DMM.com #1 Advent Calendar 2017 の7日目を担当させていただきます、@teru855です。
前日の記事は、@sinnershikiさんの JuniperのQFX10kの仮想環境に触れる でした
これは DMM.com #1 Advent Calendar 2017 - Qiita の7日目の記事です
6日目の記事は こちらです
qiita.com
カレンダーのURLはこちら
DMM.com #2 Advent Calendar 2017 - Qiita
DMM.com #1 Advent Calendar 2017 - Qiita
はじめに
今回の記事は何を書こうかとかなり悩みましたが、今までの記事の中で一番反響のあったKaggleのコンペに提出しようと思います。
Kaggleのページ (今回参加したもの)
https://www.kaggle.com/c/mercari-price-suggestion-challenge#description
そもそも、Kaggleとは何か
簡単に言うと、
世界中のデータサイエンティスト達に、賞金をかけた難問を
解析をさせ、より高い正答率を競わせる大会です。
詳しくは多数記事が存在するので、この辺を見てください。
今回のテーマ
今回のテーマは
「メルカリの価格提案チャレンジ! 〜メルカリの販売者に出品価格を自動で提案できるかどうか〜」
です。
賞金の合計額は $100,000 と、
メルカリに就職できる権利をもらえるらしいです。
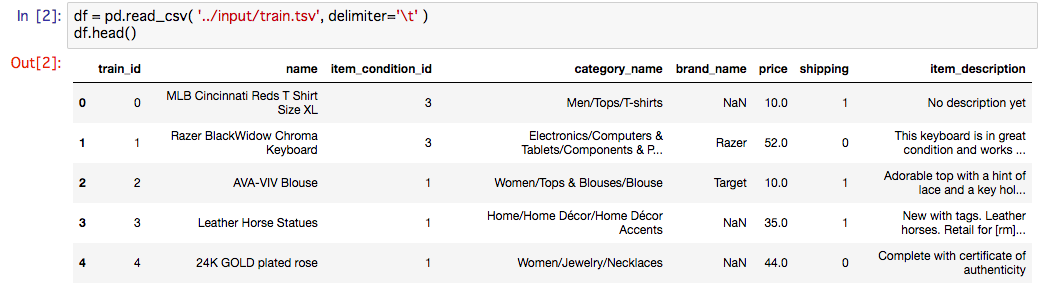
データセットの説明
今回学習、テストに使用するデータセットは以下になります。
この中に price が含まれてますが、これは今回求める値のため、trainデータ群に存在し、testデータ群には存在しない。
| カラム名 | 意味 |
|---|---|
| train_id, test_id | ID |
| name | 商品のタイトル(価格データなどは削除してあります) |
| item_condition_id | 商品のコンディション |
| category_name | 商品のカテゴリ (最大3つ) |
| brand_name | ブランド名 |
| price | 商品が販売された時の価格(ドル)で、今回求める数値 |
| shipping | 送料が出品者負担かどうか(出品者負担: 1、購入者負担: 0) |
| item_description | 商品の説明、価格情報は削除済み |
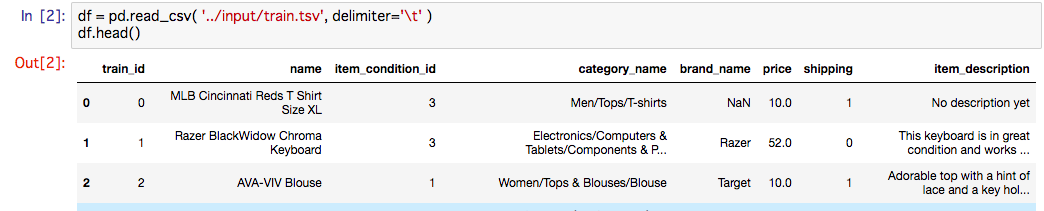
実データはこんなかんじで、文字が多めの印象です。
category_nameは最大3つ「/」で区切られており、後で自分でパースしなければなりません。
評価方法
RMSLEを用います。式はここに記述されているのでみてください。
https://www.kaggle.com/c/mercari-price-suggestion-challenge#evaluation
提出する際はこのように、[test_id, price]で、cvs形式で提出してください。
調査
それぞれのデータの状態を調べてみた
全体では、1482535のカラムが存在しする
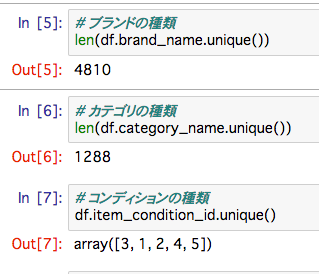
ブランドの種類: 4810
カテゴリの種類: 1288
コンディション: 1-5
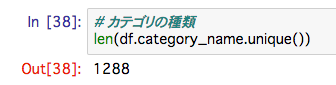
カテゴリの種類は、一見1288種類だと思われるが、それは3種類のカテゴリを合わせてであるので注意が必要です。
また、そのうちの6万は「Women/Athletic Apparel/Pants, Tights, Leggins」です。
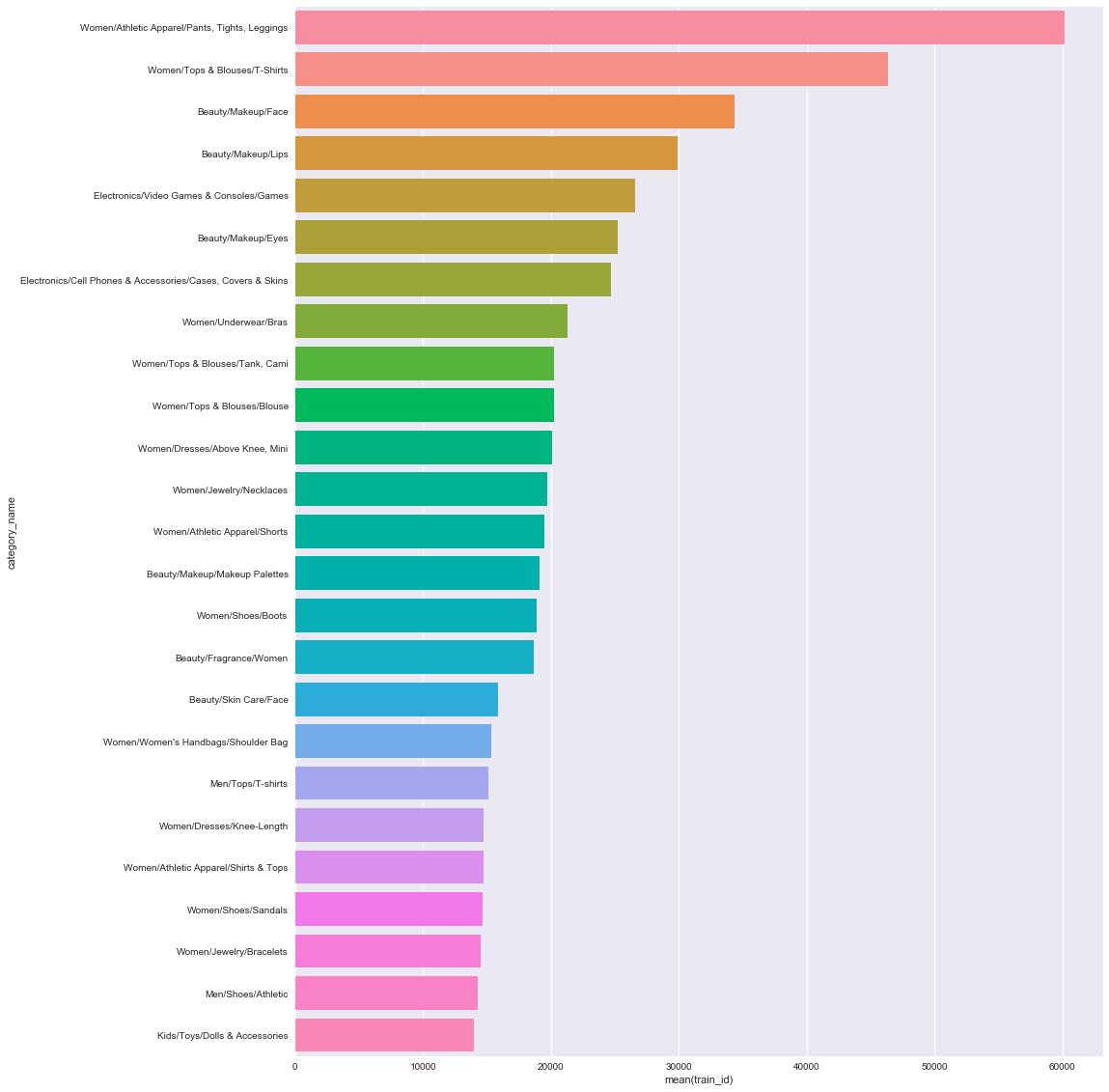
全カテゴリの種類は951種類のようです、以外と少ないですね。

手法
算出手順
文字を全て数値に置き換え、重回帰で算出します。
手法
欠損値の補正
まず、ブランド名やカテゴリ名で値が存在しないものがあり、数値的に存在しない(NaN)があったが、
数値と文字が混在するとこの後扱いづらいので文字列の"NaN"に変換した。
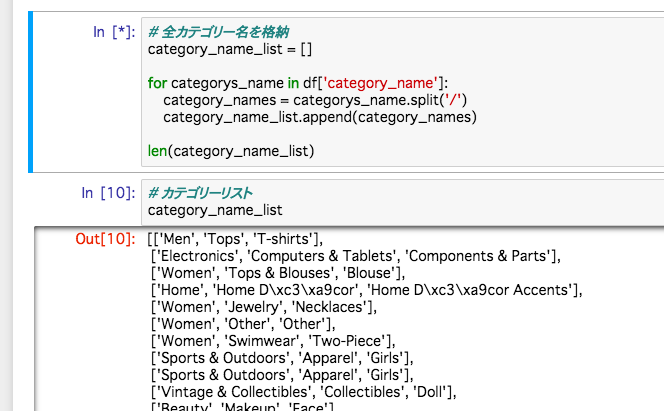
カテゴリの修正
次にカテゴリを分割する。 分割した結果は下の配列を参照してください。
分割した後、DataFrame型に変換し、文字を数値に置き換えます。
factorize 関数はその配列のユニークな文字にそれぞれ数値の1からラベルを割振る関数で、
['a', 'b', 'a', 'c'] とあったら、 [1, 2, 1, 3] と変換してくれます。
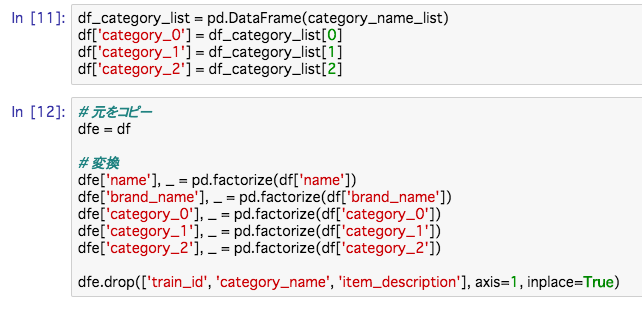
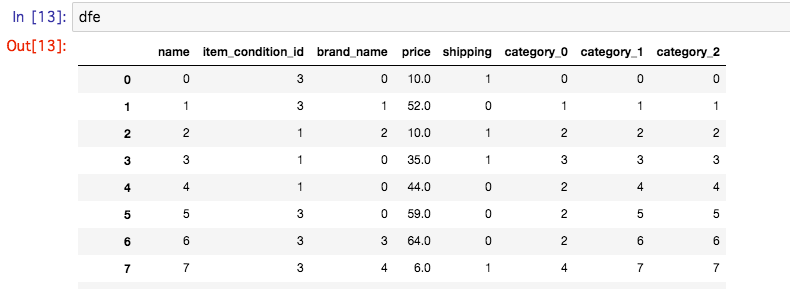
それで、値をみるとこんなかんじに変換されているのがわかります。
priceだけ、少数になってますが、これは後で修正します。
解析
相関係数
今回も最初に相関係数を算出する
相関係数については以下のwikiを参照する
https://ja.wikipedia.org/wiki/%E7%9B%B8%E9%96%A2%E4%BF%82%E6%95%B0
image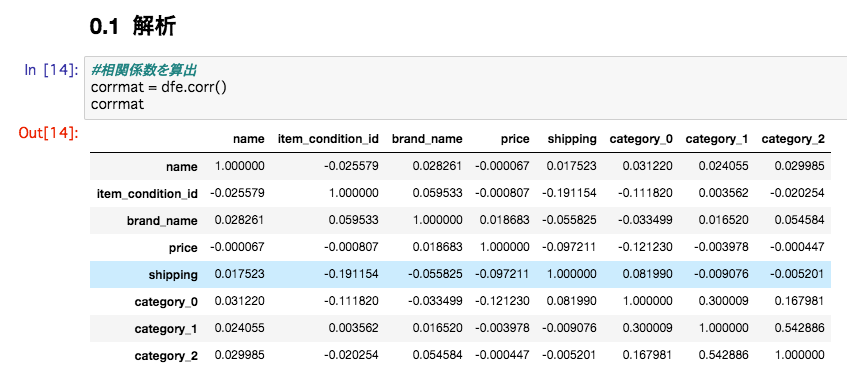
うーん、、priceと相関がありそうなのは、 shipping と、 category_0 ぐらいですね...精度が低そうです。
学習
target_list に価格を整数の配列として格納し、 data_list に価格以外の情報を、これも整数の配列として格納します。
# 引数の取得
target = dfe['price']
data = dfe
data.drop('price', axis=1, inplace=True)
data_names = data.columns
# DataFrame型から整数値のArray型にする
data_list = data.values.astype(np.int64)
target_list = target.values.astype(np.int64)
重回帰
値を重回帰で学習させます。
from sklearn import linear_model
clf = linear_model.LinearRegression()
# 説明変数として、Xに値を代入
X = data_list
# 目的変数として、Yに値を代入
Y = target_list
# 予測モデルを作成
clf.fit(X, Y)
# 偏回帰係数
print(pd.DataFrame({"Name":data_names,
"Coefficients":clf.coef_}).sort_values(by='Coefficients') )
結果確認
RMSLEではなく、簡単に実装できる RMSEを用いた。
うーん...全然よくない...
相関係数で全く相関が出てなかったのが頷けます...

まとめ
trainをこの後、上記の手法で提出しましたが、やはり悪かったです。
また、重回帰ではなく、RandomForestも試してみましたがあまり精度がかわらなかったで、そもそもパラメータがよくなかったと思われ、改善点を以下にあげてます。
- カテゴリ情報を分割し、格納した際に、格納する順序に重きを置いていなかった ([A, B, C]と[B, A, C]は別物として扱った)ためそもそも学習ができなかった →ソートすればよかった?
- 一番重要な情報である名前と説明文を完全に捨てた事
- 文字情報を全て無視して、文字情報そのものに大小関係が存在しないにもかかわらず全て数値に置き換えたため、学習がうまくいかなかったこと
などがあげられると思われる。
特に文字情報は word2vec などを用いれば飛躍的情報量が増えると思われるため導入を検討しようとおもいます。
終わりに
今回はKaggleに短時間で提出するという目的を果たしたのでよかったが、成果があまりにもよくなかったので、そもそものパラメータの見直しが必要だと思われます。
Kaggleは、会社でどうしても解きたい問題をコンペという形で世界中のデータサイエンティストに解かせることができることができるサービスですが、
今回参加して、データサイエンティストを3人雇って半年で成果をあげさせるよりも、コンペという形で一千万円の賞金をかけさせた方が安く、より早く目的の学習機や人材を集める事ができる新しい形だと強く感じました。
明日は、@anbhtsさんが書いてくれます