イマドキWebサービスの監視について考えてみるのエントリで、メインプロダクトの監視を2016年下期に実施する、と書きました。
今期この仕事が私のメイン業務になったのには理由がありまして、2014年4月から片手間ではありますが、自己流でNagiosの監視をメインプロダクトに実装していっていたという実績があるためです。
このエントリでは、その3年弱のTipsを数点、共有したいと思います。
2016/11/01時点では4点です。
メール通知は読まれない
- Slackに発火させるのが一番気づきやすい
全然技術的な話ではないですが、ほんとに一番大きい気付きです。
全社でコミュニケーションにHipChat/Slackを使うようになった現在、
メールの伝達力の低さには目を見張るものがあります。
(「メール送ったから見といて」ってChatで来るのが日常茶飯事です)
AWSに特化した仕組み大事
AWSをはじめとしたクラウドの特徴として、以下2点を実感しました。
- サーバは使い捨てでいろいろなものが固定じゃない
- クラウドリソース特有の監視の方法がある
なので、以下のような仕組みを作りました。
(あれ、書いたら3行におさまった)
- 定期的に、runningのEC2一覧を取る
- EC2一覧を元に、Nagiosでの名前解決用にhostsファイルを作る
- EC2に付けられたTagをベースに、テンプレートからcfgを作成してnagiosをreload
この処理はNagios ServerでCronで動かしています。
ちょっと一般公開できない部分がありそうなのですが、ある程度の工夫はしているので、
できるだけ自社プロダクトに依存した部分を除去した上でいつかは公開したいなと…!
(ただ公開したころにはNagiosは化石かもしれません)
メリット
- インスタンスID(可変)指定でないと取れない値を動的に監視できる
- EC2一覧取得時に、インスタンスIDとインスタンス名(Name Tag)を取得すれば紐づけられるため
デメリット
- Nagiosの設定ファイルだけ追っているとわからない部分ができる
- 今困っていること
- client側の監視設定(nrpe.cfg)の世代管理
- 全てserver側のリポジトリ管理にしてデプロイの度にCIから配るのが現実的か?
監視項目の過不足を無くすの大事
※この項目についてはまだベストプラクティスは得られていません。
最初はNagiosになれる目的もあり、サンプルに書いてある項目を全部実装していたので、
サーバの死活監視でもPingが走り、個別定義のチェック側でもPingが飛んでいたりしました。
また、Webのフロントアクセスのチェックと、Httpdの死活監視が両方入っていたりしました。
当たり前ですがこの辺、1ヵ所何か起こるとアラートの数がものすごいことに。
独自のPluginを作成する方法
-
戻り値
- 0: 正常(OK)
- 1: 警告(WARNING)
- 2: 障害(CRITICAL)
- 3: 不明(UNKNOWN)
-
標準出力
- 何かを1行出力すること
- echo '
<TEXT OUTPUT>|<OPTIONAL PERFDATA>'
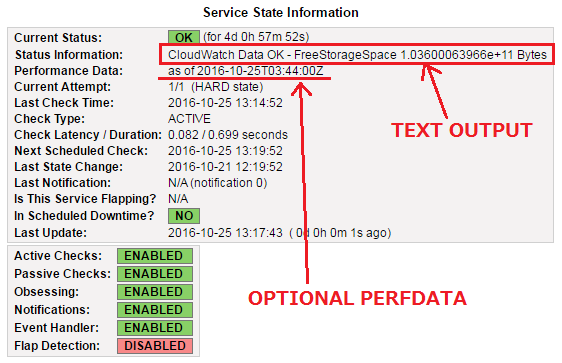
-
サンプルコード
### after validate and check
if [ ${val} -ge ${critical_threshold} ]; then
echo 'CRITICAL - val=[${val}]|<detail...>'
exit 2
fi
echo 'OK - val=[${val}]|<detail...>'
exit 0
- その他
- 上記を満たすなら、実装言語は何でも良い
- 現職では主にbashを利用
最後に
根強いZabbix、国産のエースMeckerel、AWS連携を詠ったNew Relicなど、
色々な対抗馬がある中、Nagiosも十分高機能ですし、まだまだその性能を全部は使えていません。
Error HandlerやFlapping Detectionなど、設定も徐々にブラッシュアップして、良き監視ライフを送りたいものです。
おしまい。