1. 概要
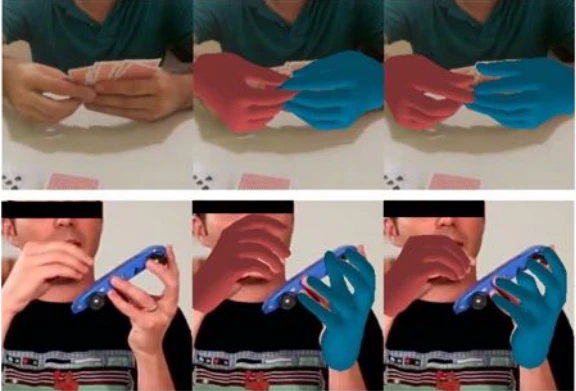
実世界の人間の複雑な手の動きを2D画像から3Dモデル化することは、複雑な手の空間的な関係を予測する必要があり、また両手の重なりなどのオクルージョンが発生することに加え、左右の手は見かけが非常に類似していることもあって、非常に難易度の高いタスクである。提案手法では、特徴空間を2Dと3Dで分けており、局所的な特徴量は2D空間で、大局的な特徴量は3D空間で求め、2つの特徴空間で複数回のフィードバックループを設けることで正確な予測を可能にしている。(図は、左から入力画像:IntagHand(従来手法):提案手法)
2. 新規性
複雑な両手の振る舞いを2D画像から3Dモデルにするフレームワークを提案しており、ピクセルレベルで3Dモデルのメッシュを画像にマッピングできる。
3. 実現方法
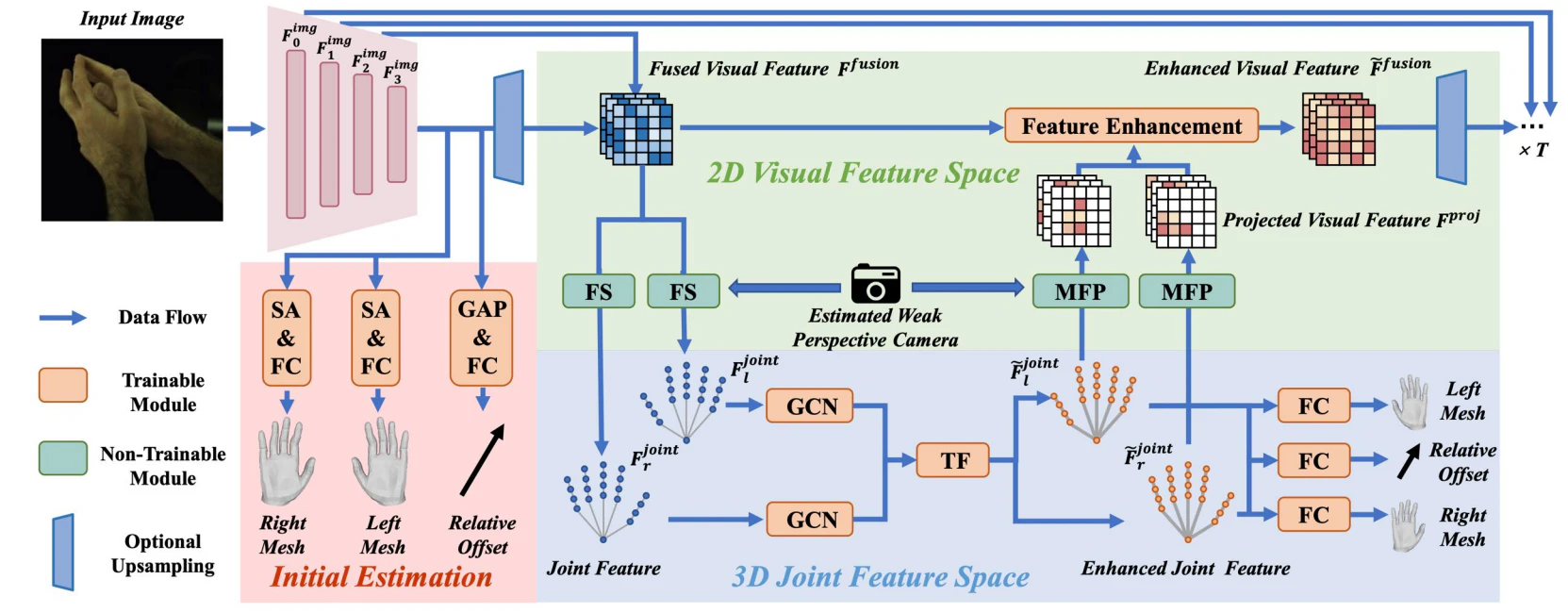
まず、エンコーダーから得られる視覚特徴を2D空間で手の関節毎に表現する。抽出された特徴をもとにGCN(Graph Convolutional Neuralnetwork)を用いて3次元空間の特徴量に変換し、さらにトランスフォーマーを用いて3Dの手の関節の特徴から左右の手の3Dメッシュと両手のインタラクション情報を予測する。次に、大局的な情報を持つ手の関節の特徴を2D特徴空間に逆投影し、2DのCNNを用いることで3D情報を反映してピクセル単位で情報のアップデートを行う。これを複数回繰り返すことで2D-3D間の整合性が取れて正確で頑健な手の推定が可能になる。
4. 結果


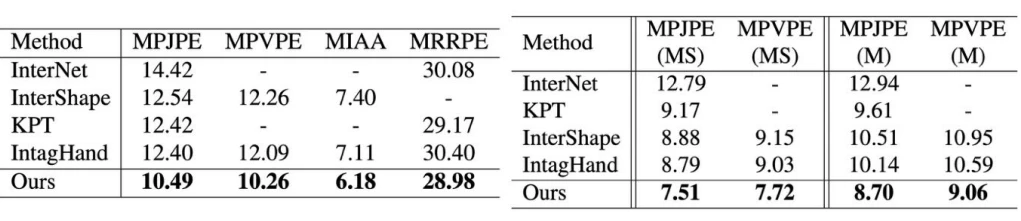
大規模な手のデータセットであるInter Hand 2.6Mを用いて評価実験されており、従来手法の性能を大幅にうわ待っている。
last updates: Oct 10 2023