Apache Spark 1.6から新しく追加されたDataset APIを試してみる。
2015/12/14現在まだリリースされてないが、年内中にはリリースされるはず。
背景
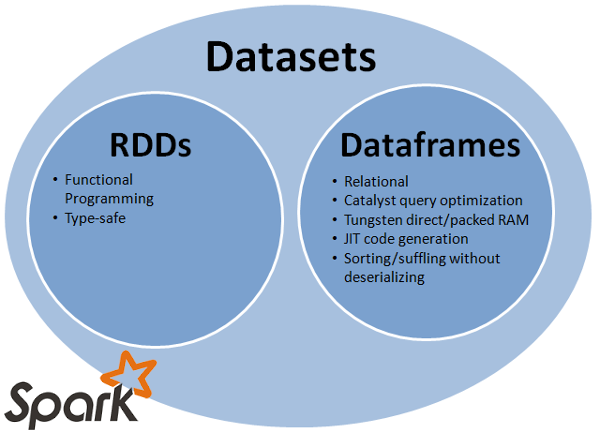
- RDDはLow Level APIで、としてフレキシブルだが、最適化が難しい
- (Spark 1.3から登場した)DataFrameはHigh Level APIでオプティマイザーが最適化してくれるが、フレキシブルさがない。特にUDFの使い勝手が不便なところや型チェックに弱い
Dataset API 登場
- 上記の問題を解決するためにSpark 1.6から実験的(Experimental)に登場したのがDataset APIである
- RDDとDataFrameの良いところを併せ持つAPIとして開発されています。つまり、早くて使い勝手のよいAPIだと言えます。
画像はhttp://technicaltidbit.blogspot.jpより
Dataset APIの要件定義は SPARK-9999 に詳しく書かれてる通り、大きく下記の4つになります。
Fast
Typesafe
Java Compatible
Interoperates with DataFrames
Let's give it a try
Spark 1.6.0 ダウンロード
解凍後に、/usr/local/spark-1.6.0 へコピー
Sparkソースに同胞されてるファイルを使って比較してみる
/usr/local/spark-1.6.0/bin/spark-shell 起動
// 各自のパスを合わせて設定
scala> val peopleFile = "/usr/local/spark-1.6.0/examples/src/main/resources/people.json"
// JSON → DataFrame
scala> val df = sqlContext.read.json(peopleFile)
df: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
// 中身確認
scala> df.printSchema
root
|-- age: long (nullable = true)
|-- name: string (nullable = true)
scala> df.show
+----+-------+
| age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+
// Datasetを使うため、case class 定義
scala> case class Person(age: Long, name: String)
// DataFrameからDatasetに変換
scala> val ds = df.as[Person]
ds: org.apache.spark.sql.Dataset[Person] = [age: bigint, name: string]
// DataFrameでの20歳以上の人を取得
// DataFrameは行列計算に特化したフレームワークなので、カラム名を指定する必要がある
scala> df.where($"age" >= 20).show
+---+----+
|age|name|
+---+----+
| 30|Andy|
+---+----+
// Datasetでの20歳以上の人を取得
// DatasetはDataFrameのRowをJVMオブジェクト(この例ではPerson)として扱えるため、UDFが適用が簡単
scala> ds.filter(_.age >= 20).show
+---+----+
|age|name|
+---+----+
| 30|Andy|
+---+----+
// Dataset → DataFrame
scala> val df2 = ds.toDF
df2: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
// Dataset → RDD
scala> val rdd = ds.rdd
rdd: org.apache.spark.rdd.RDD[Person] = MapPartitionsRDD[121] at rdd at <console>:33
// 少し複雑な処理(年代別人数集計)
scala> import org.apache.spark.sql.types._
// DataFrameの場合
scala> :paste
df.where($"age" > 0)
.groupBy((($"age" / 10) cast IntegerType) * 10 as "decade")
.agg(count($"name"))
.orderBy($"decade")
.show
+------+-----------+
|decade|count(name)|
+------+-----------+
| 10| 1|
| 30| 1|
+------+-----------+
// Datasetの場合
scala> :paste
ds.filter(_.age > 0)
.groupBy(p => (p.age / 10) * 10)
.agg(count("name"))
// orderByがないようなので、DFへ変換(これはやや不便)
.toDF().withColumnRenamed("value", "decade").orderBy("decade")
.show
+------+-----------+
|decade|count(name)|
+------+-----------+
| 10| 1|
| 30| 1|
+------+-----------+
他の例はdatabricksサイトを参考にしてください
Dataset API以外のSpark1.6.0についてはこちら
まとめ
- Dataset APIはRDD-likeに使えてDataFrameのパフォーマンスの利点も活かせる
- DataFrameやRDDへ簡単も変換できる
- まだ安定版ではないため、足りないファンクションもあるけど、今後に期待