設定ミスでログインできなくなったインスタンスを復旧することになった時の作業記録です。
Unix系OSにおける一般的な起動ディスクの障害対応手順を、単にAWSならこうやる、というだけの話で恐縮ですが、何かのお役に立てれば幸いです。
症状と効能
こんな人によく効きます。
- iptablesやTCP Wrapperの設定をミスったとき
- キーペアを紛失したとき
- OSの設定をミスって起動しなくなったとき
何かしらの原因で、ログインできなくなったり、インスタンスが起動しなくなったりしたときにファイルシステムにアクセスすれば糸口が掴める、といった時に使えます。
オンプレミス環境やホスティングサービスなら、ブートディスクを変更してからの復旧や、コンソールログインからの設定修正など、何かしらの手段が提供されていますが、AWSだとこのような方法になるかと思います。
なお、利用しているインスタンスはAmazon Linux、rootボリュームはElastic Block Store(EBS)ですが、LinuxのDistributionならば、ほぼ共通の手順になると思われます。
注意点
システムステータスチェックやインスタンスステータスチェックがNGのケースは、この方法では対処できない可能性が高いと思われますのであしからず。その場合は、こちらを参考に対処してください。
参考:『Amazon EC2ユーザガイド』インスタンスのステータスチェック
対応手順サマリ
- 障害が発生した「インスタンスA」を停止
- 「インスタンスA」のEBSボリュームをデタッチ
- 正常起動できる「インスタンスB」に対象ボリュームをアタッチ
- 「インスタンスB」を開始&ログイン
- 対象ボリュームをマウント
- 原因調査と対処
- 対象ボリュームをアンマウント&デタッチ
- 「インスタンスA」に対象ボリュームをアタッチ&起動
以下に順を追って内容を記します。
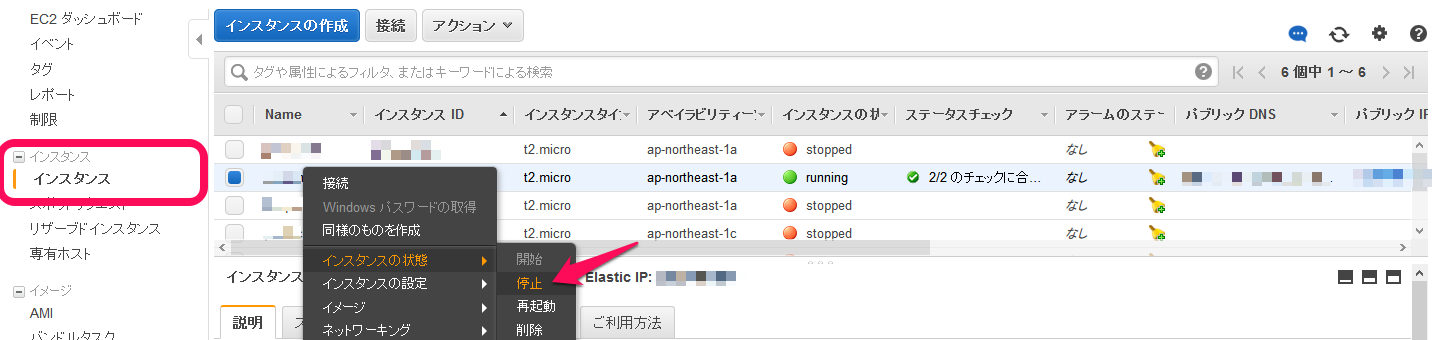
障害が発生したインスタンスの停止
まずはマネジメントコンソールで作業します。
対象インスタンスの「ルートデバイス」名を確認してから、インスタンスを停止します。

ルートデバイス名は、「/dev/xvda」もしくは「/dev/sda1」となっているかと思います。今回使用しているAmazon Linuxでは、「/dev/xvda」となっていました。
AWS CLIコマンドを使って調べることも可能です。この辺の詳細は『Amazon EC2ユーザガイド』Linux インスタンスでのデバイスの名前付けを参照してください。
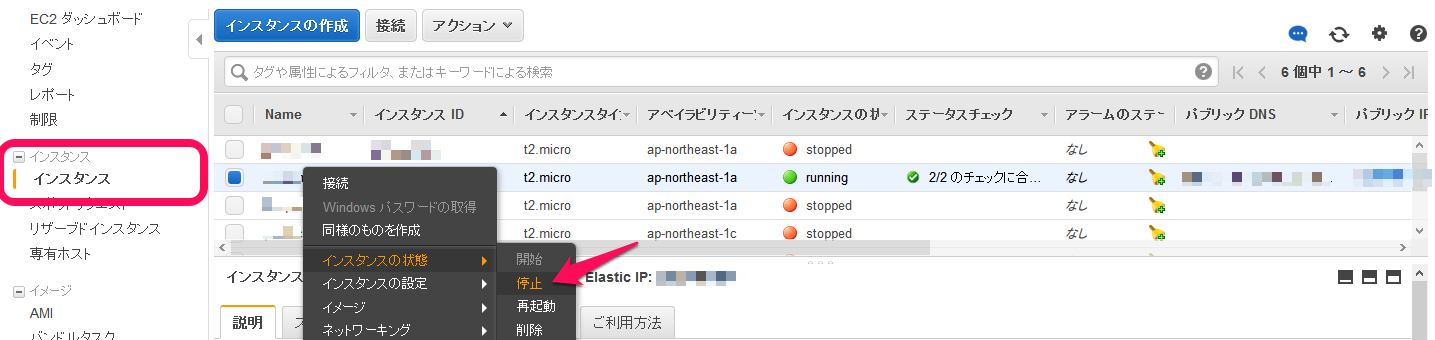
対象デバイスを右クリックして「停止」を選択します。
EBSボリュームをデタッチ
インスタンスが停止されたことを確認してから対象のEBSボリュームをデタッチします。
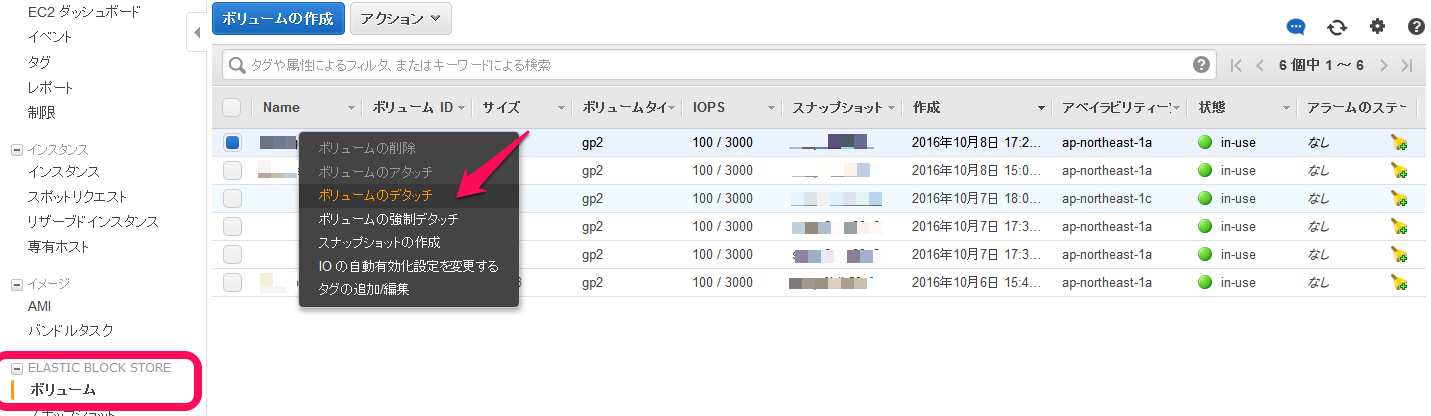
対象ボリュームを右クリックして「ボリュームのデタッチ」を選択します。
正常なインスタンスにボリュームをアタッチ
ボリュームの状態が「available」になったら、別の正常なインスタンスにアタッチします。
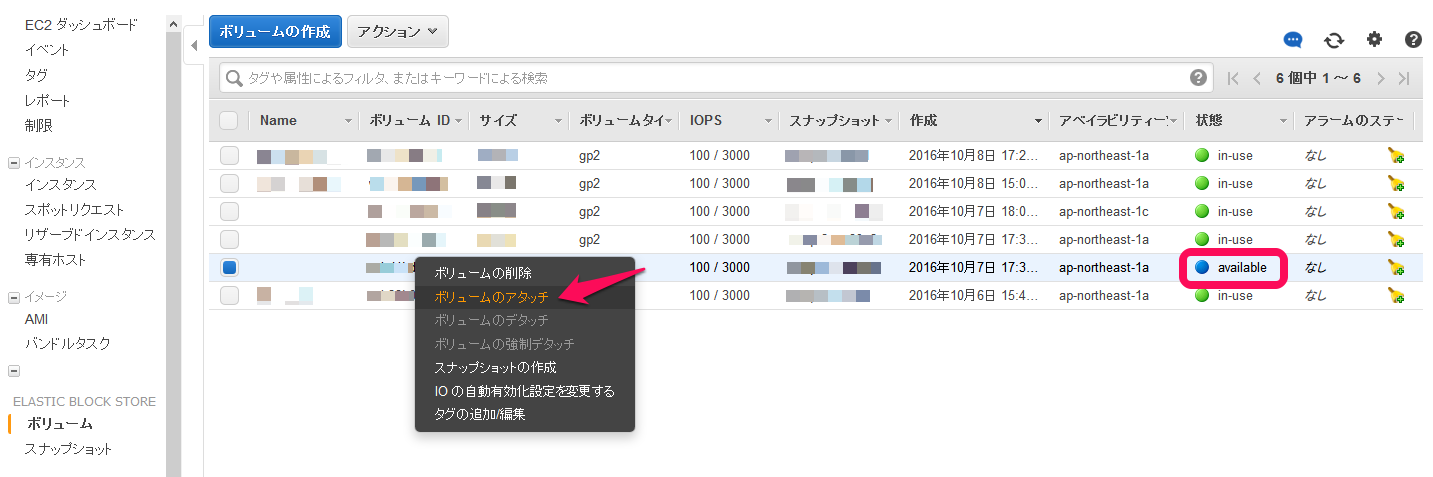
対象ボリュームを右クリックして「ボリュームのアタッチ」を選択します。
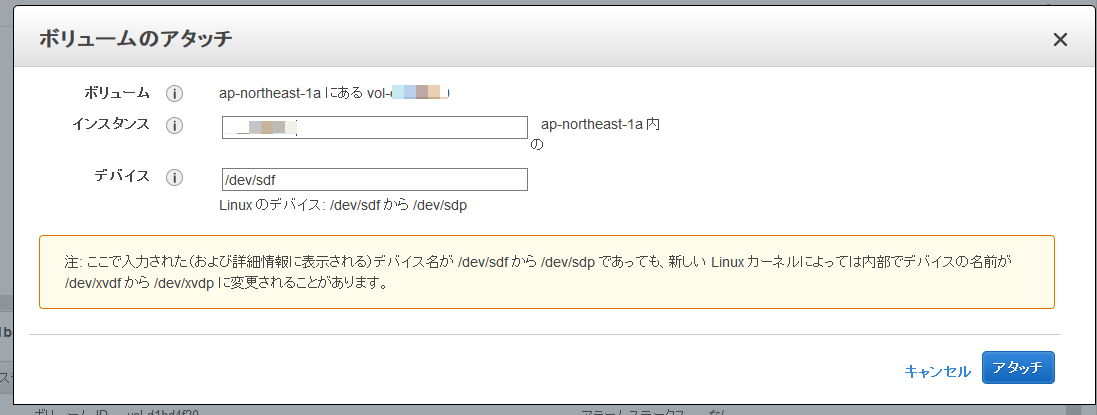
アタッチ先のインスタンスを選択し、ブロックデバイス名を指定します。今回は「/dev/sdf」を指定。
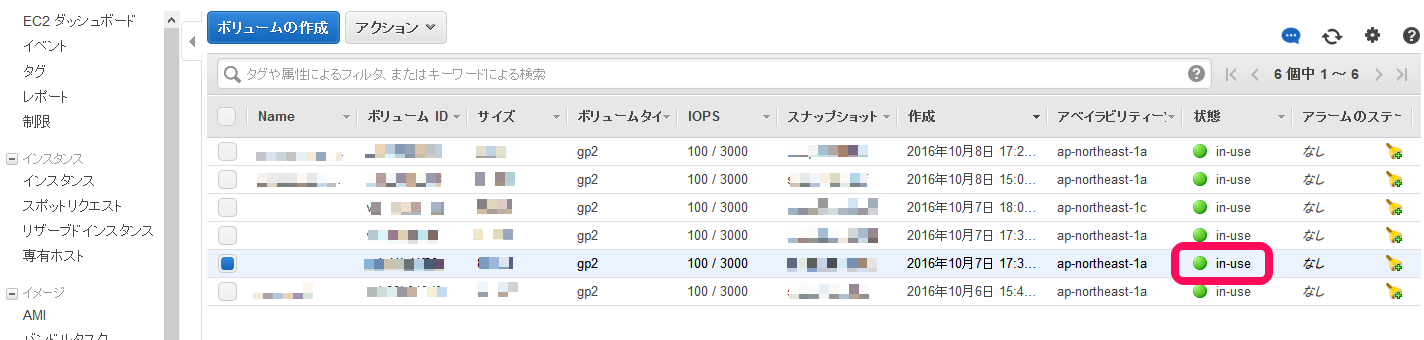
ボリュームの状態が「in-use」になれば、アタッチ完了です。
正常なインスタンスを開始~ログイン
通常の手順どおり、ボリュームをアタッチしたインスタンスを「開始」(=起動)し、SSHでログインしてください。ちなみに、今回使用したインスタンスはCentOS6.7です。

対象ボリュームをマウント
ログイン後、先ほどアタッチしたボリューム「/dev/sdf」をマウントします。
このときのデバイス名は、/dev/sdfか/dev/xvdfなど、異なる名前でアタッチされる可能性があります。
参考:『Amazon EC2 ユーザガイド』Amazon EBSボリュームを使用できるようにする
$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/xvda1 7.8G 666M 6.7G 9% /
tmpfs 498M 0 498M 0% /dev/shm
ここで、ルートデバイスが/dev/xvとなっていたら、先ほどアタッチしたボリュームの名前も/dev/xvとなっています。
$ ls -la /dev |grep sd
$ ls -la /dev |grep xv
lrwxrwxrwx. 1 root root 5 Oct 8 14:47 root -> xvda1
brw-rw----. 1 root disk 202, 0 Oct 8 14:47 xvda
brw-rw----. 1 root disk 202, 1 Oct 8 14:47 xvda1
brw-rw----. 1 root disk 202, 80 Oct 8 14:47 xvdf
brw-rw----. 1 root disk 202, 81 Oct 8 14:47 xvdf1
$ lsblk -i
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
xvda 202:0 0 8G 0 disk
`-xvda1 202:1 0 8G 0 part /
xvdf 202:80 0 8G 0 disk
`-xvdf1 202:81 0 8G 0 part
マウントするディレクトリを作成して、マウント実行。
$ sudo mkdir /mnt/vol_ebs
$ sudo mount /dev/xvdf1 /mnt/vol_ebs
$ mount
/dev/xvda1 on / type ext4 (rw)
...<snip>...
/dev/xvdf1 on /mnt/vol_ebs type ext4 (rw)
正常にマウントされました(マウントポイントは/)
原因調査と対処
システムログや、作業履歴などから原因を調査し、設定を修正するなどして復旧します。
今回はTCP Wrapperの設定ミスで、SSHログインができなくなっていたため、hosts.allowおよびhosts.denyを適切に修正しました(修正内容は割愛)。
アンマウント~対象ボリュームをデタッチ
念のためアンマウントして、対象インスタンスを停止してから、EBSボリュームをデタッチします。
$ sudo umount /mnt/vol_ebs
$ mount
/dev/xvda1 on / type ext4 (rw)
...<snip>...
none on /proc/sys/fs/binfmt_misc type binfmt_misc (rw)
マネジメントコンソールで停止
対象デバイスを右クリックして「停止」を選択します。
インスタンスの状態が「stopped」に変わったことを確認して、EBSボリュームをデタッチします。
対象ボリュームを右クリックして「ボリュームのデタッチ」を選択します。
対象ボリュームをアタッチ~インスタンス開始
デタッチしたボリュームは元のインスタンスにルートデバイスとしてアタッチします。
ボリュームの状態が「available」であることを確認の上、アタッチします。
対象ボリュームを右クリックして「ボリュームのアタッチ」を選択します。
アタッチ先のインスタンスを選択し、ブロックデバイス名を指定します。元の状態に戻すため「/dev/xvda」を指定してアタッチします。
ボリュームの状態が「in-use」になれば、アタッチ完了です。
通常の手順どおり、ボリュームをアタッチしたインスタンスを「開始」(=起動)し、SSHでログインしてください。無事ログインできれば成功です。
以上です。
参考にした記事
手順をまとめるにあたり、こちらの記事を参考にさせて頂きました。ありがとうございます。
AWSサーバーにログインできなくなった場合の対処