株式会社オズビジョンのユッコ (@terra_yucco) です。
FF14 5.4 パッチが来ており、幻と極は終わったものの、零式はまだ折り返し地点です。
ギミック処理の最適化と同じように業務の最適化もできればなあと思う今日このごろです。
今回の要点
業務で触った BigQuery Scripting がとても便利だったので、簡単な(でもちょっとした更新も伴うような)SQL 要件であればぜひ使ってほしい!という紹介記事。
BigQuery Scripting とは
BigQuery の Query Editor にいろいろな Query を書くにあたり、以下のような制御が行えるようになる機能です。
- 頻出値を変数に入れる
- 特定の SQL の結果次第で条件分岐ができる
- ループ処理ができる
- エラー発生時の処理も書くことができる
変数
以下のようにすると、変数 today に、Asia/Tokyo 時間の今日の日付が入ります。
以降は select today とかで普通に使うことができます。
※ただし後述の「エラー処理」の項目で EXCEPTION WHEN ERROR THEN の中には書けておらずエラーになるので、Create されるデータをすべて同じ条件で参照できるようにし、エラーの際にまとめて消すようなことはまだ実現できていません。(もちろん値をベタで記載すれば対応できます)
DECLARE today DATE DEFAULT CURRENT_DATE('Asia/Tokyo');
条件分岐
もちろん通常の SQL 文の範囲の IF も使えます。(テーブルがなければ作成する)
CREATE TABLE IF NOT EXISTS test.data_per_user
(
data_day DATE NOT NULL,
uid INT64 NOT NULL,
max_action_day DATE NOT NULL,
register_date TIMESTAMP NOT NULL
);
上記に続けて以下のような SQL を書くと、テーブルにすでに今日の分のデータがあれば、INSERT SELECT が行われません。
今日の分のデータがないときだけ、集計が行われてデータが入ります。
IF (SELECT count(1) FROM test.data_per_user WHERE data_day = today) = 0 THEN
INSERT INTO test.data_per_user
SELECT today,
uid,
ifnull(
DATE(TIMESTAMP(FORMAT_TIMESTAMP('%Y-%m-%d %H:%M:%S', max(action_date), 'Asia/Tokyo'))),
DATE(TIMESTAMP(FORMAT_TIMESTAMP('%Y-%m-%d %H:%M:%S', max(register_date), 'Asia/Tokyo')))
) max_action_day,
CURRENT_TIMESTAMP register_date
FROM test.source_data
WHERE {some conditions}
GROUP BY uid;
END IF;
ループ処理
今回の処理では利用しなかったので割愛。
公式ドキュメントは充実しています。
https://cloud.google.com/bigquery/docs/reference/standard-sql/scripting#loops
エラー処理
以下のように書くことで、Query1..2 内でエラーが発生した場合などに処理を走らせることができます。
BigQuery は RDBMS ではないので、この BEGIN にいわゆるトランザクション開始みたいな機能はありません。
一貫性はクエリ単位では担保されるので、以下のような構造の Query1 で失敗した場合にはデータは何ら変更されませんが、Query2 で失敗した場合には Query1 による C(Create) 結果は残ったままになります。
そのため、エラーハンドリングで Query による作成結果を消すようにしておくと、トランザクションが張ってあるのに近い動きをさせられるのかなと考えています。テーブル構造やデータの持ち方も、RDBMS とは違う考え方が求められそうだと感じました。
EXCEPTION 内部ではエラー内容の表示もできるようなので、API 経由で BigQuery を利用する場合には有用な情報となりえそうでした。
※今回は GCP 上の Query Editor を利用していたので、エラーはその場で確認できており、そこまで実装していませんでした。
BEGIN
// Query1 (C)
// Query2 (C)
EXCEPTION WHEN ERROR THEN
// Error handling (D)
END;
他にも
エラーを発生させられる RAISE や、プロシージャを呼び出せる CALL などもありますが、いずれも利用はしませんでした。
シンプルな集計の処理であれば、IF を利用したちょっとした条件分岐をはさみながら INSERT SELECT を繰り返していくだけで作れそうです。
バッチ処理として実装したらすごく工数掛かりそうだったものが、BigQuery Scripting を活用すればかなり省工数で実装できそう。
今回の実背景
要件
- もとからあるデータから〜〜な値を出したいので、集計処理を作って
- 後から参照するかもしれないので、中間結果もどこかに取っといて
- データの種別によって、演算種別が変わるので、そこも考慮して
- 一日一回は値を更新してね
- 結果自体は内製管理画面に持って来る必要はなく、re:dash で表示できれば OK
検討
PHP ベースのバッチとして作ろうとして検討したらすごいことになった。
- 何箇所か激重いSQLがあって、日次処理として回せるイメージが沸かない(30分しても返ってこない)
- 実装・テストを含めると工数もまあまあ掛かりそう
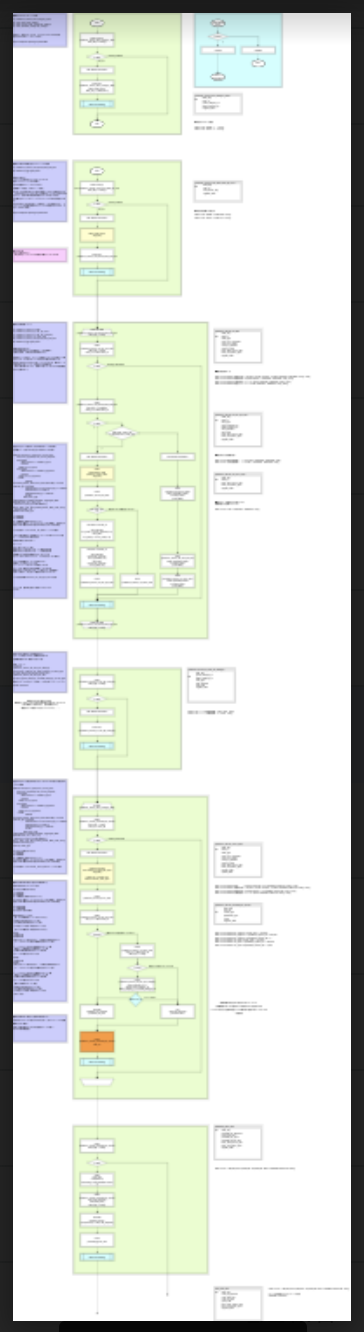
全体像もともかく、なかなか壁が大きいなあと感じたのがおわかりいただけただろうか。
BigQuery Scripting にした場合
MySQL で 30 分待ちだった Query が秒で返ってきました。
また、先にフローをしっかり作っていたのが良かったのですが、概ね 700 行弱の SQL で上記を実装できました。所要時間は 2 日程度です。
700 行といっても読みやすいようにフォーマットを整えたのと、全てを INSERT SELECT で回せるように組み上げたため、発行 SQL は DML で 13 本です。(冪等性と関連構造を全てコードに載せるため、CREATE TABLE を必要なテーブル分だけ、IF NOT EXISTS 付きで発行させています)
課題
コードのバージョン管理と、テストをどう行うのかという課題は残っています。
おそらく前者は Project Query で作成するのをやめて View にして、GitHub にいくつかある方式で連携させることになるのでしょう。
テストについては、向き先のテーブルを切り替えるような仕組みを用意した上で、想定のインプットを用意して想定のアウトプットになっているかを確認する方針になりそうです。
総括
条件分岐があり、中間結果・最終結果を保存するような集計処理でも、BigQuery Scripting を利用するとお手軽にサーバレスで実装することができます。
プロダクトに組み込むにはいくつかの課題がありそうですが、ドメイン知識を持った人が使えば、ある程度複雑な集計なども簡易に作ることができるので、計測などの場面ではぜひお役立ていただければと思いました!