はじめに
めちゃくちゃ流行ってますよね、機械学習。
ですが、用語とか数式とかの時点でもう既に難しい上、Spark、Hadoop、Scala(or Python)と「環境構築だけでも覚えることが多すぎて嫌になってしまった」という方も多いのではないでしょうか。(わたしです)
そんな方にお勧めなのが、こちらのフルスタック機械学習プラットフォーム「PredictionIO」です。
私自身、PredictionIOだけでなく機械学習自体もはじめたばかりですので、間違っている記述や怪しい記述など多々あると思いますが、ご容赦&ご指摘いただければ幸いです。(もっと知見増えろの意)
PredictionIOについて
概要
2016/02/19にSalesforce.comに買収され、2016/05/26にApacheのIncubationに登録 された、比較的新しい、機械学習ソフトウェアです。
Spark, MLib, OpenNLP, Hbaseなどの、機械学習分野でよく使われるミドルウェアやライブラリを組み合わせて構成されており、「非常に簡単に」機械学習の環境を構築することができます。
機械学習ロジック部分を「Engine Template」として切り出し、それ以外の学習用データ入出力、結果用データ入出力の機能をPredictionIOが担うことで、機械学習のメインである「アルゴリズム」部分に注力できるようになっているのが特徴です。
わかりやすさ重視でざっくり表すと、こんな感じでしょうか。
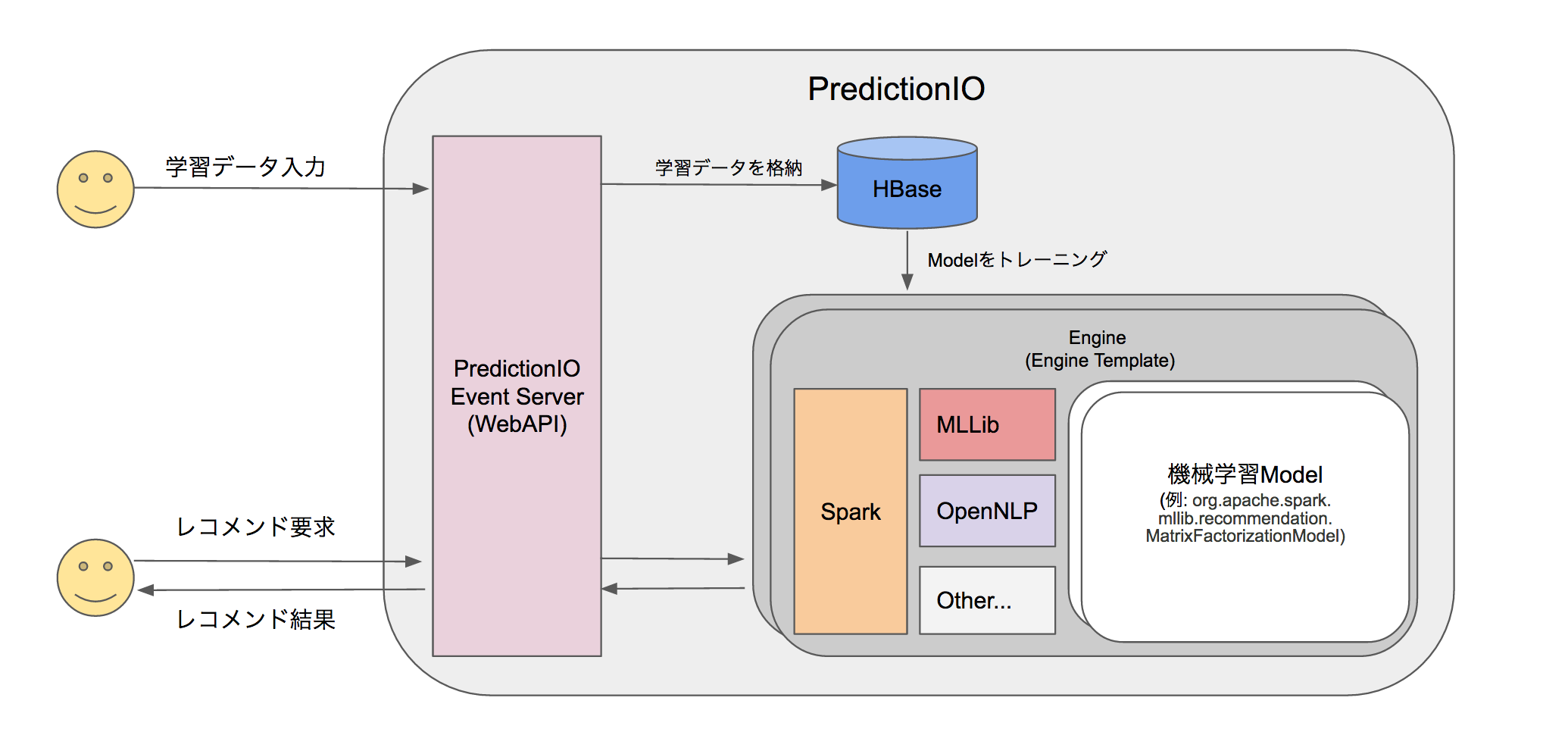
参考:
Good!!
 各ミドルウェアをそれぞれインストールし、環境構築する必要がない
各ミドルウェアをそれぞれインストールし、環境構築する必要がない
Setupスクリプト、Dockerfile等で環境構築手順が自動化されているため、環境構築にありがちなミドルウェアのバージョンによる不具合、環境に依存する不具合、設定ミスによる不具合などが起こりにくくなっています。
また、インストーラを実行したらあとは待ってるだけでいいので、とても楽です。
各ミドルウェアの使い方を覚えていく必要がない
学習データの入出力や、学習データストア部分はPredictionIOが隠蔽してくれるため、SparkやHadoopなどのコマンドを直接叩いたりすることは(基本的には)ありません。
このため、最初に覚えることが少なく、初学者に大変やさしくなっています。
WebAPIとして提供できるので、他アプリとの連携がしやすい
学習用データの入力、結果データの出力は、WebAPI(RESTAPI)サーバとして立ち上がったPredictionIOが担当します1。 わざわざWebAPIを作らずとも、他システムやWebアプリ、ネイティブアプリとのデータ連携を、一般的なHTTP(S)、application/json形式で行うことができます。
機械学習アルゴリズム部分だけにフォーカスできる
前述のに、機械学習に直接的には関係の薄い部分をPredictionIOが担ってくれるので、機械学習のアルゴリズム(いわゆる「数式部分」?)にフォーカスすることができます。また、公開されている「Engine Template」自体を実装サンプル(参照実装)にすることができます。
ドキュメントが詳しい
Welcome to Apache PredictionIO (incubating)!
バージョンの若さに比べれば、かなり整っている印象を受けました。
どこに何があるのかわかりにくかったり、たまにリンク切れになっていたりはするのですが、それらを差し引いても、しっかり記述されている印象です。
Bad...
 バージョンが若い(2016/12時点でv0.10.0)
バージョンが若い(2016/12時点でv0.10.0)
プロダクト自体は結構昔からあるようですが、2016/05/26にApacheのIncubationに登録 したばかりということで、実運用するのはかなり勇気がいるかも…
Engine Templateも対応バージョンが明記されていますが、バージョンアップによりうまく動かないなどは、十二分に考えられそうです。
各ミドルウェアを個別に構築/運用した場合とは、別の問題でハマる可能性がある
「XAMPPみたいなもの」と言えば思い当たる方も多いかと思いますが、それに加えてPredictionIO自体の情報が少ないこともあり、問題に遭遇してしまった場合、解決まで時間がかかるかもしれません。
また、最終的には各ミドルウェアについての、きちんとした知識が必要となりそうです。(これもこの手のソフトウェアで共通という気はしますが)
「Engine Templateを導入すれば、そのまま機械学習エンジンを提供できる」ものではない
あくまで「Template」でしかないため、実現したいユースケース、対象データの規模などによって、おそらくかなりカスタマイズしたり、作り込む必要があります。
個人的な感想ですが、「簡単に既存システムにレコメンド機能を追加したい」という要件であれば、おそらく素直に既存の商用プロダクトや商用サービス等を使うほうが、最終的には安く上がる気がしました。
PredictionIOの設計方針に従わなければならない
PredictionIOはDASEという設計方針でEngine Templateを設計/実装しているのですが、非常にわかりやすい反面、機械学習アルゴリズムの実装自由度が下がったり、逆に複雑になってしまう可能性があります。
特に既存のEngine Templateの中身を見てるとBKっぽいなあ…という部分もあり…2
個人的には、RoRの**「レールに乗っていれば楽だが、レールから外れたことをすると大変」**というフレーズに、とてもよく似た印象を受けました。(このあたりは実装方法や要件次第だったりするのかもしれませんが…)
既に機械学習分野に充分以上の知識があり、実装経験もある方の場合は、逆に不満が募ることになるかもしれません。
まとめ
現時点では
「実運用はいろんな意味で厳しいが、これを使って機械学習に足を踏み入れるのはアリでは?」
という感じです。(あくまで個人の感想です)
1. 環境構築、動作確認
前フリが長くなってしまいました。とりあえず、動かしていきたいと思います。
導入方法については色々あるのですが、ここでは
- 構築が簡単
- 個人の環境に依存しにくい
Dockerを利用したパターンをご紹介します。
動作確認環境
2016/12/12 時点のものを利用し、以下の環境で動作確認しました。
- Native Docker for MacOS
- Version 1.13.0
- MacBook Pro (Retina, 13-inch, Mid 2014) (16GB) OSX Sierra
- Native Docker for Windows
- Version 1.13.0
- 自作PC (i7-4790 @ 3.60GHz, SSD) (32GB) Windows 10 64bit
Dockerfileにもいろいろあるのですが、最新版v0.10.0の対応が明記されている、こちらを利用します。
-
steveny2k/docker-predictionio: Docker container for PredictionIO-based machine learning services
- 利用している各ミドルウェアのバージョンについては、こちらを御覧ください。
ここではDockerfileからビルドしてみます。3
$ git clone git@github.com:steveny2k/docker-predictionio.git
$ cd docker-predictionio/
$ docker build -t predictionio .
(小一時間くらい)
// Dockerコンテナ起動、ログイン
$ docker run -p 8000:8000 --name predictionio_instance -it predictionio /bin/bash
コンテナに初回ログインした後は、以下の関連ライブラリのインストールをお勧めします。
// PredictionIOの各種スクリプトがsudo前提で書かれているので
// (sudoコマンドがないとHBaseがきちんと動かない?)
root@875924d2b7ef:/# apt-get update
root@875924d2b7ef:/# apt-get install sudo
// サンプルデータの一括投入スクリプトでよく利用する、Python用のpredictionioライブラリ
root@875924d2b7ef:/# pip install --upgrade pip
root@875924d2b7ef:/# pip install setuptools
root@875924d2b7ef:/# pip install predictionio
あとは以下のようにPredictionIOサーバの起動/停止を行ってください。(pio-restart-allはないようでした)
// 起動
root@875924d2b7ef:/# pio-start-all
// 停止
root@875924d2b7ef:/# pio-stop-all
2. Sample Engineを動かす
PredictionIOの起動ができたら「Similar Product Engine Template」を利用して、動作確認を行いたいと思います。
以下のコマンドで、Engine Templateを配置します。4
root@875924d2b7ef:/# pio template get apache/incubator-predictionio-template-similar-product ~/MySimilarProduct
root@875924d2b7ef:/# ls ~/MySimilarProduct/
README.md build.sbt data engine.json manifest.json pio.log project src target template.json
AppNameを登録し、AccessKeyを払い出します。ここではAppName=MyApp1として登録しました。
RESTAPIや各種のSDK5 から学習用データを登録する場合に、このAccessKeyを利用することになります。
root@875924d2b7ef:/# cd ~/MySimilarProduct/
root@875924d2b7ef:/# pio app new MyApp1
[INFO] [App$] Initialized Event Store for this app ID: 1.
[INFO] [App$] Created new app:
[INFO] [App$] Name: MyApp1
[INFO] [App$] ID: 1
[INFO] [App$] Access Key: 3mZWDzci2D5YsqAnqNnXH9SB6Rg3dsTBs8iHkK6X2i54IQsIZI1eEeQQyMfs7b3F
途中でAccessKeyを忘れてしまった場合は、以下のコマンドで参照してください。
root@875924d2b7ef:/# pio app list
[INFO] [App$] Name | ID | Access Key | Allowed Event(s)
[INFO] [App$] MyApp1 | 1 | 3mZWDzci2D5YsqAnqNnXH9SB6Rg3dsTBs8iHkK6X2i54IQsIZI1eEeQQyMfs7b3F | (all)
[INFO] [App$] Finished listing 1 app(s).
登録したAppName(MyApp1)をengine.jsonに設定します。
$ vi engine.json
---
"datasource": {
"params" : {
"appName": "MyApp1"
}
},
---
まずは学習用のデータを投入します。
RESTAPI経由で一件ずつ投入することもできますが、大変なので付属の一括投入スクリプトを利用します。
学習用データもこのSimilar Product Engine Templateに付属しているものを使います。
root@875924d2b7ef:/# python data/import_eventserver.py --access_key 3mZWDzci2D5YsqAnqNnXH9SB6Rg3dsTBs8iHkK6X2i54IQsIZI1eEeQQyMfs7b3F
...
User u10 views item i18
User u10 views item i29
160 events are imported.
次に、Engine Templateのビルドを行います。
このEngine TemplateはScala製なので、中でScalaプロジェクトのビルドを行っているようです。
初回はjarを拾ってきたりする必要があるので、少し時間がかかります。
root@875924d2b7ef:/# pio build --verbose
[INFO] [Console$] Your engine is ready for training.
学習用データと、ビルドしたEngineを使って、トレーニング(機械学習)を行います。
root@875924d2b7ef:/# pio train
...
[INFO] [CoreWorkflow$] Training completed successfully.
Engineのトレーニングが完了したら、以下のようにデプロイすることで、WebAPIとして公開することができます。
ホストマシンのブラウザから http://localhost:8000 を開いて、Dockerコンテナ内のWebサーバが立ち上がり、アクセスできる状態になっていることを確認してください。
root@875924d2b7ef:/# pio deploy
[INFO] [HttpListener] Bound to /0.0.0.0:8000
[INFO] [MasterActor] Bind successful. Ready to serve.
WebAPIを叩いて、レスポンスが返ってくればOKです。6
$ curl -H "Content-Type: application/json" \
-d '{ "items": ["i1"], "num": 4 }' \
http://localhost:8000/queries.json | jq .
{
"itemScores":[
{"item":"i43","score":0.7071067811865475},
{"item":"i21","score":0.7071067811865475},
{"item":"i46","score":0.5773502691896258},
{"item":"i8","score":0.5773502691896258}
]
}
PredictionIOの基本的な流れはこのように、
- 学習用データの投入(
# python data/import_eventserver.py --access_key ...) - 機械学習エンジンのビルド (
# pio build) - 機械学習エンジンのトレーニング (
# pio train) - 機械学習エンジンのデプロイ(
# pio deploy) - 動作確認(
$ curl http://localhost:8000/queries.json ....)
となっています。7
なんとなく、PredictionIOの雰囲気は掴んでいただけましたでしょうか?
次は、機械学習系で定番の「MovieLens」のサンプルデータを使った、レコメンドエンジンの提供を目指していきたいと思います。
→ 2. Recommendation Template編
-
後ほど詳述できればと思いますが、レコメンドエンジンのサンプルテンプレートで、PredictionIOの学習用データ型(org.apache.predictionio.data.storage.Event)と、機械学習アルゴリズムが利用しているMLLibのデータ型(org.apache.spark.mllib.recommendation.Rating)の間でI/Fに互換性がないため、機械学習アルゴリズムとは直接無関係な、煩雑な型変換処理が必要になっていたりします。 ↩
-
$ docker run -it -p 8000:8000 steveny/predictionio /bin/bashで構築済のImage(2GB超)をDockerRepositoryから取得することもできますが、「メンテナンスされなくなるかも」と書いてありました。2016/12/時点では、こちらの方法でもとりあえずは問題ありませんでした。 ↩ -
内部的にはgit cloneしたあとに、
.git/ディレクトリを削除しているだけのようです。 ↩ -
Python, PHP, Ruby, Javaがあるようです。 ↩
-
レスポンスの内容はEngineの学習内容によって異なります。 ↩
-
- 学習用データ投入と 2. Engine Templateのビルドには依存関係がないので、どちらが先でもOKです。