はじめに
前回、Vulkan初期化の第一歩としてVulkanインスタンスを作りました。今回は第2歩目として、物理デバイスのクエリを行います。
OpenGLESでは、「どんなGPUが何個搭載されているか」といった物理デバイス構成について何も意識する必要はありません。これは初期化の手間が省ける反面、描画実行にどのGPUを稼働させるかの選択をOpenGLESに権限移譲することを意味します。システムに接続されるGPUは1つだけ、という想定のもとではそれで充分でした。
一方、GPUを複数搭載し、より高負荷な処理を行わせることを目的としたシステムでは、「どのGPUにどんなタスクをいつ割り当てるか」を細かく制御することができれば、システム性能をさらに改善することが可能となります。
なお、GPUを複数搭載したシステムは珍しいものではなく、組み込みの世界でも、nVIDIAのDrivePXのような例があります。
Vulkanでは、システム性能を最大限引き出すために、「システムに接続された物理デバイスの能力」をアプリ開発者が収集し、活用することを求めています。
注)EXT_device_base拡張をサポートしている環境であれば、OpenGLESでも明示的にGPUを指定可能です。
Vulkanにおける2つの「デバイス」
Vulkanには、2つの「デバイス」という用語があります。
| デバイスの種類 | 説明 | 補足 |
|---|---|---|
|
物理デバイス VkPhysicalDevice |
システムに接続された実ハードウェア | GPU1個が物理デバイス1個。 ※SLI接続されたグラボは、1つの大きな物理デバイスとみなされる |
|
論理デバイス VkDevice |
物理デバイスを抽象化し、APIで操作可能にしたデバイス | 物理デバイスと論理デバイスとは必ずしも1対1ではない |
| 処理の流れは、下記の通りです。 | ||
| 1)物理デバイスの情報を収集し、目的にあった物理デバイスを選択する | ||
| 2)その物理デバイスをラッピングする形で論理デバイスを作成 | ||
| 3)以降、論理デバイスに対して操作要求 |
今回は、1)の物理デバイスの生成までをやります。
物理デバイス情報の収集
それでは物理デバイスの情報を取得していきます。
vkEnumeratePhysicalDevices
vkEnumeratePhysicalDevices()関数で、物理デバイスのハンドルを取得します。1回目の呼び出しで個数を取得し、2回目の呼び出しでその個数分のハンドルを一気に取得します。
VkInstance vk_instance;
uint32_t gpu_count;
VkPhysicalDevice *phydev_array;
vkEnumeratePhysicalDevices(vk_instance, /* [in ] VKインスタンス */
&gpu_count, /* [out] 物理デバイス数が格納される */
NULL); /* [out] VkPhysicalDeviceハンドルが格納される */
phydev_array = malloc(sizeof(VkPhysicalDevice) * gpu_count);
vkEnumeratePhysicalDevices(vk_instance, /* [in ] VKインスタンス */
&gpu_count, /* [out] 物理デバイス数が格納される */
phydev_array); /* [out] VkPhysicalDeviceハンドルが格納される */
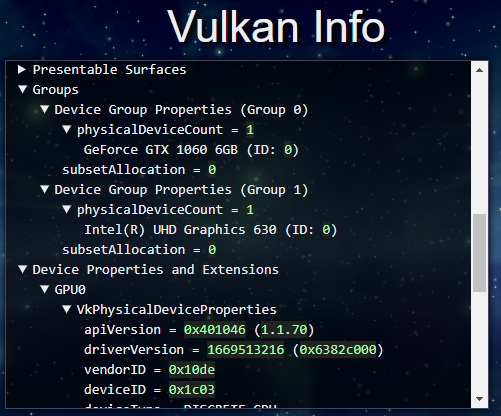
私の環境では、gpu_count=2 となりました。Core i7 内蔵GPUと、グラボGPUとがカウントされているようです。
vkGetPhysicalDeviceProperties
取得した物理デバイスのハンドルを人間が見てわかる情報に変換していきます。
for (i = 0; i < gpu_count; i ++)
{
phydev = phydev_array[i];
VkPhysicalDeviceProperties dev_props;
vkGetPhysicalDeviceProperties(phydev, /* [in ] Vulkan物理デバイスのハンドル */
&dev_props); /* [out] Vulkan物理デバイス情報が格納される */
fprintf(stderr, "================ VulkanPhysicalDevice[%d/%d] ================\n", i, gpu_count);
fprintf(stderr, "%s\n", dev_props.deviceName);
fprintf(stderr, "apiVersion = %d.%d.%d\n",
VK_VERSION_MAJOR(dev_props.apiVersion),
VK_VERSION_MINOR(dev_props.apiVersion),
VK_VERSION_PATCH(dev_props.apiVersion));
/* for文は下に続く */
デバイス名とAPIバージョン番号を表示させています。
実行結果は、下記です。
================ VulkanPhysicalDevice[0/2] ================
GeForce GTX 1060 6GB
apiVersion = 1.1.70
================ VulkanPhysicalDevice[1/2] ================
Intel(R) UHD Graphics 630
apiVersion = 1.0.50
Core-i7内蔵GPUの存在なんてすっかり忘れていたのですが、きっちりVulkan対応しているとのこと。
私の環境でのAPIバージョンをまとめると次の通りです。
| 項目 | バージョン |
|---|---|
| インスタンス | 1.1.0 |
| GeForce GTX 1080 | 1.1.70 |
| Intel(R) UHD Graphics 630 | 1.0.50 |
このように、デバイスごとにapiVersionが異なることの注意が必要です。たとえVulkanインスタンスのバージョンが Vulkan 1.1 でも、実際に接続されている物理デバイスは Vulkan 1.0 のAPIしか使えないこともある、という実例です。
Queueファミリ
GPUに仕事を依頼するには、描画用コマンドやコンピュート用コマンド、メモリ転送用コマンド等、様々なコマンドをキューに並べてGPUに仕事を依頼します。OpenGLESでは、すべてのコマンドを1本のキューに登録し、仕事を順にひとつずつ実行させています。
一方、GPUアーキとしては「描画用コマンドとメモリ転送用コマンドは同時実行可能」というように、並列性を高めたものもあります。しかし、全ての仕事が1つのキューに並んでいると、前の仕事が終わるまで次の仕事を始めることができず、せっかくの並列性が活かせません。
Vulkanでは、コマンドキューを、Queueファミリ として分類することで、並列性を高めることができるようになっています。具体的には、「なんでも登録できるキュー」「コンピュート用コマンドしか登録できないキュー」「メモリ転送用コマンドしか登録できないキュー」のように、キューに登録可能なコマンド種別ごとに分類することで、並列実行可能なキューを明示的に分離し、それぞれ別に管理します。
vkGetPhysicalDeviceQueueFamilyProperties
Queueファミリ情報は、vkGetPhysicalDeviceQueueFamilyProperties()で取得します。例のごとく、1回目の呼び出しで個数を取得して、2回目の呼び出しで情報取得します。
uint32_t qfamily_count;
VkQueueFamilyProperties *queue_props;
vkGetPhysicalDeviceQueueFamilyProperties(phydev, &qfamily_count, NULL);
queue_props = (VkQueueFamilyProperties *)malloc(qfamily_count * sizeof(VkQueueFamilyProperties));
vkGetPhysicalDeviceQueueFamilyProperties(phydev, &qfamily_count, queue_props);
for (j = 0; j < qfamily_count; j++)
{
fprintf(stderr, "QueueFamily[%d/%d] queueFlags:", j, qfamily_count);
if (queue_props[j].queueFlags & VK_QUEUE_GRAPHICS_BIT) fprintf(stderr, "GRAPHICS ");
if (queue_props[j].queueFlags & VK_QUEUE_COMPUTE_BIT ) fprintf(stderr, "COMPUTE ");
if (queue_props[j].queueFlags & VK_QUEUE_TRANSFER_BIT) fprintf(stderr, "TRANSFER ");
if (queue_props[j].queueFlags & VK_QUEUE_SPARSE_BINDING_BIT) fprintf(stderr, "SPARSE ");
if (queue_props[j].queueFlags & VK_QUEUE_PROTECTED_BIT) fprintf(stderr, "PROTECTED ");
fprintf(stderr, "\n");
}
実行結果は下記の通り。
nVIDIAグラボはQueueファミリが3つ。それぞれ「何でも登録可能」「メモリ転送のみ」「コンピュートのみ」。
Intel GPU は「何でも登録可能」なQueueファミリが1つでした。
================ VulkanPhysicalDevice[0/2] ================
GeForce GTX 1060 6GB
apiVersion = 1.1.70
QueueFamily[0/3] queueFlags:GRAPHICS COMPUTE TRANSFER SPARSE
QueueFamily[1/3] queueFlags:TRANSFER
QueueFamily[2/3] queueFlags:COMPUTE
================ VulkanPhysicalDevice[1/2] ================
Intel(R) UHD Graphics 630
apiVersion = 1.0.50
QueueFamily[0/1] queueFlags:GRAPHICS COMPUTE TRANSFER SPARSE
次回以降、論理デバイス を作成しますが、その際「どのQueueファミリを使うか」の指定が必要になります。Vulkanで描画を行うには、「描画用コマンドを登録可能」なQueueファミリを指定する必要があるので、覚えておきましょう。
その他デバイス情報収集
他にも複数のQuery関数により、デバイスに関する様々な情報を取得できます。
LunarGのVulkan SDKのデモアプリである vulkaninfo は、デバイス情報をわかりやすいHTMLで出力してくれる機能があるので、それを眺めるのも楽しいです。
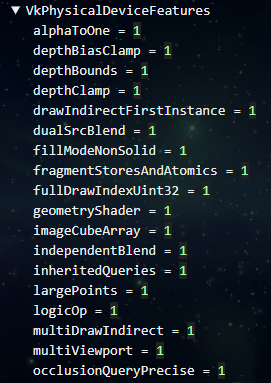
vkGetPhysicalDeviceFeatures
デバイスで使える機能をさらに細かく取得するには vkGetPhysicalDeviceFeatures()を使います。
VkPhysicalDeviceFeatures physDevFeatures;
vkGetPhysicalDeviceFeatures(phydev, &physDevFeatures);
ジオメトリシェーダやテセレーションシェーダが使えるのかといったOpenGLESにも馴染みのある情報が取得できます。OpenGLESでは、そのバージョン番号によって使える描画機能が保証されていますが、Vulkanの場合は、このFeature情報を取得して使える機能を確認する必要があるのですね。
vkGetPhysicalDeviceFormatProperties
使用可能なカラーフォーマット情報を取得します。
ただし、取得可能なフォーマットの一覧がわらわらと取得できるようなAPIではなく、「このフォーマットに関する情報ちょうだい」と問い合わせると、「使える」「使えない」が返ってくるAPI仕様になっています。
vkGetPhysicalDeviceMemoryProperties
使用可能なメモリ情報を取得します。
vkEnumerateDeviceExtensionProperties
デバイスごとに使えるExtensionも違うはずなので、調べましょう。
vkEnumerateDeviceExtensionProperties() も2段階で呼び出します。
uint32_t ext_count;
VkExtensionProperties *ext_prop;
vkEnumerateDeviceExtensionProperties(phydev, NULL, &ext_count, NULL);
ext_prop = malloc(ext_count * sizeof(VkExtensionProperties));
vkEnumerateDeviceExtensionProperties(phydev, NULL, &ext_count, ext_prop);
for (j = 0; j < ext_count; j++)
{
fprintf(stderr, "[%2d/%2d] %s (%d)\n",
j, ext_count, ext_prop[j].extensionName, ext_prop[j].specVersion);
}
参考までに、Extension数を書いておきます。
| 物理デバイス | Extensionの数 |
|---|---|
| GeForce GTX 1080 | 53 |
| Intel(R) UHD Graphics 630 | 13 |
情報取得関数の拡張性
OpenGLES でこれらの情報取得を行う場合、取得したい項目ごとに eglQueryString() や glGetXXX()をチマチマ呼び出す必要がありました。これに対し、Vulkanでは、vkGetPhysicalDeviceProperties() 関数をはじめとして、複数の情報が1つの構造体 にパッキングされて取得できるので便利です。
が、ふと疑問がわきます。
将来の機能拡張で、取得したい情報が増えたらどうするんだろう。
例えば、vkGetPhysicalDeviceProperties() で取得する VkPhysicalDeviceProperties構造体のメンバを増やしたくなったらどうするんでしょうか。この構造体には、sType で構造体の識別子を指定するメンバもないので、互換性を維持したままメンバを増やすのは困難に思えます。
実はその答えはすでに用意されています。
vkGetPhysicalDeviceProperties2() という名の、拡張性を持たせた別APIが定義されています。
VkPhysicalDeviceProperties2 dev_props2;
vkGetPhysicalDeviceProperties2(phydev, /* [in ] Vulkan物理デバイスのハンドル */
&dev_props2); /* [out] Vulkan物理デバイス情報が格納される */
API構文は、バージョン1と同じなのですが、引数で渡す構造体が変更されています。
typedef struct VkPhysicalDeviceProperties2 {
VkStructureType sType;
void* pNext; /* 取得したい情報をチェーンでつなぐ */
VkPhysicalDeviceProperties properties; /* version1の構造体を内包 */
} VkPhysicalDeviceProperties2;
構造体をチェーン接続することで、将来の拡張性にも対応できるようにしています。
なお、チェーンを作るのはVulkanライブラリではなくアプリの仕事です。vkGetPhysicalDeviceProperties2() を呼ぶ前に、アプリで空の構造体チェーンを作って、それを引数で渡さないといけません。サンプルコードは一番下のリンクにあります。
今回のまとめ
Vulkanで物理デバイスの様々な情報を取得しました。nVIDIAのグラボとIntel内蔵GPUの情報が何の隔たりなく統一的に取得できることに今更ながら便利だなと感じました。次回は 論理デバイスの作成をする予定です。
ソースコード
https://github.com/terryky/VulkanSample
上記の 002_QueryPhysicalDevice