1. 概要
信号や画像などのデータを用いて、データの表現を直接的に学習することで少ないパラメータで高品質な結果が得られるネットワークアーキテクチャとして、Implicit Neural Representations(INRs)が知られる。画像であればピクセル値や特徴ベクトルなどの明示的な表現を必要とせず、ネットワークは入力データを予測するための関数として学習される。超解像(super-resolution)や3Dモデリングなどの応用で用いられるが、従来研究では生成時にボケやすい画像を抑制するため、高周波成分を考慮したSin波による位置のエンコーディング(positional encoding)を用いることが多かった。しかし、画像の位置で特徴を取得するPositional Encodingを用いると、大規模な画像データセットに共通する汎用的な特徴を学習することが難しくなってしまう。この研究では、多項式関数を使用して画像を表現しており、Positional Encodingを用いないことで、ImageNetなどの大規模データセットに対してより少ないパラメータ数で高い精度の画像生成(Image Generation)を実現している。
2. 新規性
学習するパラメータ数が少なく、畳み込み演算(Convolution)や正規化、アップサンプリング、セルフアテンションなどの層を一切用いずに、多項式のみの表現で拡散モデル(Diffusion model)を含む従来の画像生成の精度を上回っている。
3. 実現方法
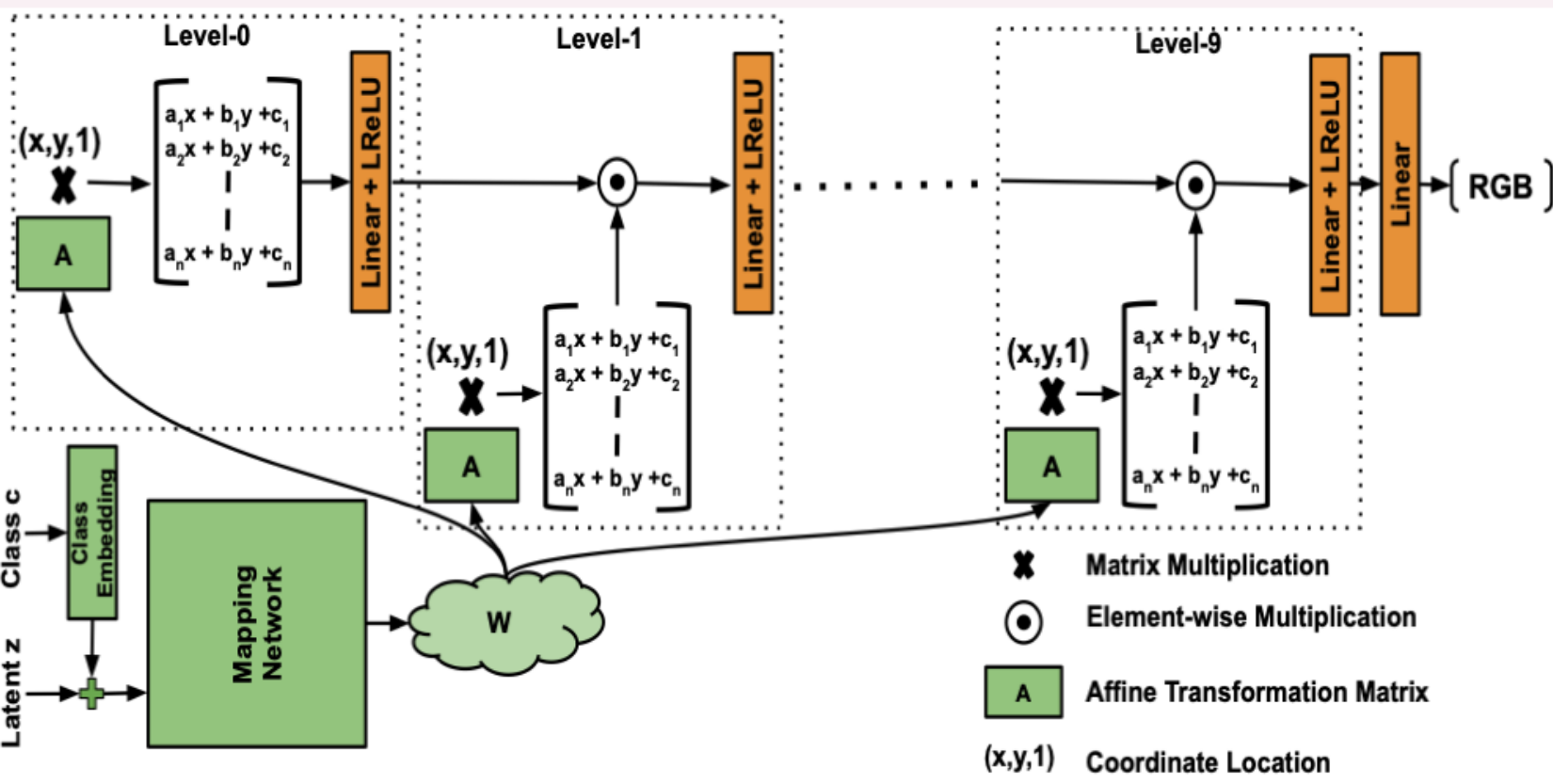
Linear層とReLU層だけを用いた特徴取得設計になっている。ただし、この単純なMLPでは低次元の多項式しか表現できなくなるため、ネットワークの次元を増やすためにReLU層の後に座標位置をアフィン変換した値をピクセル単位(element-wise)で乗算している。潜在空間zは64次元で、Mapping Networkを介してアフィン行列で学習されるパラメータ空間を512次元に膨らめている。ネットワーク全体としては、ある座標(x,y)の画素値(R,G,B)を予測するモデルとなっている。
4. 結果
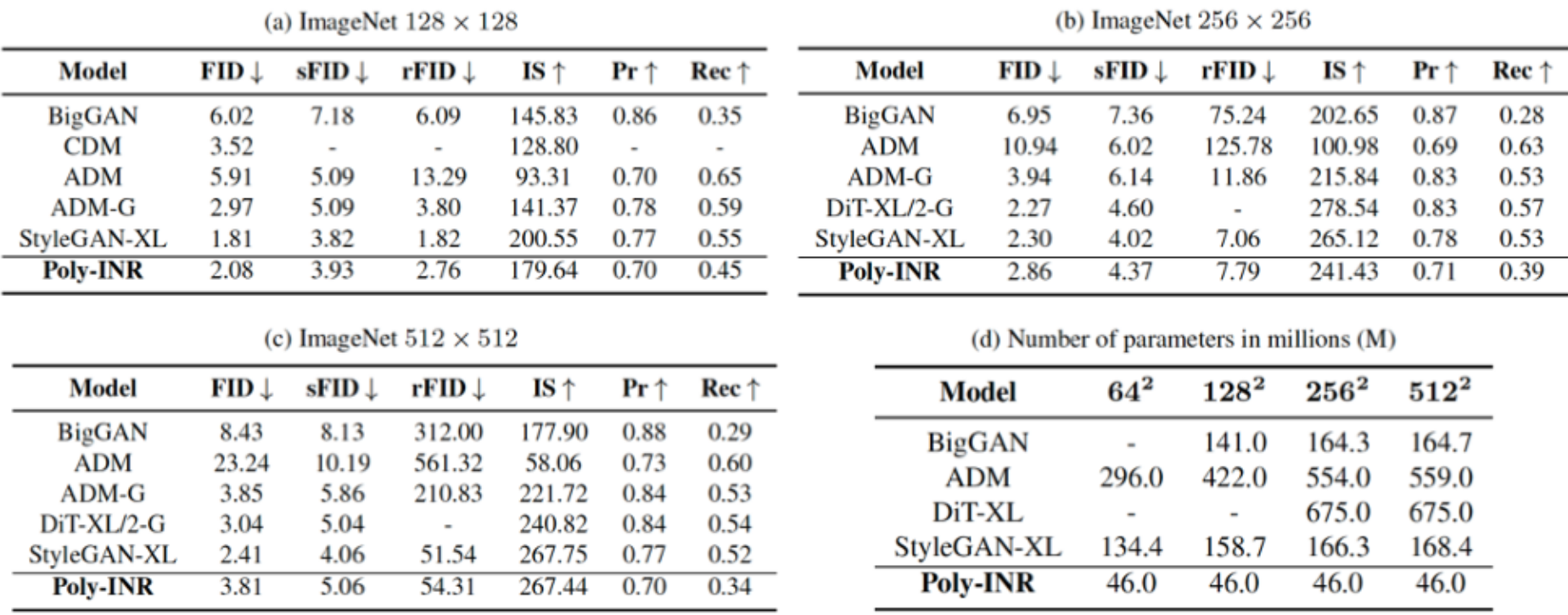

CNNベースのGANs(Generative Adversarial Networks)を用いた手法(BigGAN/StyleGAN-XL)や、拡散モデル(Diffusion model)を用いた手法(CDM/ADM/DiT-XL)と比べて少ないパラメータ数で高精度に画像を生成できている。
last updates: July 14 2023