年末年始暇ですね。
暇つぶしに何か作ろうと思ったんですが、何も思いつかず。。。
普段AngularやNestJSでTypescriptばっかり書いてますが、たまにはJavascriptでも書いてみようと思いました。
とりあえずWebページのスクレイピングってやったことないからJavascriptで書いてみるかーということでしょうもないツールを作ってみました。
(2022/03/05追記)
GUI版も作りました
作ったもの
WebページのURLを指定すると、そのページ内のimgタグの写真をすべてダウンロードするコマンドラインツールです
img-downloader
使い方
- nodeコマンドで
img-downloader.jsを実行します - 引数に対象のWebページURLを指定します
npm install
node img-downloader.js {web-page-url}
結果
-
output/{YYYYMMDDhhmmss}ディレクトリに画像が出力されます
実行例
以下のページから画像を取得してみます
https://www.irasutoya.com/2018/12/blog-post_676.html
node img-downloader https://www.irasutoya.com/2018/12/blog-post_676.html
↓ 実行
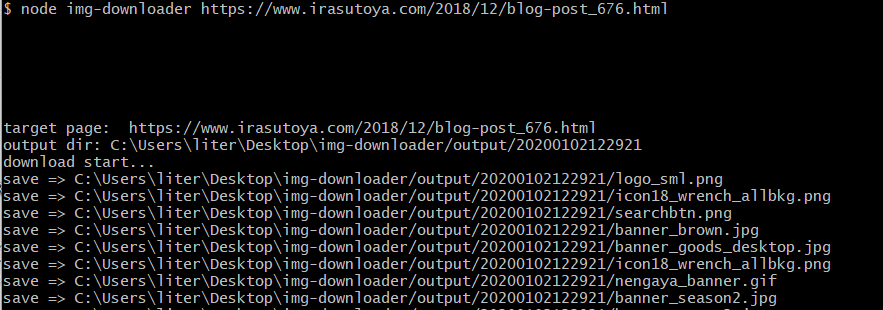
↓ 出力
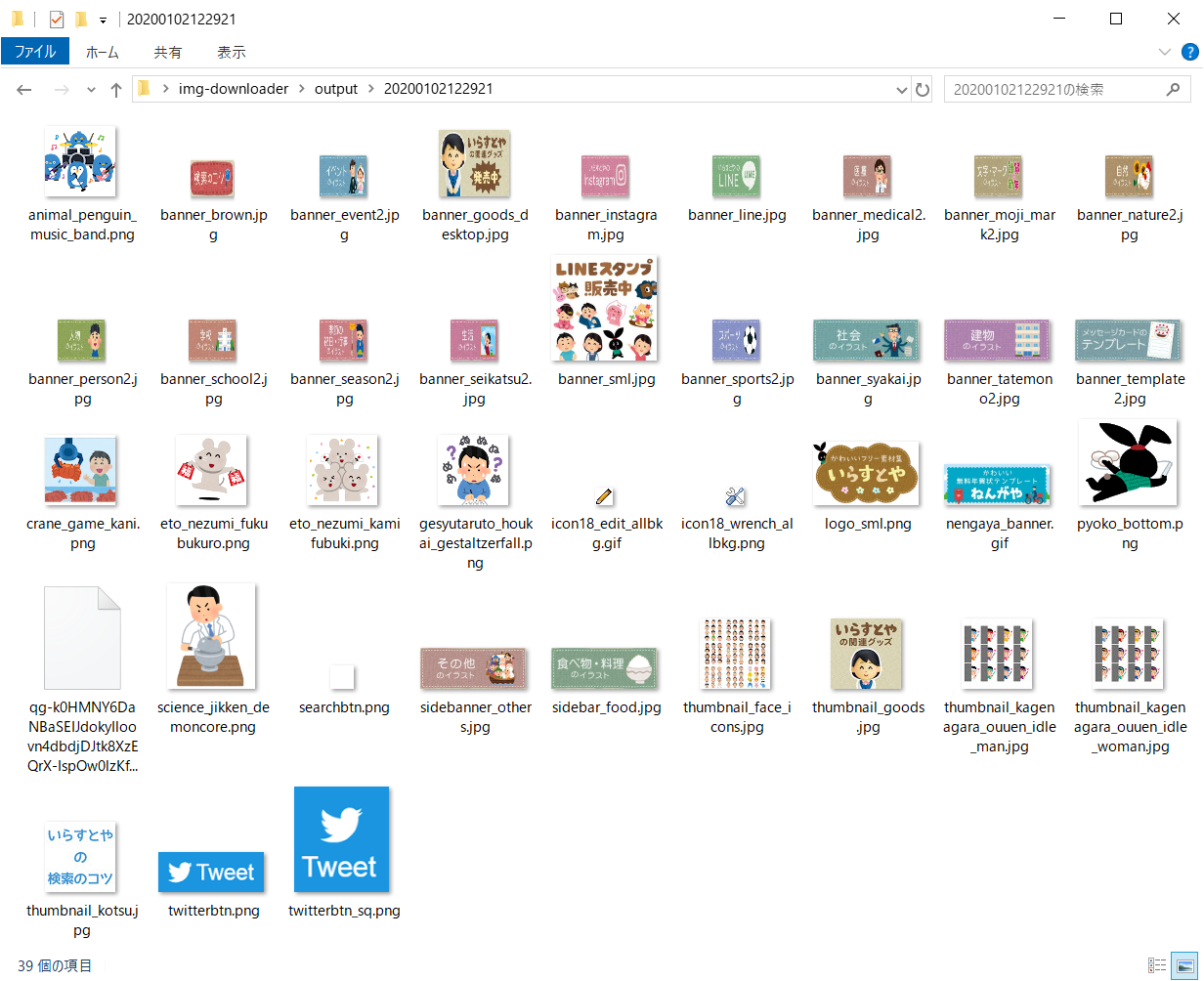
指定したページ内の全画像をとってくるので、ロゴやバナーの画像なんかの意図しない画像も取れてしまうのが難点です。。。
技術的な話
すごいシンプルなJavascriptで書いてます。
ほんとはスクレイピングも自前でやろうかと思ったんですが、めんどくさくなってscraperjs使っちゃいました。。
使ってるパッケージ
スクレイピング
scraperjsを扱うためのUtilクラスを作りました。
getTargetImgURl()で指定URLからimgタグのsrc属性をピックアップします。
class ScraperUtil {
getTargetImgUrl(pageUrl) {
return this.scrape(pageUrl, ($) => {
return $('img').map(function () {
return $(this).attr('src');
}).get();
});
}
scrape(pageUrl, fnScraping) {
return new Promise((resolve, reject) => {
scraperjs.StaticScraper.create(pageUrl)
.scrape(($) => fnScraping($))
.then(items => resolve(items))
.catch(err => reject(err));
});
}
}
簡単にスクレイピングできて良いですね。
画像のダウンロード
src属性に指定された値によってダウンロード方法が変わります
URLの場合
- requestパッケージで画像データをGET
- GETしたデータをfsパッケージのwriteFileSyncでファイル出力
- ファイル名はURLから取得
BASE64データの場合
data:image/xxx~で始まる文字列の場合、BASE64データが指定されていると判断し、以下のように出力しています。
- str.match()で
data:image/xxxx;base64,を抽出 - 上記で抽出した文字列を除いた文字列(画像データ)をBASE64デコード
- ブラウザ上でないとwindow.atobは使えないため、Bufferを使ってデコードしています
- fsパッケージのwriteFileSyncでファイル出力
- ファイル名は
raw{cnt}.{type}で出力 - typeは上記で抽出した文字列の画像タイプ(xxxxの部分)を指定
- ファイル名は
最後に
休みボケの中で適当に書いているため、突っ込みどころ満載なコードになってしまいましたが、良い暇つぶしになりました。
Typescriptだと型とかきっちりしてて書いてる途中でエラーに気付けますが、Javascriptだと実行してようやく気付くことが多いので、久々だと意外と難しいですね(笑)
(追記)
Googleの画像検索の結果一括保存したかったのにできてないので、気が向いたらアップデートしていこうかと思います。