1. 概要

テキストプロンプトを入力としてお部屋のレイアウトを3Dメッシュでテクスチャまで生成する技術を提案している。事前学習としてテキストと画像をペアにしたモデルを採用しており、異なるカメラ視点からの見かけを合成して出力することで、3次元シーンの再構成を実現している。シームレスな3Dシーンを生成するために、単眼の深度推定と画像補完であるインペインティングを用いている。
2. 新規性

各生成画像のコンテンツをシームレスなテクスチャ入りの3Dメッシュに合成する際に、適切なカメラ視点の選択を行うことで自然な見かけを実現した。
3. 実現方法
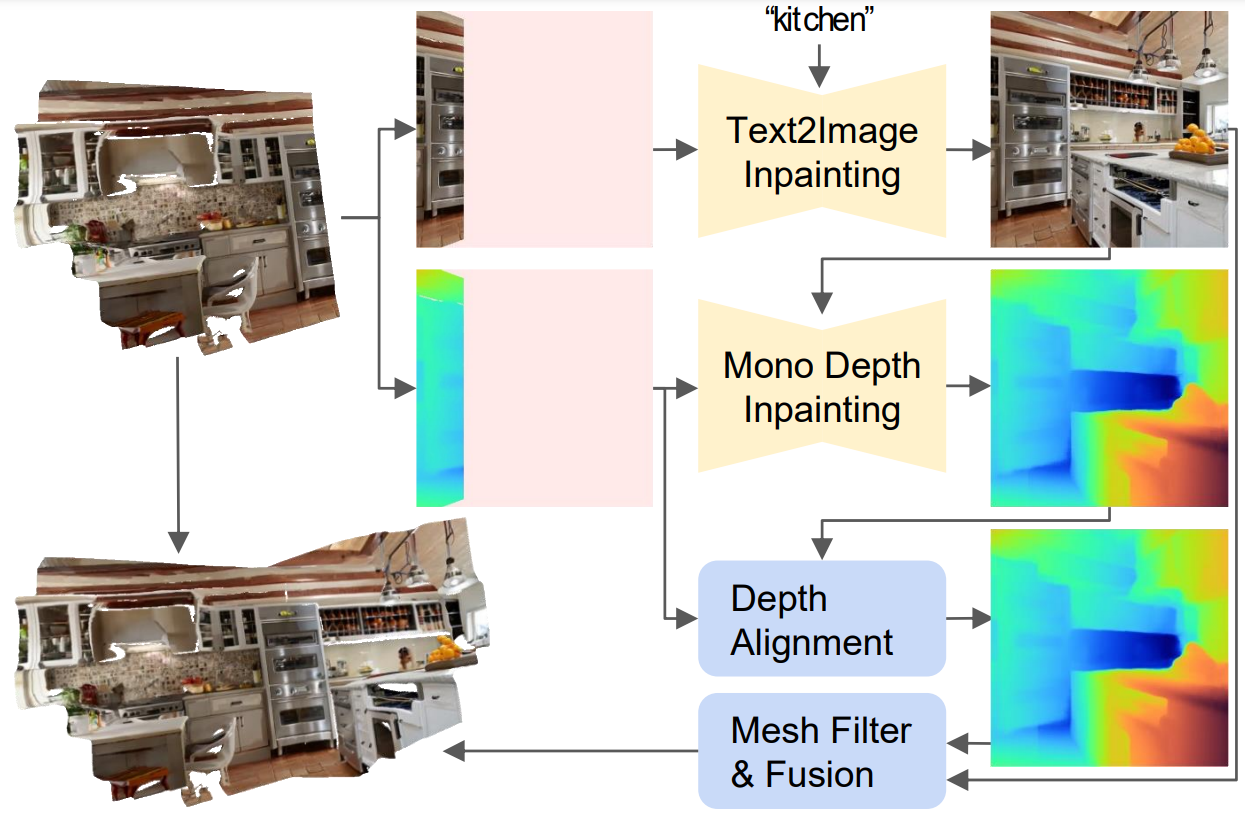
各カメラポーズに対して、インペインティングを用いて生成された画像のRGBとDepthの両方を補完する。Depth AlighnmentとMesh Filteringを行って次のメッシュをパッチ単位で取得し、生成済みのシーンと合成していく。これを繰り返すことで、任意視点からの見かけに対してシームレスにテクスチャが連続した3Dメッシュが構築できる。
4. 結果


テキストプロンプトから、部屋の詳細な家具やテクスチャ情報まで反映させて3次元シーンを構築できるようになった。
last updates: Nov 24 2023