山田です。
スパコンポエムアドベントカレンダー、ついに最終日となってしまいました。
12月もあっという間でしたね。
ところで、アドベントカレンダー終わったらなんか降臨するんですかね。もしかしてあれですか、Intel Xeとか降臨したりしますか。しませんね。
さて、@aokomoriutaさんの「HPCGに関する誤解2つ」 は皆さんご覧になられましたか?
HPLに対して実用的なベンチマークとされるHPCGですが、まぁ色々と関わった人は言いたいこともあるというか、なんというか……えーと、とりあえずHPCGを実用ベンチっていってるのを聞くと俺は苦笑いします。
まぁ某石でHPCGやる話はきっとまたどこかで上がってくるよ…というか投げるよ…(???
そしてまさかこの日に登場するとは思いませんでしたが、@k_nitadori先生のスパコンのベンチマークについて
も必読の価値アリです。
Top500, HPCG, Graph500, HPL-AIと、それぞれのベンチマークがどういった特性があり、どういったところがネックになるのかを詳細に解説されています。というかこれ初日に持ってくるべきだったんじゃないかな??? 半年に一度、スパコンを論じたいなら、この辺の計算特性は諳んじられるようになりましょうね(煽り
さて、いよいよ最終日になってしまいました。
当初は一人でやるつもりだったので、ネタが枯渇するだろうと思ってどうしようかなと頭を抱えていましたが、皆様が書いてくださったおかげで、ポエム分が大幅に薄れて、スパコンにまつわる、ベンチマークの話だったり、ファイルシステムの話だったり、インターコネクトの話だったり、誰も知らない諸外国のプロセッサ事情だったり……色々な話が出てくるカレンダーになったんじゃないかと思います。一読者として、楽しみながら読ませていただきました。いうて、皆さんHPC界隈では第一線でご活躍されている方々ばかりですから、そりゃ記事の内容もアツくなろうというものです。俺はそろそろ加持リョウジよろしくスイカに水を上げるだけのかんたんなお仕事に就きたい。
とか言ってる場合でもないので、やっぱり最後にはこれで締めたいと思います。
フラグシップ2020、ポスト京と呼ばれた、日本が生んだモンスターマシン。Nov/2020にて、Top500 #1どころか、HPCG, Graph500, HPL-AIという世界初四冠に輝いた、富岳のお話です。
Day25 Nov/2020 #1 富岳

(出典: https://www.fujitsu.com/jp/about/businesspolicy/tech/fugaku/)
って言ってもですね…俺富岳プロトタイプのこと書いてますし、それに富岳を使ったわけではないので、アレがアレするというか…(?
まぁ、かるーく、ライトな感じで触れていきましょう。
富岳は、理化学研究所(けんきゅうしょ) と富士通が共同で開発したスーパーコンピュータです。皆さん大好き、二位じゃだめなんですかで著しく有名になった京コンピュータの後継機ですね。
↑にも書きました通り、四冠に輝きました。関係者の皆様、本当におめでとうございます! 惜しくもGreen500だけは逃してしまいましたが、それでもあの巨体でありながら#10につけているあたりは、その性能の高さ、消費電力性能の高さが伺えます。
富岳のスペック
| Spec | |
|---|---|
| CPU | Fujitsu a64fx @ 2.2Ghz |
| Memory/Node | HBM2 32GB |
| InterConnect | TofuD |
| Number of Nodes | 158,976 |
| Peak Performance | 537 PFlops |
| (出典: https://www.fujitsu.com/jp/about/businesspolicy/tech/fugaku/specifications/) |
日本語の一次資料が大量にあるのはいいことですねえ(ほろり
以前書いたのでも触れましたが、富岳のCPUは、京の後継といいつつも、京で採用されていたSPARCではなく、命令セットアーキテクチャをArm v8に変更したものを採用しています。その名をa64fx。
2020年は富岳といい、AppleのM1といい、盛んにArmを採用したことが取り上げられていますが、残念なことに、命令セットアーキテクチャがArmになったことは、そんなに性能に直結はしません。これはよく言われる、命令セットアーキテクチャは性能に大して影響しない、という話ですね。
今日のプロセッサというのは、基本的にデコーダ以降はマイクロオペレーションに分解されているので、まぁなんというか、その時点でISAのあれこれはある程度吸収されていたりするわけで、そもそも命令セットが問題になるというのならx86の時点で結構ひどい問題が起こっていないとアレでブツブツ…
閑話休題。
インターコネクトは、京からの発展となったTofuD。DはHigh-DensityのDだそうです。1
Tofu-Dインターコネクトの帯域は40GB/sとなっており、最新のInfiniband HDRと比較してもより高速になっています。ただ、京と比較すると帯域向上幅は倍となっており、CPUの性能がめっちゃ伸びているのに帯域は倍……つまり京のネットワーク性能があまりにも強力であったという証左となっています。
ノード数は圧倒の158,976ノード。これでピーク性能は、HPLのときのブーストクロックではありますが、537PFlops。実効性能は442PFlops。実効効率は82.3%と非常に高くなっています。このときの消費電力は29.8MW。RCCSの受電設備が40MWなので、かなり使っている状態です。
富岳は国内で作られただけあって、一次ソースが大量にあるのが本当に嬉しいところです。
そもそも、マイクロアーキテクチャリファレンスマニュアル が公開されてたり、DGEMMのチューニングに関する資料 が公開されていたりしますし。
記憶に新しい、Xbyakのaarch64対応 とかもありますし。
というリファレンスマニュアルを横目に見ながら、あんまり話すことのないa64fxの話をしたいと思います。
a64fx

(出典:https://www.r-ccs.riken.jp/jp/fugaku/overview.html)
a64fxは富士通の開発したHPC用プロセッサです。
詳細は、本当に[アーキテクチャリファレンスマニュアル]
(https://github.com/fujitsu/A64FX) を読んだほうがいいと思います。まじで。

(出典:https://www.r-ccs.riken.jp/jp/fugaku/overview.html)
a64fxの1チップに収まっているのは48 + 2の50コア…アレ、52コアのハズでは…?
実装としては、12の計算コアと1のアシスタントコア、L2キャッシュとHBM2 1chが一つのCMG(Core Management Group) を構成しており、それが4つ集まって1つのチップを構成しています。
(追記: アシスタントコアは、IOノードには4つだけど、計算ノードは2つだそうです。@k_nitadori先生ありがとう)
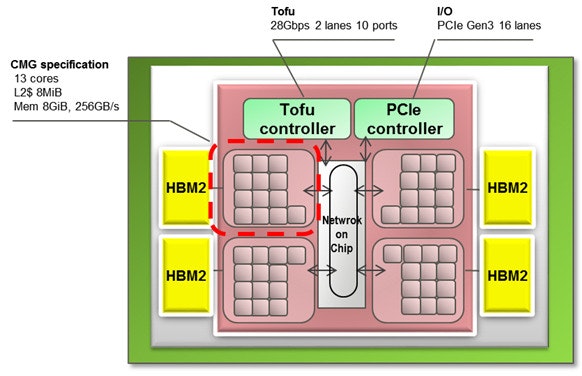
(出典: https://pc.watch.impress.co.jp/docs/news/1139081.html)
つまるところNUMAとなっていて、メモリアクセスの仕方を間違えるとえらいことになるパターンなわけですね。やっぱりこういうところでも年々厳しくなっていくんだなって…Zen系も然り…
特徴的なのは、さんざん語られている通り、Arm v8-2のHPC用拡張であるところのScalable Vector Extention(SVE)ですね。
SVEに関しては、実際に使われている方の記事 や、解説記事 なんかがあるので、そちらをご覧いただくといいかと…
軽く触れておくと、SVEが他のSIMD命令セットとの違うところは、命令セットレベルではSIMD長を全く意識しなくて良いという点にあると思います。
どういうことかというと、IntelのSSE, AVXはそれぞれ128bit長、256bit長がコードとして露出するような設計となっていました。そのため、SSEからAVXにするためには__m128を__m256に書き換えてループ長を書き換えて命令を…という手順を経る必要がありました。ところがSVEでは、コードにはSIMD長が出てこないので、仮にa64fx以外のSVEの実装が出てきたとして、そしてそのSIMD長がa64fxと異なっていたとしても、全くコードを書き換える必要なく実行できるのです。ポータビリティ極まったな。
a64fxではSVEにフォーカスされがちですが、それ以外にも効果のありそうな拡張 がいくつかなされています。
その中で一つを取り上げるのなら、やはりセクタキャッシュですね。ただ、これ自体は京のCPUであるVenus時代からあったものなので、a64fx特有のものというわけではないですが…
セクタキャッシュは、コアごとに存在するL1キャッシュ、またはCMGごとに存在するL2キャッシュに対して、セクタと呼ばれる領域を作り、その領域のデータの囲い込みを行う機能です。機能的には、NVIDIAのA100で実装されたL2のロックに近いものがあるでしょうか。ただ、このセクタキャッシュのほうがより自由で応用が効きます(完全にこのセクタに対するロード/ストアという感じで明示的に書けるので、かなり強力なキャッシュ制御が可能になる)
近年のヒエラルキーキャッシュを使っていて一番つらいのが、キャッシュの気持ちになることで……っていうのはいつも言ってるな…なので、明示的に、ここはこのセクタに対するロード(違うセクタのデータには影響しない = 別のデータはキャッシュに乗り続ける) ということができるのはかなり大きいです。巨大なデータをなめる必要がある、とかだと、キャッシュが一回必ずフラッシュされちゃう、という状況があったりして…(つらくなってきた顔
まぁ、a64fxがどうすごいかは、ここでポエム読むよりマイナビとかPC Watchとか見たほうがいいって。いやわりと本当に。
富岳のまとめ
- 富岳はすごい(小学生並みの感想
Extra stage!!
2021年のスパコン事情
さて、スーパーコンピュータとはめちゃくちゃ巨大であり、めちゃくちゃお金がかかります。世の中、ポケットマネーでスパコンを構築しちゃったりする石油王みたいな人もいるのかもしれませんが…いや、実際…うん…やめよう。
というわけで、それだけ巨大なお金と場所と電気が必要となるものだと、必然的に設置できる場所も限られれば、必然的に、計画的に構築をしなければなりません。研究する方々にしろなんにしろ、年々必要となる計算機のスペックは上昇傾向にあります。ましてや、近年ではディープラーニングが大流行。新しいモデルを構築するのにしろ、学習規模の増加にしろ、計算リソースはあるならあるだけほしい、というのが実情。なので、米国はDOEなんかでは、完全に研究所ごとにローテーションでスパコンのリプレースを行っています。そして、そういうのは調達計画を見ればなんとなくわかってしまうというもの。
というわけで、2021年どころか、2023年ぐらいまでのランキングは大体想像がついてしまう、というのが今のスパコン業界だったりします。
というわけで、少しだけ2021年のスパコン事情を先取りしてみたいと思います。
Aurora

(出典:https://www.alcf.anl.gov/aurora)
DOEはANLにて構築予定(中?) の、1 ExaFlops@DP超えを予定しているスーパーコンピュータです。
なんといっても、これの特徴はCPUとGPUがIntel製であるということ。おい、誰だIntelってHPCまだやってたんだって言ったやつ!
CPU側は、XeonのSapphire Rapids。なんか動いているとか動いていないとかいう噂のCPUです。PCIe Gen5を採用するということで、IntelのCPUのPCIeはGen4の寿命が異様なまでに短い状況となってしまうみたいです。まぁIntelそういうところあるしな(?
GPU側は、AMDからやってきたRaja氏が音頭を取って作っているという、Intel XeアーキテクチャのPonte Vecchio。アレ…SC20ではまだ開発中みたいなこと言ってなかったあなた…大丈夫…? とか一抹の不安もあったりなかったりですけれども、情報としては、チップレットを採用したタイルアーキテクチャであるとか言われており、非常に野心的なGPUとなっていることが予想されます。
CPU-GPU間はPCIeでの接続ですが、GPU-GPU間はXe Linkという謎のインターコネクトが実装されるようです。CPUもGPUも自分たちで作ってるんだから、インターコネクトも自作すればいいのにねえと思ったり思わなかったりします。
まぁもともとは、AuroraはKnightsHillで作られるはずで、2019年ぐらいにローンチするプレエクサ機だったはずなんですけどね…KNHのキャンセルが響いてそこからずれ込み、二年のディレイで2021年末にローンチする予定となっています。
Perlmutter

(出典: https://www.nersc.gov/systems/perlmutter/)
NERSCに構築されるスーパーコンピュータです。Coriの後継機ですね。
本当は2020年ローンチ予定だったんですけど…まぁまだローンチしたという話は聞いてませんしねえ。これは多分2021年にずれ込むことでしょう。あと数日で構築されたリリースが打たれないとも限りませんけどもw
Auroraや他の比較して、PerlmutterはA100を6000個程度とのことなので、理論ピーク値で19.7TFlops * 6000 = 118.2PFlopsと、少々小ぶりなシステムになると考えられます。
特徴としては、EPYC3とA100を使うということで、まぁEPYC3もまだローンチしてないし、それが原因で遅れてんのかしらね、という気持ちにも…
EPYC3ことMilanは、EPYC2ことRomeでの欠点であったCCXとCCDの構造が見直されて、L2キャッシュがCCXの壁をぶち抜いてくれたため、CCD内のL2キャッシュの容量そのまま、共有単位がCCDになるというキャッシュが更に使いやすくなるというアーキテクチャになったので非常に期待しています。うん、ネガティブなことは書かないでおく!!
Frontier
![]()
(出典: https://www.olcf.ornl.gov/frontier/)
君たちはかっこいいティザーサイトでも作らないと死ぬのか?
ORNLにて構築される予定のスーパーコンピュータです。
おそらく完成した暁には世界最速の座、そしてExaFlops超えの栄誉を手にするであろうとされています。目標性能は1.5ExaFlops over。さて、Auroraとどっちが先にできるかな…
特徴はなんといっても、フルAMDで構築されるということです。EPYC + Radeon Instinct。先日、MI100が発表されましたね。あれか、アレの次か…といった感じでしょうか。また、EPYCについても、Milanなのか、その次なのか、というのはまだ明らかにはなっていません。
フルAMDのおかげか、CPU-GPU間はInfinity Fabricによるコヒーレントバスで繋がれるようです。AMDのがIntelよりまともにシステム構築やってないか?気の所為か?
このFrontierも2021年ローンチ予定ですが、どうなることやら、といった感じです。全てはコロナが悪い。
Lumi

(出典: https://www.lumi-supercomputer.eu/)
こちらのスパコンは、ところかわってヨーロッパから。
ヨーロッパらしい芸術的な端末(?)のような気もしないでもないですが、これなんだろう。
中身はEPYC+Radeonという、これまたフルAMDの構成で構築されるようです。
理論ピーク性能は約500PFlops程度とのこと。富岳と並ぶぐらいでしょうか。
アドベントカレンダー総まとめ
というわけで、スパコンポエムアドベントカレンダーでした。
25日間、埋められるとは思っていなかったので、埋めることができて嬉しいというのと、スパコンにまつわる話だけで一ヶ月間話を繋げられた、というので、それだけネタがあったんだな(放り出した感もなくはない) という気持ちでいっぱいでいます。
あんまり技術的なことが書けなかった(文字通り書けなかった) …まぁそれゆえポエムと冠しているわけですけれども…のは、ちょっとアドベントカレンダーとして心苦しいところではなくはないのですが、スーパーコンピュータというものに関して、またそれを取り巻くベンチマークであったり、ファイルシステムであったり、使いやすさというものへの理解に、このアドベントカレンダーが少しでも寄与できていたとしたらとても嬉しいです。
また、これらの記事を読んで、スパコンって面白そうだな、と感じる人が少しでもいて、HPC業界の盛り上がりに、少しでも貢献できたのなら、それは望外の喜びです。
スパコンは2021年も、きっとその先も、もっともっと面白くなりますし、面白くしていきたいと思います。
ひとまずは、2021年6月のランキングをお楽しみに!!!
皆さん2020年12月、お疲れさまでした。
良いお年を!