アウトプット内容
Pythonで日経サイトの記事をスクレイピングして、
平日朝9時にLINEへ自動送信する仕組みを作ってみました。
使ったのは、LINE Messaging APIとcronです。
この記事でできるようになることは、ざっくり以下の内容です。
- 日経サイトから記事をスクレイピングして取得する
- トップ/金融/ビジネスの先頭記事をそれぞれ1件ずつまとめる
- cronを使って平日9時に自動実行する
- 毎朝LINEにニュースが届く状態を作る
背景
アウトプットとして、
「自分が普段使えたら嬉しいもの」を作ってみました。
通勤中に日経ニュースを見ることが多いのですが、
毎回サイトを開くのが少し面倒だったので、LINEに自動で届く仕組みを作ってみました。
日経には個人向けの公式APIがなかったため、
今回はPythonでWebページをスクレイピングし、
取得した記事をLINE Messaging APIを使って自動で送信する仕組みを作ってみました。
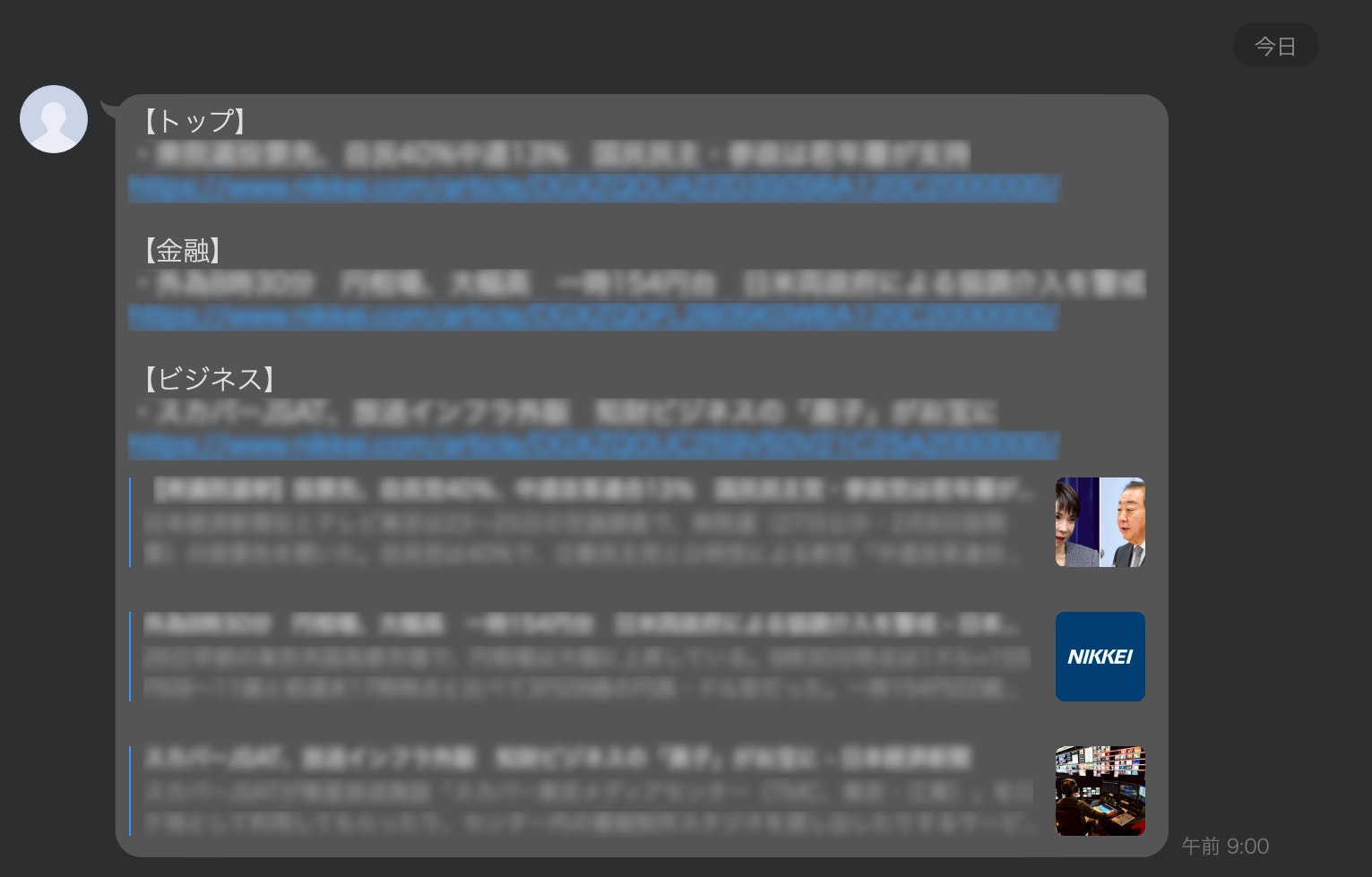
完成イメージ
実際に届くLINEメッセージはこんな感じです。
(※著作権のため、完成イメージは一部モザイクをしています。)
全体構成
今回は、プログラムを常時動かしておくために AWSのEC2(Linuxサーバ)を利用しました。
EC2上でPythonスクリプトを動かし、 cronを使って平日9時に自動実行する構成にしています。
| 要素 | 役割 | 補足 |
|---|---|---|
| AWS EC2 | 実行環境 | 常時起動しているLinuxサーバー |
| cron | 定期実行 | 平日9時に main.py を起動 |
| main.py | 処理の本体 | スクレイピング〜LINE送信 |
| 日経サイト | 情報取得元 | 公式APIは使用せずスクレイピング |
| LINE Messaging API | 通知手段 | 取得した記事をLINEへ送信 |
| LINE | 表示先 | 毎朝ニュースを確認 |
実装の流れ
今回作った仕組みは、処理の流れを次の4ステップに分けています。
①cronからmain.pyを実行して、平日9時に自動送信
②トップ/金融/ビジネスの各カテゴリで先頭の記事を取得(main.py 内)
③LINE送信用のメッセージ形式にまとめる(main.py 内)
④LINE Messaging APIで送信 (main.py 内)
ステップごとに分けて考えることで、
「今どこを実装しているのか」を把握しやすくなるようにしました。
cronが平日9時になるとmain.pyを起動し、
Pythonで日経サイトをスクレイピングして各カテゴリの先頭記事を取得、
最後にLINE Messaging APIを使って1通のメッセージとして送信しています。
コードはすべてmain.pyにまとめています。
スクレイピング部分は、最初にJupyter Labで動作確認をしてから、問題なく動いたコードをmain.pyに書き移しました。
全体コードまとめ
①cronからmain.pyを実行して、平日9時に自動送信
0 9 * * 1-5 /usr/bin/python3 /home/ec2-user/main.py >> /home/ec2-user/cron.log 2>&1
②トップ/金融/ビジネスの各カテゴリで先頭の記事を取得(main.py 内)
import requests
from bs4 import BeautifulSoup
HEADERS = {'User-Agent': 'Mozilla/5.0'}
# TOPページ:トップニュース取得
url_top = 'https://www.nikkei.com/'
response = requests.get(url_top, headers=HEADERS)
soup = BeautifulSoup(response.text, 'html.parser')
top_article = None
for a in soup.find_all('a', href=True):
track = a.get('data-rn-track-value', '')
if 'front-top' in track:
title = a.get_text(strip=True)
href = a.get('href')
top_article = {
'title': title,
'url': 'https://www.nikkei.com' + href
}
break
# 金融カテゴリ:先頭記事取得
url_finance = 'https://www.nikkei.com/markets/currencies/'
response_finance = requests.get(url_finance, headers=HEADERS)
soup_finance = BeautifulSoup(response_finance.text, 'html.parser')
articles_finance = {}
for a in soup_finance.find_all('a', href=True):
href = a.get('href')
title = a.get_text(strip=True)
if href and title:
full_url = 'https://www.nikkei.com' + href
articles_finance[full_url] = {
'title': title,
'url': full_url
}
finance_article = list(articles_finance.values())[0]
# ビジネス(情報通信):先頭記事取得
url_net = 'https://www.nikkei.com/business/net-media/'
response_net = requests.get(url_net, headers=HEADERS)
soup_net = BeautifulSoup(response_net.text, 'html.parser')
articles_net = {}
for a in soup_net.find_all('a', href=True):
href = a.get('href')
title = a.get_text(strip=True)
if href and title and '/article/' in href:
full_url = 'https://www.nikkei.com' + href
articles_net[full_url] = {
'title': title,
'url': full_url
}
net_article = list(articles_net.values())[0]
③LINE送信用のメッセージ形式に整形(main.py 内)
# トップニュース
message_lines = []
# トップニュース
message_lines.append('【トップニュース】')
message_lines.append(top_article['title'])
message_lines.append(top_article['url'])
message_lines.append('')
# 金融ニュース
message_lines.append('【金融】')
message_lines.append(finance_article['title'])
message_lines.append(finance_article['url'])
message_lines.append('')
# ビジネス(情報通信)
message_lines.append('【ビジネス】')
message_lines.append(net_article['title'])
message_lines.append(net_article['url'])
message_text = '\n'.join(message_lines)
④LINE Messaging APIで送信(main.py 内)
import requests
import os
# LINE Messaging APIの設定
LINE_CHANNEL_ACCESS_TOKEN = os.environ.get('LINE_CHANNEL_ACCESS_TOKEN')
LINE_USER_ID = os.environ.get('LINE_USER_ID')
headers = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {LINE_CHANNEL_ACCESS_TOKEN}'
}
payload = {
'to': LINE_USER_ID,
'messages': [
{
'type': 'text',
'text': message_text
}
]
}
url = 'https://api.line.me/v2/bot/message/push'
response = requests.post(url, headers=headers, json=payload)
苦労した点
① 記事取得方法の選び方
最初は、HTMLの class を指定して記事を取得しようとしましたが、
ページ構造が変わった場合に動かなくなる可能性があるとChatGPTから指摘を受けました。
そのため今回は、
比較的変更されにくそうな属性やURL構造を使って記事を取得するようにしました。
完璧ではないと思いますが、
「なるべく壊れにくい方法を選ぶ」という視点を持てたのは
今回学習できたポイントでもありました。
② APIでメッセージを送信する方法
APIでの送信部分では、
requests.post() や headers、payload 、Bearer など
見慣れないコードが多く、処理の流れを理解するのに時間がかかりました。
③ EC2の操作方法
そもそも最初は、
EC2に「定期実行(cron)」のような仕組みがあること自体を理解できていない状態でした。
そのため、
なぜ処理を main.py にまとめるのか、cronとは何かがわからず
ローカルで動いていたコードを
EC2上で自動実行させるまでの流れを理解するのに時間がかかりました。
ChatGPT・YouTube・サイトを参考にしつつ、「cronが main.py を決まった時間に実行している」という関係が分かってから、
ようやく全体像を整理できるようになりました。
まとめ
実装を通して、
ローカル環境とEC2上での実行の違いや、
cronとmain.pyの役割分担など、
「自動実行する仕組み」を理解することの難しさを実感しました。
ただ朝9:00に記事がLINEに届いたときは感動しましたし、やってみてよかったなと思います。