はじめに
Lambdaでスクレイピングしたいですよね。じゃあChromedriverにSeleniumいるね。
そして取得したデータ、良い感じに取りまとめしたいですよね。じゃあBeautifulsoupとかPandasいるね。
という感じで、ピュアではないライブラリやドライバが欲しくなることが多々あります。
で、Lambdaレイヤーつくるかあ。となるのですが
Winで落としてきたChromedriverはそのままでは動かなかったり,
ローカルで作ったzipもレイヤーに上げようとすると「AmazonLinux以外お断り!」とか怒られたりするわけです。
もう全部AWS上で完結してしまいたい。となってAWS経済圏に入り込むわけです。
商売上手(for 開発下手)。
AWS Cloud9の活用
ということでペアプログラミングでお世話になることの多いCloud9を使います。
それにしてもAWSのサービス名はおしゃれですね。クラウド使って最高にハッピー(Cloud nine)になるだって。
AWS Cloud9にアクセスをして,
↓Create Environmentして...

↓適当に名前を付けて...
↓残りはデフォルトで。
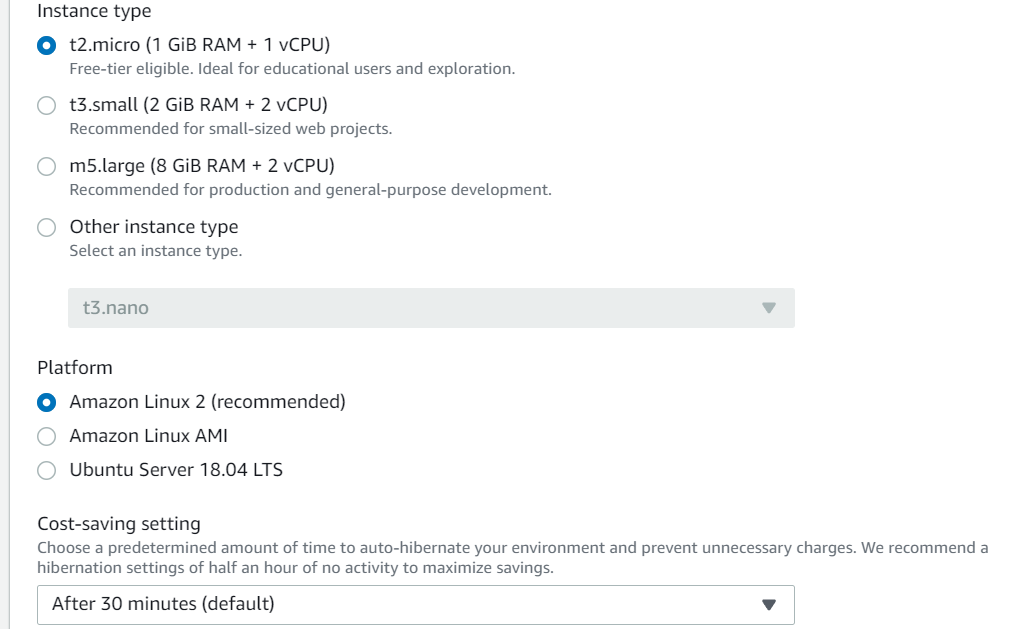
Linuxで扱えるのがGoodなポイントです。
ちなみにCost-saving settingで、インスタンスの自動停止(無駄課金防止)設定できます。デフォルト(& minimum)は30分で、Neverを選ぶと無限課金編
pythonライブラリインストール
LambdaでLayerとして使用するためには、ディレクトリ名を「python」としてあげる必要があります。正確には、Lambdaのデフォルトパスがopt/pythonなので、そこにモジュール群を共存させるために「python」というディレクトリにします。こうすることで、Lambda側での余計な設定なくモジュールのimportが可能になります。
ということで「python」ディレクトリを作ります。
~/environment $mkdir python
~/environment $cd python
そして必要なライブラリインストールしていきます。
~/environment/python $python3 -m pip install beautifulsoup4 -t .
~/environment/python $python3 -m pip install pandas -t .
~/environment/python $python3 -m pip install requests -t .
~/environment/python $python3 -m pip install selenium -t .
-tで、インストール先ディレクトリを指定します。今はpython直下にいるのでカレント(.)に指定。
ここで、Cloud9はデフォルトだとpython2系のpipが動いてしてしまうようなので、ちゃんと上記のようにpython3を明示してあげる必要があります。ここで1時間以上ハマってしまいました。
Chromedriverインストール
Chrome driverと、ブラウザ開かずChromeを使えるHeadless Chromeを入れます。
前のenvironment直下のディレクトリに戻ってディレクトリ作成します。
~/environment/python $ cd ~/environment
~/environment $ mkdir -p headless/python/bin
~/environment $ cd headless/python/bin
で、curlで入れていきます
$ curl -SL https://github.com/adieuadieu/serverless-chrome/releases/download/v1.0.0-37/stable-headless-chromium-amazonlinux-2017-03.zip > headless-chromium.zip
$ unzip -o headless-chromium.zip -d .
$ rm headless-chromium.zip
$ curl -SL https://chromedriver.storage.googleapis.com/2.37/chromedriver_linux64.zip > chromedriver.zip
$ unzip -o chromedriver.zip -d .
$ rm chromedriver.zip
zipをダウンロード保存→zip解凍→zip破棄をやっています。
Lambda Layer用zip作成
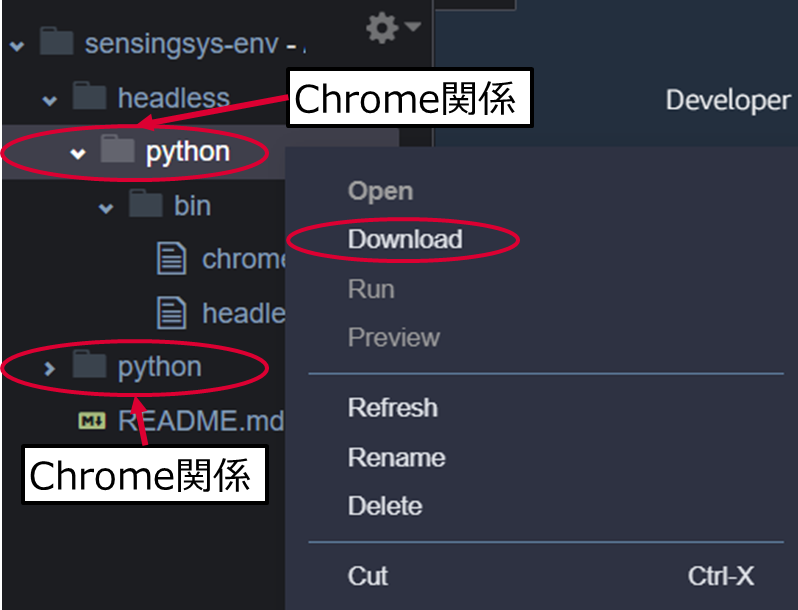
pythonライブラリとChrome関係ファイルを右クリックダウンロードします。
このとき、どちらもpythonフォルダを右クリックしてダウンロードするようにします。同じ名前のzipが出来上がるので,chrome.zipとlib.zipと分かりやすく名前を変えておきます。
Lambda Layerにアップロード
Lambdaの左サイドバーにあるレイヤータブをクリックし、レイヤーの作成を選択。
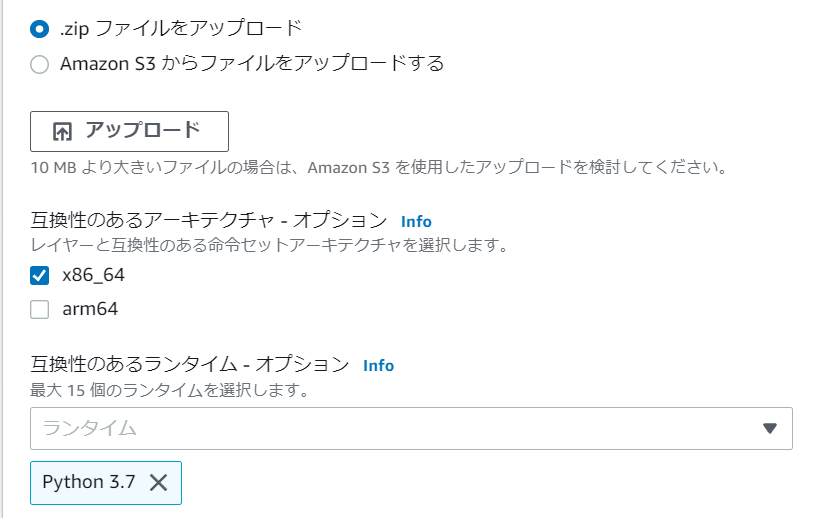
先ほどの.zipをひとつずつアップロード。二つとも40MB近くあるので時間かかります。
注意書きにあるようにS3アップロードを検討しても良いかもしれません。
このとき、ランタイムはpython3.7に設定しておきます。
Layerの追加
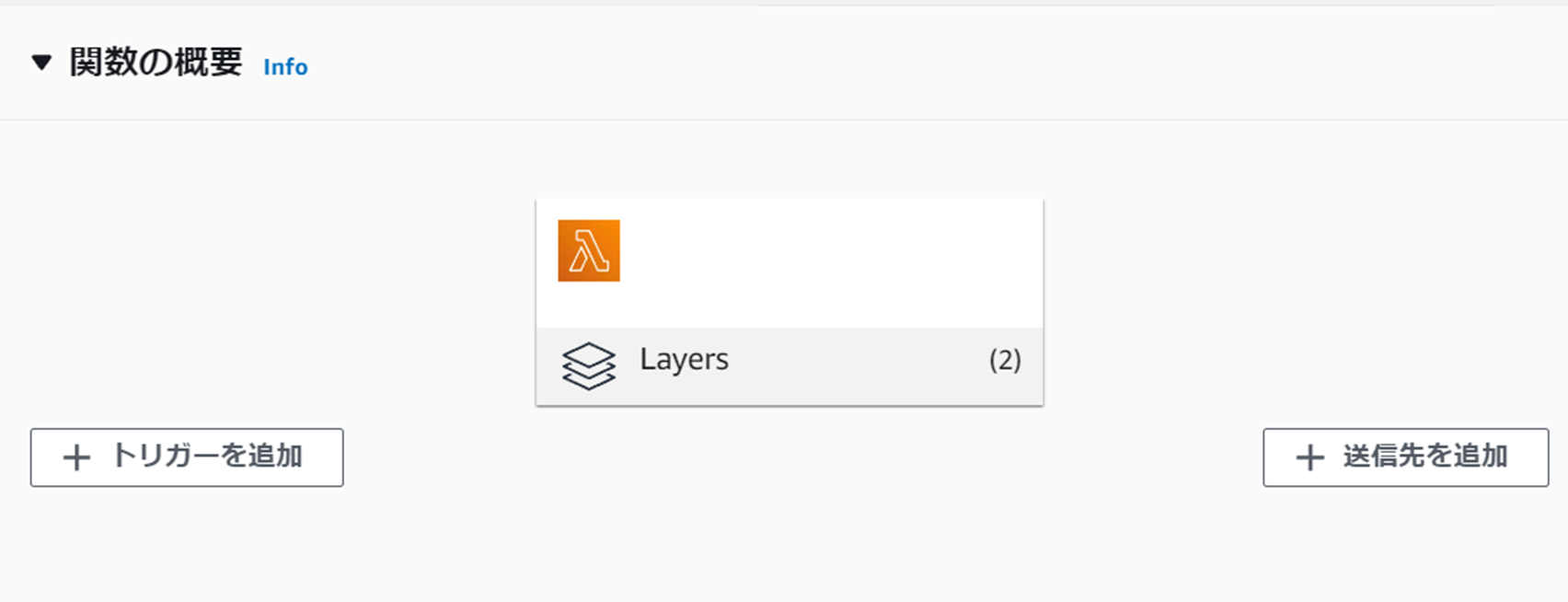
Lambdaトップ画面のLayersから、レイヤーの追加→カスタムレイヤーで、先ほど作ったレイヤーを選択します。
ふたつ追加した後、上図のようにLayers(2)となっていればOK!
おわり
これでLambdaからHeadlessのChromeが扱えるようになりました。
ちなみにそもそもやりたかったことは、ログイン認証が必要なサイトのスクレイピングなのですが
Lambdaではそれが実現できないことが分かってしょんぼり。。。
クラウドの恩恵を受けられるようなHeadlessなスクレイピング事例ないかなー。
下記の記事を大いに参考にさせて頂きました。ありがとうございます。
【AWS Lambda】でseleniumを使ってスクレイピングをサーバーレスで行う~前編~