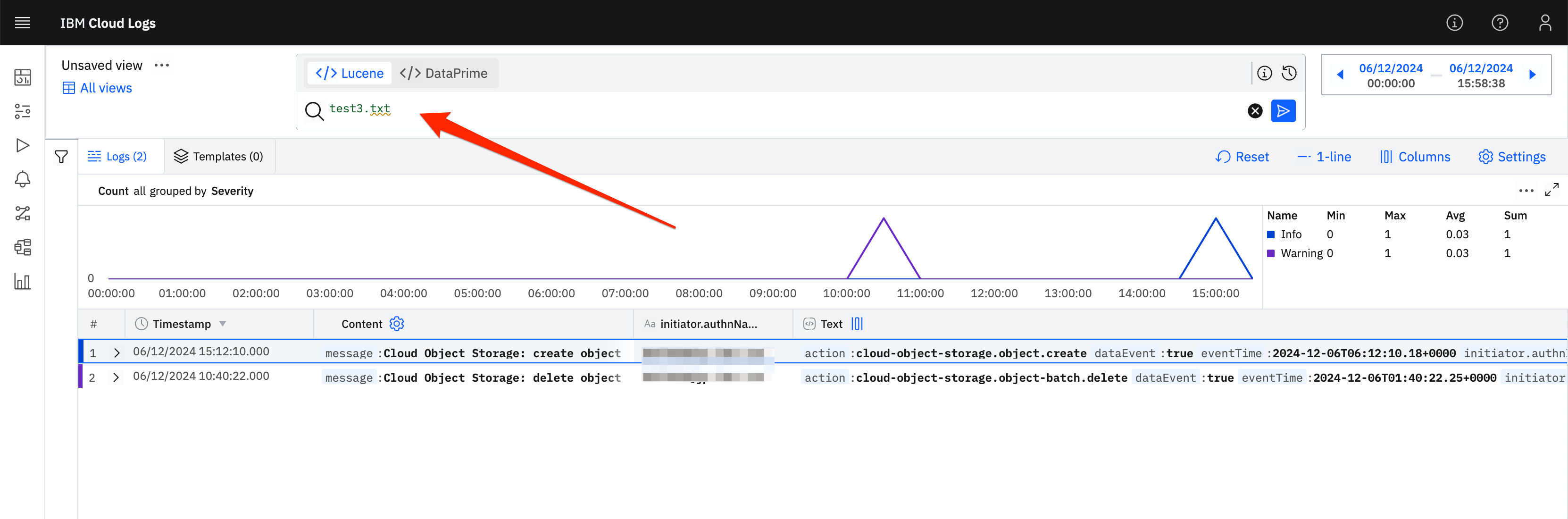
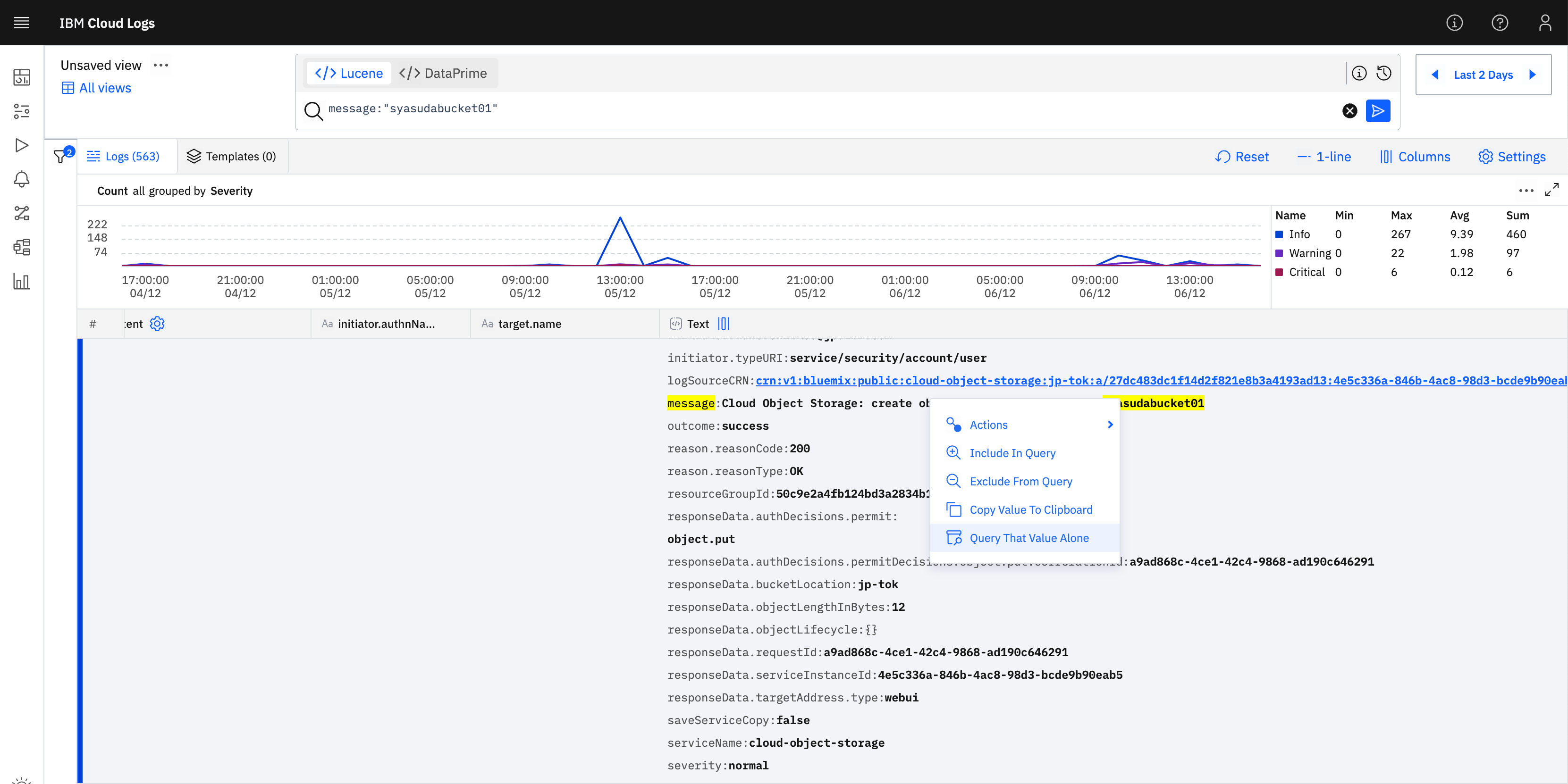
そのログを見てみたところ、「あぁ、そういえばこんなbucket名だったな」と思い出したので、改めてこのbucket名(syasudabucket01)をクリックして、Query That Value Aloneを選択します。

すると、自動的にmessageキーにsyasudabucket01という名前が含まれているログを探すQueryを生成してくれます。

また、ログを見てみるとtarget.nameキーが操作対象のファイルを出力してくれているということがわかったので、改めてそれを別カラムとして作成してみます。

すると、気になるログが抽出できました。

また、実際はmessageキーにbucket名が含まれているかどうかでログを抽出するのは不適切であるため、以下のようにlogSourceCRNの値で検索した方が良いということにも気が付くと思います。
- LogSourceCRNの値をベースにQueryをフィルターをかけてみる
- フィルター欄にLogSourceCRNベースの値が含まれていることが分かる。
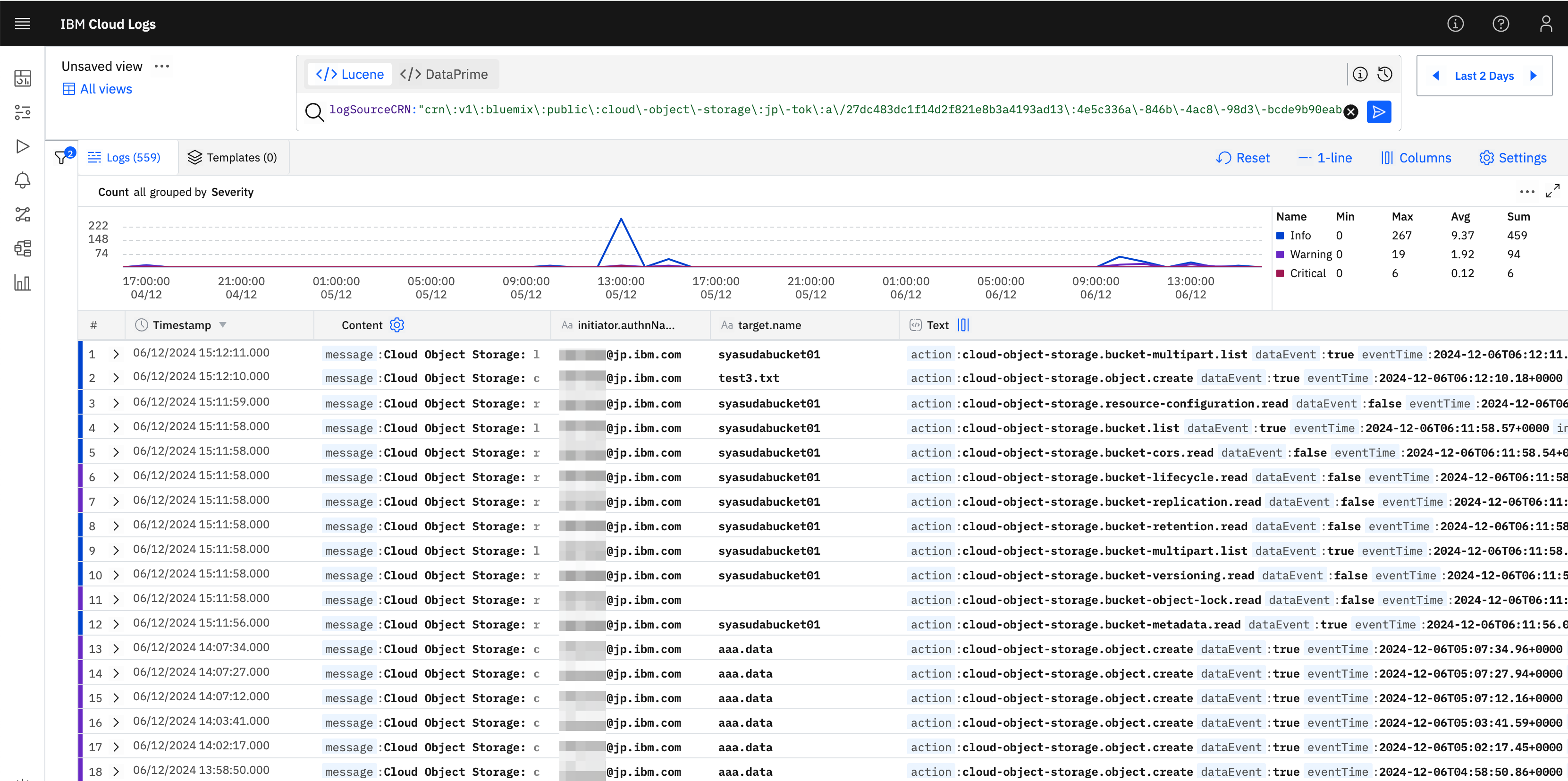
最初から適切な探し方を見つけるのは難しいため、このように試行錯誤の末たどり着くことも多いでしょう。ちなみに、上記では、Query That Value Aloneを選択したので、上記のような結果になりましたが、Include In Queryを選択すると、既存のフィルター条件に加えてANDで選択したフィルターを追加することができます。
7. ログを探す2(もう少し細かな検索方法)
ログの検索には、Apache Lucene(ルシーン)や、Coralogix DataPrimeのSyntaxが使えますが、Luceneの方が簡単なのでまずはこちらを使いこなせるようになると良いでしょう。
ここが参考になりますが、いくつか記法を抜粋しておきます。
| Lucene記法 | 意味 |
|---|---|
ubernete |
ubernete というキーワードを含む完全一致。containers-kubernetes-keyを含むログはマッチング対象とならない。 |
Kubernetes |
Kubernetes というキーワードを含む完全一致。containers-kubernetes-keyを含むログは-が区切り文字という扱いになっており、また大文字・小文字を無視するためマッチング対象。 |
ubernete* *ubernete |
ワイルドカード検索。containers-kubernetes-keyというキーワードを含むログはどちらもマッチング対象。ただし、Luceneのバージョンによっては冒頭の*は使えないようなので、冒頭に*を利用する探索は避けた方が良いかもしれない。 |
"create object" |
"create object"という文字列を含む |
test4 |
test4 というキーワードを含む。test4.txtを含むログも、.が区切り文字となっているためマッチング対象 |
test4 syasudabucket01 |
test4というキーワードとsyasudabucket01というキーワードを両方含む(自動的にAND条件になる) |
test4 AND syasudabucket01 |
test4というキーワードとsyasudabucket01というキーワードを両方含む |
test4 OR syasudabucket01 |
test4というキーワードとsyasudabucket01というキーワードをどちらか含む |
message:create |
messageフィールドにcreateというキーワードを含む。message:Virtual Server for VPC: create console-access-tokenなどがマッチング対象 |
reason.reasonCode:[400 TO 500} |
reason.reasonCodeフィールドに400以上500未満(499以下)のキーワードを含む |
initiator.host.address:/111.[0-9]{1,3}.9.[0-9]{1,3}/ |
initiator.host.addressフィールドに111.xx.9.xxというIPアドレスを含む。//に挟むことで正規表現が使える。 |
また、必要に応じて、このフィルターのQueryに対して保存しておきましょう。後から誰かと共有する時に便利です。

本投稿時点では、Priority Insightsだと12K、ICOSだと50Kまでしか結果が返らないという制約があります。適宜フィルターを使ってログを絞り込みましょう。
https://cloud.ibm.com/docs/cloud-logs?topic=cloud-logs-query_limitations&locale=en
8. 気になるログはハイライトしておいたり、ログに対するリンクを残しておく。
ログはハイライトしておくことで、色を変更できます。
- ハイライト処理
- ログの色が変わる

また、リンクを作成しておき、後ほどこのログを後から参照できるようにすることも可能です。
- ログへのリンク作成

9. ログをローカルにexportする
ログは、json方式もしくはCSV方式で保管可能です。
-
Settings->Exportを選択。
- JSON方式だと、フィルター結果に対して、現在のviewに沿ったexportか、全データのexportかを選択可能。

- デフォルトだと最初の1ページしかexportされないので、
Export xxx First pagesを変更する。最大で20ページ分までexport可能。

- CSV方式の場合は、現在のviewに沿ったexportであるかどうかは選択できず、そのままフィルター結果に対して、データをexportする。

最大で20ページしかexportできません。1ページあたりのログが100なので、20ページということはおよそ2000までのログしかexportできません。
https://cloud.ibm.com/docs/cloud-logs?topic=cloud-logs-export-data&locale=en
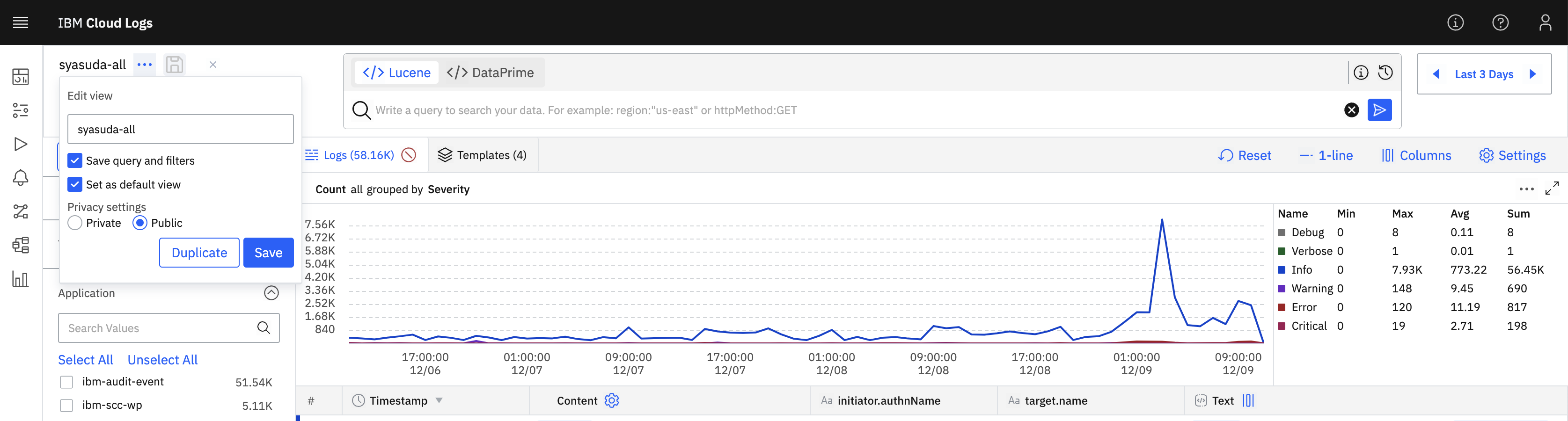
10. Viewとして保存する
このカラム条件やフィルター条件などは、そのままでは次回ログイン時には消えてしまいます。よってこのViewを保存しておきます。
-
Unsaved view ...の箇所をクリック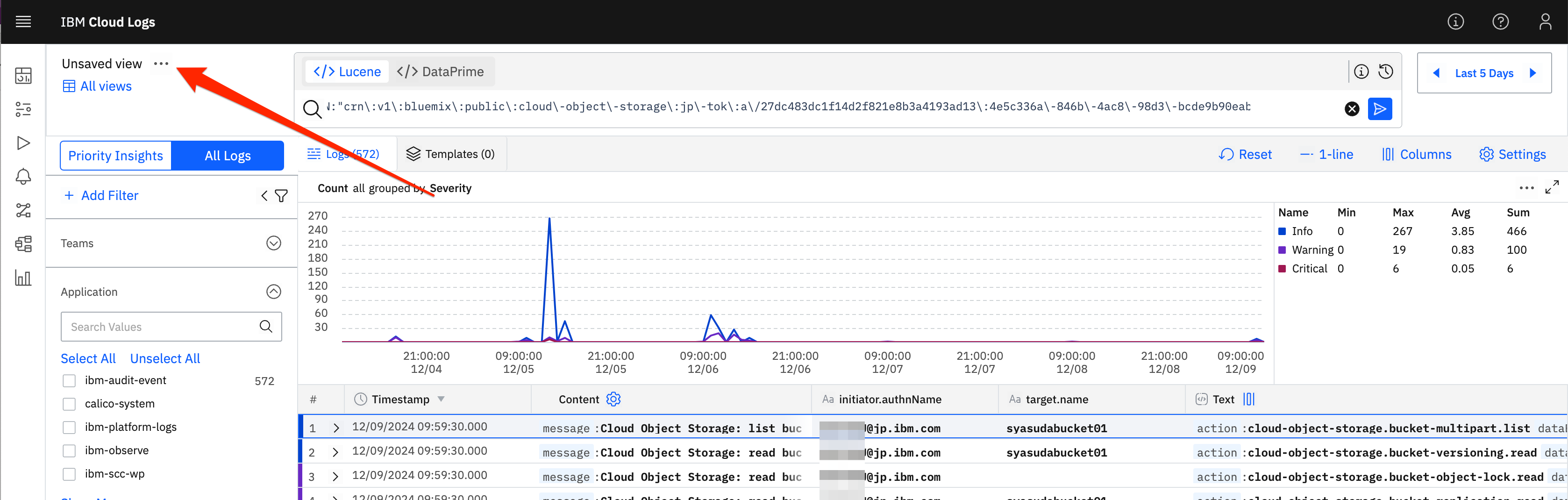
- 適当な名前を指定してViewを作成。なお、Privacy settingsを
Priateにしておくと、自分にしか見えないViewとなります。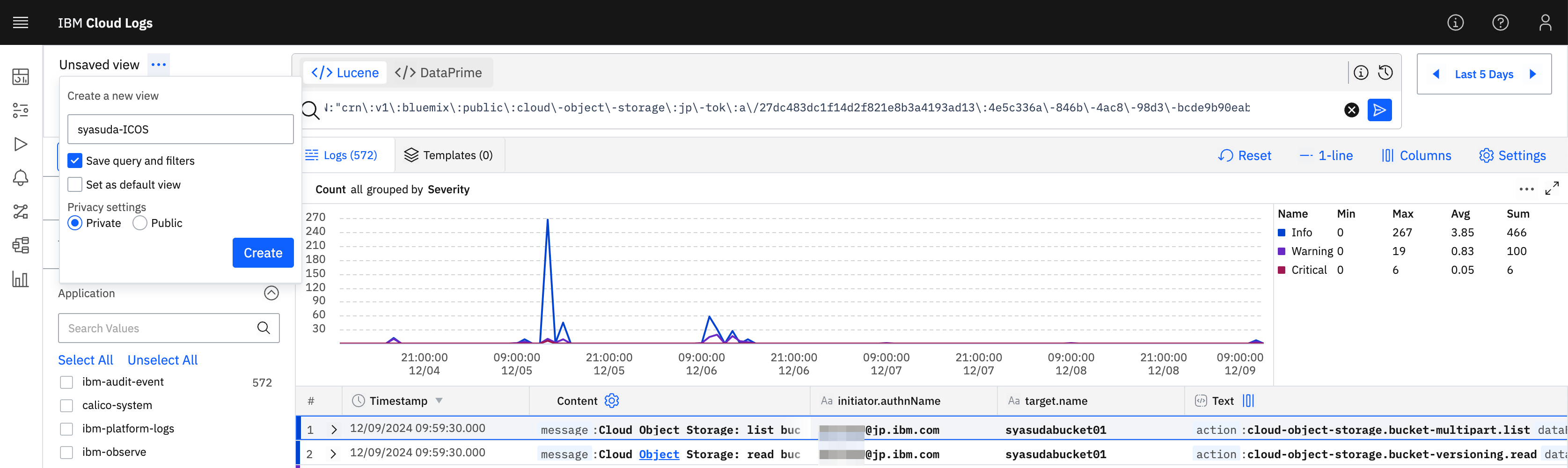
これで終わりでも良いのですが、大人数でCloud Logsを共用利用する場合は、フォルダーを作って分類した方が良いでしょう。
-
All Viewsを選択。
- フォルダーボタンを押下。

- フォルダーを作成。

- フォルダが作成された。

- フォルダが作成されたので、先ほどのViewを作成したフォルダーにドラッグアンドドロップすると、移動できる。

なお、このViewを再度カスタマイズしてそれを再度同じ名前で保存したい場合は、Saveボタン(フロッピーディスクのようなボタン)を押下するとQuick Saveができます。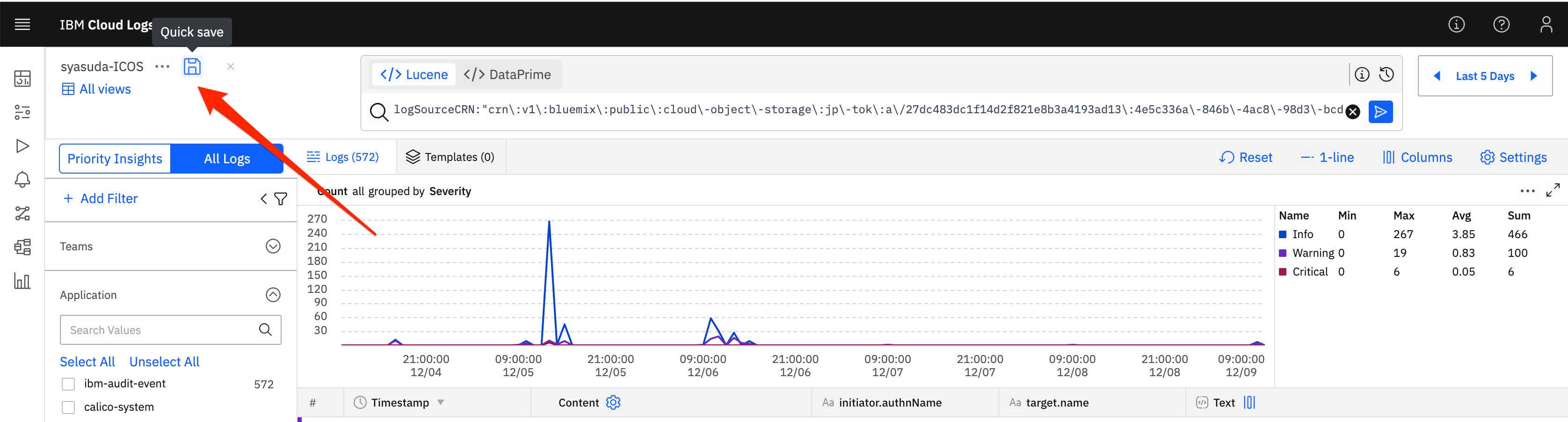
逆に、Viewを別名で保存したい場合は、以下のように実施します。
-
メニュー内で最初に
Duplicateを選択する。
-
その上で名称などを再度編集する
- Before:

- After:
- Before:
-
必要に応じてViewを適切なフォルダに移動しましょう。
- 移動前!

- 移動後!

- 移動前!
ちなみに、私はログを見る時に、誰が何を操作したのかを理解したいので、initiator.authNameとtarget.nameをカラムに追加したビューをデフォルトのビューにしています。