アウトプット内容
複数枚のクレジットカード利用データをまとめて、支出の内訳を円グラフで可視化してみました。
背景
クレジットカードを複数枚使っていると、
「結局、何にいくら使っているのか」が把握しづらくなっている現状です。
そこで今回は、複数のクレジットカード利用明細(CSV)をPythonで統合し、支出の内訳を円グラフで可視化してみました。
前提
今回のアウトプットでは、複数のクレジットカードを用途別に使い分けています。
そのため、カードごとにデータの取得方法や明細のまとめ方が異なります。
① クレジットカードの使い分け
| カード | 使い道 | データ取得方法 |
|---|---|---|
| 楽天カード | 日常の買い物全般(メイン) | CSV |
| イオンカード | ジムの支払い(指定カード) | CSV |
| EPOSカード | 家賃の支払い(指定カード) | |
| JREカード | 交通費のみ | CSV |
用途がある程度固定されているため、
カードごとに「どこまで細かく扱うか」を変えています。
② データ取得方法を統一していない理由
楽天カードは使い道が多いため、明細をカテゴリ別に分類して集計しています。
一方で、
イオンカード(ジム)やJREカード(交通費)は、支払い内容が1種類なので、
今回は合計金額のみを取得しています。
EPOSカードについては明細がPDF形式のため、今回のアウトプットではスキル的に対応が難しく、集計用のDataFrameだけ作成する形にしました。
③ APIによる自動取得について
APIを使って明細を自動取得することも検討しましたが、多くのカード会社では2段階認証が必要なため、今回は手作業でCSVを取得する前提にしています。
出力結果(カテゴリ別支出割合)
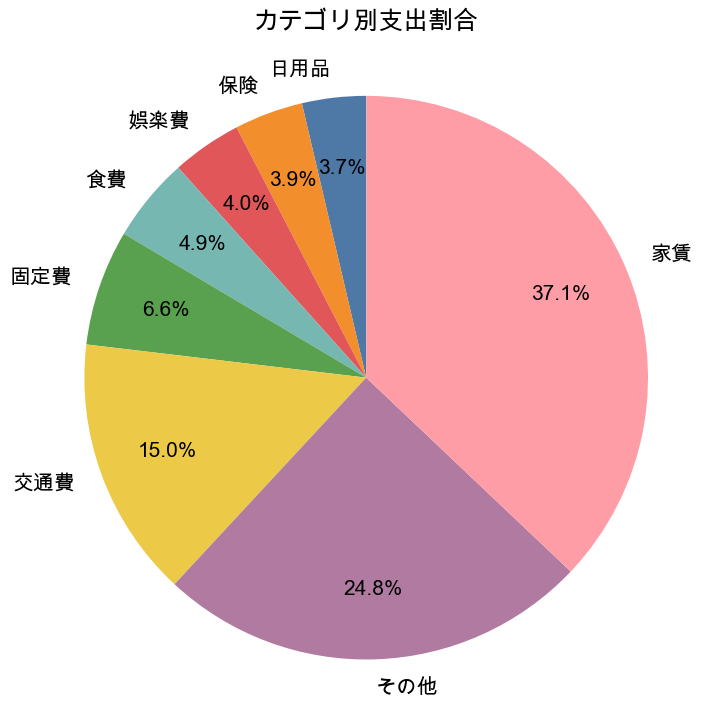
カテゴリ別の支出割合を円グラフで可視化しました。
支出の内訳を、全体感として把握できる形になっています。
※集計・可視化の詳細な処理は、後半のコードで記載します。
今回の学習ポイント6つ
① 文字列の正規化
全角・半角・記号の表記ゆれを統一し、店舗名の自動分類の精度を上げるためです。
unicodedata.normalize('NFKC', str(text))
② 出現頻度TOP20
自動分類のルールを作るにあたって、まず楽天カードの利用明細から店舗名の出現頻度を確認しました。
df_rakuten['shop'].value_counts().head(20)
出現頻度の多い店舗を元に、カテゴリ作成をしました。
category_rule = {
'固定費': ['楽天エナジー', '楽天ガス', '楽天でんき', 'au', 'uq', 'biglobe', 'ablenet', 'ソフトバンク'],
'保険': ['セイメイホケン'],
'食費': ['セブン', 'ローソン', 'ヨシノヤ', 'uber', 'ドト-ルコ-ヒ-', 'マクドナルド', 'スキヤ'],
'娯楽費': ['カーニー', 'ピクシブ'],
'日用品': ['amazon', 'rakuten', 'サンドラツグ', 'マツモトキヨシ', 'GOOGLE', 'クリニツクプラス', 'ヤツキヨク'],
'交通費': ['タクシー']
}
③ 自動分類
あらかじめ用意したキーワード一覧を使って、カテゴリを判定するためです。
各カテゴリ(cat)に紐づけたキーワード(kw)を1つずつ確認し、店舗名に含まれているかどうかで分類しました。
def classify(shop):
shop = normalize(shop)
for cat, kws in category_rule_norm.items():
for kw in kws:
if kw in shop:
return cat
return 'その他'
④ with open() を使ったファイル処理
JREカードとイオンカードは合計金額のみを抽出できればよかったため、read_csv()ではなく、行単位で処理できるwith open() を使いました。
with open('jre_2512.csv', encoding='cp932') as f:
⑤ 文字列から数値抽出
「今回お支払金額 54,536円」などの文字列から数字を抽出するためです。
re.sub(r'[^\d]', '', line)
⑥ 円グラフの色指定・表示調整
デフォルトではなく色合いのある配色を活用し、rcParams によるフォント・サイズ一括管理するためです。
colors = [...]
plt.pie(..., colors=colors)
全体コードまとめ
今回使用したコードを1つにまとめたものです。
import pandas as pd
import unicodedata
import re
import matplotlib.pyplot as plt
# 半角・全角を統一
def normalize(text):
text = unicodedata.normalize('NFKC', str(text))
return text.lower().strip()
# カテゴリ作成
category_rule = {
'固定費': ['楽天エナジー', '楽天ガス', '楽天でんき', 'au', 'uq', 'biglobe', 'ablenet', 'ソフトバンク'],
'保険': ['セイメイホケン'],
'食費': ['セブン', 'ローソン', 'ヨシノヤ', 'uber', 'ドト-ルコ-ヒ-', 'マクドナルド', 'スキヤ'],
'娯楽費': ['カーニー', 'ピクシブ'],
'日用品': ['amazon', 'rakuten', 'サンドラツグ', 'マツモトキヨシ', 'GOOGLE', 'クリニツクプラス', 'ヤツキヨク'],
'交通費': ['タクシー']}
# 辞書を正規化
category_rule_norm = {
cat: [normalize(kw) for kw in kws]
for cat, kws in category_rule.items()}
# 自動分類
def classify(shop):
shop = normalize(shop)
for cat, kws in category_rule_norm.items():
for kw in kws:
if kw in shop:
return cat
return 'その他'
df_rakuten['category'] = df_rakuten['shop'].apply(classify)
# 楽天カード取得
df = pd.read_csv('rakuten_2512.csv')
df_rakuten = pd.DataFrame({
'date': df['利用日'],
'shop': df['利用店名・商品名'],
'amount': df['利用金額'],
'card_name': 'Rakuten'})
df_rakuten['category'] = df_rakuten['shop'].apply(classify)
# JREカード(合計のみ)取得
total_jre_amount = None
with open('jre_2512.csv', encoding='cp932') as f:
for line in f:
if '今回お支払金額' in line:
total_jre_amount = int(re.sub(r'[^\d]', '', line))
break
df_jre = pd.DataFrame([{
'date': '2025-12',
'shop': 'JREカード合計',
'amount': total_jre_amount,
'card_name': 'JRE',
'category': '交通費'}])
# イオンカード(合計のみ)取得
total_aeon_amount = None
with open('aeon_2512.csv', encoding='cp932') as f:
for line in f:
if '今回ご請求金額' in line:
total_aeon_amount = int(re.sub(r'[^\d]', '', line))
break
df_aeon = pd.DataFrame([{
'date': '2025-12',
'shop': 'イオンカード合計',
'amount': total_aeon_amount,
'card_name':'AEON',
'category': '娯楽費' }])
# EPOSカード(家賃のみ)
df_epos = pd.DataFrame([{
'date': '2025-12',
'shop': '家賃',
'amount': *****,
'card_name': 'EPOS',
'category': '家賃'}])
# 全てのカードを統合して集計
df_all = pd.concat(
[df_rakuten, df_aeon, df_jre, df_epos],
ignore_index=True)
df_all.groupby('category')['amount'].sum()
df_all.groupby('card_name')['amount'].sum()
df_all.pivot_table(
index='category',
columns='card_name',
values='amount',
aggfunc='sum').fillna(0)
# 円グラフ作成
summary = (df_all.groupby('category', as_index=False)['amount'].sum())
total = summary['amount'].sum()
summary['ratio'] = summary['amount'] / total * 100
summary = summary.sort_values('amount', ascending=True)
# 円グラフのサイズ・色調整
colors = [
"#4E79A7", "#F28E2B", "#E15759",
"#76B7B2", "#59A14F", "#EDC948",
"#B07AA1", "#FF9DA7"]
plt.rcParams['font.family'] = 'Arial Unicode MS'
plt.rcParams['figure.figsize'] = [8,8]
plt.rcParams['font.size'] = 15
plt.pie(
summary['amount'],
labels=summary['category'],
autopct='%.1f%%',
startangle=90,
pctdistance=0.75,
textprops={'fontsize': 15} ,
colors=colors)
plt.title('カテゴリ別支出割合',pad = 30)
plt.axis('equal')
plt.savefig("pie_chart.png", bbox_inches="tight")
plt.show()
振り返り
- データ構造に合わせて処理を分けることで、無理のない範囲で可視化まで進めることができました。
- 今回は自分の利用状況に合わせたコードのため、汎用性については今後の課題だと考えています。
- 最初に全体の流れを考えておくことで、何を実装すればいいかが整理しやすくなることをコードの途中から実感しました。
次のステップ
-
カテゴリ判定のルールを見直す
→ 「その他」に分類される明細を減らし、支出の内訳をより正確に把握できるようにすること
-
APIを利用した明細データ取得の自動化を検討
→ 2段階認証が不要なサービスを対象にして実践