前回PredictionIOの動作確認はとりあえずできたので、Recommendation Engine Templateを使い、レコメンデーションを動かしてみたいと思います。
基本的な手順はまったく同じです。
# pio template get apache/incubator-predictionio-template-recommender ~/MyRecommendation
# cd ~/MyRecommendation
# pio app new MyApp2
[INFO] [HBLEvents] The table pio_event:events_2 doesn't exist yet. Creating now...
[INFO] [App$] Initialized Event Store for this app ID: 2.
[INFO] [App$] Created new app:
[INFO] [App$] Name: MyApp2
[INFO] [App$] ID: 2
[INFO] [App$] Access Key: Dv7p5rYWOtbtBiVKULJwjjGu2oqqPGuuD3eBQNFpRF3HQABXncEWiErHzSEr_eiz
# vi engine.json
---
"datasource": {
"params" : {
"appName": "MyApp2"
}
},
---
// 学習用データ取得
# curl https://raw.githubusercontent.com/apache/spark/master/data/mllib/sample_movielens_data.txt --create-dirs -o data/sample_movielens_data.txt
# python data/import_eventserver.py --access_key=Dv7p5rYWOtbtBiVKULJwjjGu2oqqPGuuD3eBQNFpRF3HQABXncEWiErHzSEr_eiz
Importing data...
1501 events are imported.
# pio build
...
[INFO] [Console$] Your engine is ready for training.
# pio train
...
[INFO] [CoreWorkflow$] Training completed successfully.
# pio deploy
...
[INFO] [HttpListener] Bound to /0.0.0.0:8000
[INFO] [MasterActor] Engine is deployed and running. Engine API is live at http://0.0.0.0:8000.
あとはホスト側から確認してみます。
$ % curl -sS -H "Content-Type: application/json" \
-d '{ "user": "1", "num": 4 }' http://localhost:8000/queries.json | jq .
{
"itemScores": [
{
"item": "2396",
"score": 6.188385643364221
},
{
"item": "2571",
"score": 6.1600449198740215
},
{
"item": "593",
"score": 6.010834019720912
},
{
"item": "1221",
"score": 6.001154572406882
}
]
}
こちら、環境によっては$ pio trainを実行したときに、以下のようなエラーが出るかと思います。
2016-12-22 13:10:40,969 ERROR org.apache.spark.executor.Executor [Executor task launch worker-0] - Exception in task 3.0 in stage 70.0 (TID 239)
java.lang.StackOverflowError
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1385)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:2018)
...
対策としては3通りあり、
- JVMにオプションを指定し、Spark実行時のヒープサイズを拡張する (後述)
- Engine中でSparkContextを使いチェックポイントを設定する(後述)
- engine.jsonで定義されている学習パラメータ、numIterationsの値を小さくする
ここでは、「3.」のアプローチを用います。
Evalutionで最適な学習用パラメータを取得
Recommendation Templateでは、engine.json内で学習用パラメータが設定されています。
"algorithms": [
{
"name": "als",
"params": {
"rank": 10,
"numIterations": 20,
"lambda": 0.01,
"seed": 3
}
}
]
numIterationsの値を少なくすることで学習の反復回数を減らし、java.lang.StackOverflowErrorを回避することができますが、PredictionIOにはEvalutionと呼ばれる、学習パラメータのチューニングをサポートする機能が用意されています。今回はこちらを使い、最適な学習用パラメータを取得してみたいと思います。
その前に、AppNameの値がRecommendation Template Engineのソースコード中にハードコーディングされているので1、エディタ等で直接変更し、$ pio build しなおしてください。
# vi src/main/scala/Evaluation.scala
---
78 appName = "INVALID_APP_NAME", // -> MyAPP2
---
ビルドが終わったら、以下のコマンドを実行してください。
少々時間がかかりますが、engine.jsonで定義されていると同じ形式の、学習用パラメータが表示されれば成功です。
# pio eval org.template.recommendation.RecommendationEvaluation \
org.template.recommendation.EngineParamsList
...
[INFO] [CoreWorkflow$] Updating evaluation instance with result: MetricEvaluatorResult:
# engine params evaluated: 9
Optimal Engine Params:
{
"dataSourceParams":{
"":{
"appName":"MyApp2",
"evalParams":{
"kFold":5,
"queryNum":10
}
}
},
"preparatorParams":{
"":{
}
},
"algorithmParamsList":[{
"als":{
"rank":5,
"numIterations":10,
"lambda":0.01,
"seed":3
}
}],
"servingParams":{
"":{
}
}
}
Metrics:
Precision@K (k=10, threshold=4.0): 0.0273970398970399
PositiveCount (threshold=4.0): 12.386666666666668
Precision@K (k=10, threshold=2.0): 0.028571428571428577
PositiveCount (threshold=2.0): 19.320000000000004
Precision@K (k=10, threshold=1.0): 0.030126984126984134
PositiveCount (threshold=1.0): 20.013333333333332
[INFO] [CoreWorkflow$] runEvaluation completed
得られたパラメータをengine.jsonに設定し、$ pio build $ pio trainを実行してみてください。
java.lang.StackOverflowErrorが起きなくなっていると思います。
# vi engine.json
---
"als":{
"rank":5,
"numIterations":10,
"lambda":0.01,
"seed":3
}
---
# pio build
# pio train
...
[INFO] [CoreWorkflow$] Training completed successfully.
$ pio eval が何をやっているのか興味がある方は、以下をご参照ください。
rank, numIterationsの値を変更しながらEngineを動かし、PrecisionAtKとPositiveCountを評価尺度として、最も良い結果が得られたパラメータを選択しているようです。
ソースコード中にはComprehensiveRecommendationEvaluationも定義されているので、こちらを利用することもできます。
# pio eval org.template.recommendation.ComprehensiveRecommendationEvaluation \
org.template.recommendation.EngineParamsList
...
[INFO] [CoreWorkflow$] Updating evaluation instance with result: MetricEvaluatorResult:
# engine params evaluated: 9
Optimal Engine Params:
{
"dataSourceParams":{
"":{
"appName":"MyApp2",
"evalParams":{
"kFold":5,
"queryNum":10
}
}
},
"preparatorParams":{
"":{
}
},
"algorithmParamsList":[{
"als":{
"rank":10,
"numIterations":1,
"lambda":0.01,
"seed":3
}
}],
"servingParams":{
"":{
}
}
}
Metrics:
Precision@K (k=3, threshold=2.0): 0.04000000000000001
PositiveCount (threshold=0.0): 20.013333333333332
PositiveCount (threshold=2.0): 19.319999999999997
PositiveCount (threshold=4.0): 12.386666666666667
Precision@K (k=1, threshold=0.0): 0.05333333333333332
Precision@K (k=3, threshold=0.0): 0.04
Precision@K (k=10, threshold=0.0): 0.014666666666666672
Precision@K (k=1, threshold=2.0): 0.05333333333333334
Precision@K (k=3, threshold=2.0): 0.04
Precision@K (k=10, threshold=2.0): 0.014666666666666672
Precision@K (k=1, threshold=4.0): 0.02702702702702703
Precision@K (k=3, threshold=4.0): 0.022522522522522518
Precision@K (k=10, threshold=4.0): 0.009459459459459462
[INFO] [CoreWorkflow$] runEvaluation completed
ただ、これらがどう違うのか、どういう場合にどちらを使うのが適切なのか(そしてこの実装は適切なのか……)といったところは、私の勉強不足でわからなかったので、興味がある方は調べてみていただければ幸いです。
Engine Template開発環境を作る
Recommendation Templateはあくまで「サンプル実装」なので、色々そぐわない部分があると思います。(たとえば学習用データ登録のeventが"buy"と"rating"に分かれていますが、buyを想定する必要性があまりない、など)
Dockerコンテナ内でvim等を使ってソースコードを修正してもよいのですが、ホスト環境のエディタを使えるようにした方が楽だと思いますので、参考程度にやり方をご紹介しておきます。
まずはpredictionioのコンテナを別名でcommitします。2
// predictionio用のコンテナを確認
$ docker ps -a
dd5c00c48078 predictionio "/bin/bash" 5 days ago Exited (0) 2 minutes ago predictionio_instance
// 別名をつけてcommit
$ docker commit dd5c00c48078 my-pio:terukizm
sha256:9da04b94845e2a22a02eda9166aac06ca68835ba3f188072cce4bc1b9b4547ca
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
my-pio terukizm 9da04b94845e Less than a second ago 2.55 GB
predictionio latest 2a03ed1aef2e 5 days ago 2.34 GB
ホストマシンの適当な場所に編集用のテンプレートをgit cloneしておき、docker -vでコンテナ内と共有します。ここではコンテナ内に /MyCustomRecommender として配置しています。
$ cd ~
$ git clone https://github.com/apache/incubator-predictionio-template-recommender.git
$ ls ~/incubator-predictionio-template-recommender
README.md build.sbt data engine.json project src template.json
$ docker run -p 8000:8000 -v ~/incubator-predictionio-template-recommender:/MyCustomRecommender -it my-pio:terukizm /bin/bash
あとはコンテナ内から通常のEngine Templateと同じように使えます。
# cd /MyCustomRecommender/
# ls
README.md build.sbt data engine.json project src template.json
# pio build
...
[INFO] [Console$] Your engine is ready for training.
Windowsの場合
システムトレイのDockerアイコン > Settings から以下のオプションを有効にした上で、同様にマウントしてください。
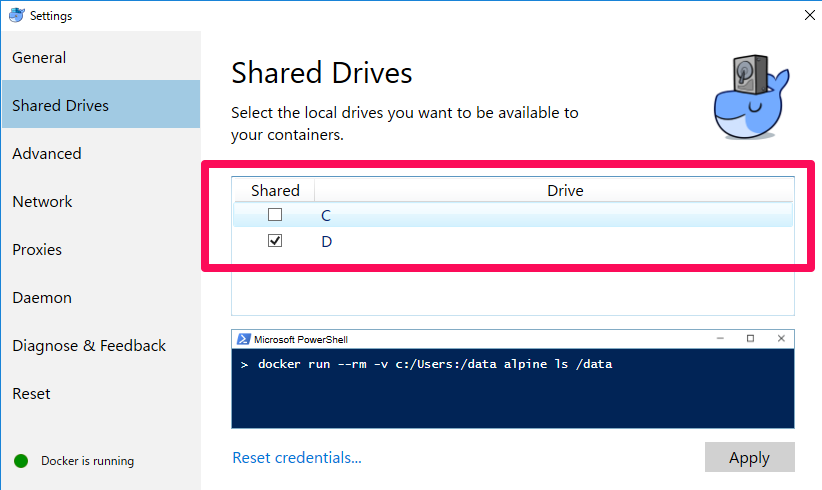
C:\>docker run -p 8000:8000 -v D:/incubator-predictionio-template-recommender:/MyCustomRecommender -it my-pio:terukizm /bin/bash
root@dce268437faa:/# ls /MyCustomRecommender/
README.md build.sbt data engine.json project src template.json
その他Tips
PredictionIOに投入されている学習用データを削除
# pio app data-delete MyApp2
pio app data-delete MyApp2
[INFO] [App$] Data of the following app (default channel only) will be deleted. Are you sure?
[INFO] [App$] App Name: MyApp2
[INFO] [App$] App ID: 2
[INFO] [App$] Description: None
Enter 'YES' to proceed: YES
「YES」と打ち込まないといけないので注意してください。(y とか yes ではだめでした)
Engine中で動いてるSparkにJVMオプション(ヒープサイズなど)を設定したい
pioサーバ起動時に以下のようにして渡すことができます。
# JAVA_OPTS="-Xms1g -Xmx2g" pio-start-all
チェックポイントを設定してSparkのスタックオーバーフローを回避する
SparkContext.setCheckpointDir()を利用します。
/* $ pio train */
def train(sc: SparkContext, data: PreparedData): ALSModel = {
+ sc.setCheckpointDir("checkpoint/")
// MLLib ALS cannot handle empty training data.
require(!data.ratings.take(1).isEmpty,
とまあ、こんな感じでなんとかRecommendation Templateを動かすことはできたのですが、これをベースにカスタマイズしていくのが正直大変で、ぶっちゃけ挫折しました…
役にたつかはわかりませんが、気が向いたらそちらもまとめておきたいと思います……