はじめに
以前に、Genesisやりましたが、今回はMujocoに挑戦してみました。予備知識なしで、ChatGPTと相談しながらの体験記です。よろしくお願いいたします。
miniconda インストールと仮想環境構築
以下のサイトでminiconda インストーラーをダウンロードし、実行します。
https://www.anaconda.com/download/success
Anaconda Powershell Prompt というソフトが一覧にでますので、実行します。
ターミナルが開くので、以下を実行します。以下、username は abc としています。
(base) C:\Users\abc>conda create -n mujoco python=3.10
最初の3行は a を入力して accept します。
Do you accept the Terms of Service (ToS) for https://repo.anaconda.com/pkgs/main? [(a)ccept/(r)eject/(v)iew]: a
Do you accept the Terms of Service (ToS) for https://repo.anaconda.com/pkgs/r? [(a)ccept/(r)eject/(v)iew]: a
Do you accept the Terms of Service (ToS) for https://repo.anaconda.com/pkgs/msys2? [(a)ccept/(r)eject/(v)iew]: a
続いて、以下が表示されます。
3 channel Terms of Service accepted
Retrieving notices: done
Channels:
- defaults
Platform: win-64
Collecting package metadata (repodata.json): done
Solving environment: done
==> WARNING: A newer version of conda exists. <==
current version: 26.1.1
latest version: 26.3.2
Please update conda by running
$ conda update -n base -c defaults conda
## Package Plan ##
environment location: C:\Users\abc\AppData\Local\miniconda3\envs\mujoco
added / updated specs:
- python=3.10
The following packages will be downloaded:
package | build
---------------------------|-----------------
ca-certificates-2026.3.19 | haa95532_0 126 KB
libexpat-2.8.0 | hd7fb8db_0 122 KB
libffi-3.4.8 | h2b21627_2 118 KB
libzlib-1.3.1 | h1c6eee0_1 62 KB
openssl-3.5.6 | hbb43b14_0 8.9 MB
packaging-26.0 | py310haa95532_0 166 KB
pip-26.0.1 | pyhc872135_1 1.1 MB
python-3.10.20 | h1044e36_0 15.5 MB
setuptools-82.0.1 | py310haa95532_0 1.2 MB
sqlite-3.51.2 | hee5a0db_0 917 KB
tzdata-2026a | he532380_0 117 KB
wheel-0.46.3 | py310haa95532_0 78 KB
zlib-1.3.1 | h1c6eee0_1 104 KB
------------------------------------------------------------
Total: 28.5 MB
The following NEW packages will be INSTALLED:
bzip2 pkgs/main/win-64::bzip2-1.0.8-h2bbff1b_6
ca-certificates pkgs/main/win-64::ca-certificates-2026.3.19-haa95532_0
libexpat pkgs/main/win-64::libexpat-2.8.0-hd7fb8db_0
libffi pkgs/main/win-64::libffi-3.4.8-h2b21627_2
libzlib pkgs/main/win-64::libzlib-1.3.1-h1c6eee0_1
openssl pkgs/main/win-64::openssl-3.5.6-hbb43b14_0
packaging pkgs/main/win-64::packaging-26.0-py310haa95532_0
pip pkgs/main/noarch::pip-26.0.1-pyhc872135_1
python pkgs/main/win-64::python-3.10.20-h1044e36_0
setuptools pkgs/main/win-64::setuptools-82.0.1-py310haa95532_0
sqlite pkgs/main/win-64::sqlite-3.51.2-hee5a0db_0
tk pkgs/main/win-64::tk-8.6.15-hf199647_0
tzdata pkgs/main/noarch::tzdata-2026a-he532380_0
ucrt pkgs/main/win-64::ucrt-10.0.22621.0-haa95532_0
vc pkgs/main/win-64::vc-14.3-h2df5915_10
vc14_runtime pkgs/main/win-64::vc14_runtime-14.44.35208-h4927774_10
vs2015_runtime pkgs/main/win-64::vs2015_runtime-14.44.35208-ha6b5a95_10
wheel pkgs/main/win-64::wheel-0.46.3-py310haa95532_0
xz pkgs/main/win-64::xz-5.8.2-h53af0af_0
zlib pkgs/main/win-64::zlib-1.3.1-h1c6eee0_1
Proceed ([y]/n)?
ここで、y を入力すると表示が変わっていきます。
## Package Plan ##
environment location: C:\Users\abc\AppData\Local\miniconda3\envs\mujoco
added / updated specs:
- python=3.10
The following packages will be downloaded:
package | build
---------------------------|-----------------
ca-certificates-2026.3.19 | haa95532_0 126 KB
libexpat-2.8.0 | hd7fb8db_0 122 KB
libffi-3.4.8 | h2b21627_2 118 KB
libzlib-1.3.1 | h1c6eee0_1 62 KB
openssl-3.5.6 | hbb43b14_0 8.9 MB
packaging-26.0 | py310haa95532_0 166 KB
pip-26.0.1 | pyhc872135_1 1.1 MB
python-3.10.20 | h1044e36_0 15.5 MB
setuptools-82.0.1 | py310haa95532_0 1.2 MB
sqlite-3.51.2 | hee5a0db_0 917 KB
tzdata-2026a | he532380_0 117 KB
wheel-0.46.3 | py310haa95532_0 78 KB
zlib-1.3.1 | h1c6eee0_1 104 KB
------------------------------------------------------------
Total: 28.5 MB
The following NEW packages will be INSTALLED:
bzip2 pkgs/main/win-64::bzip2-1.0.8-h2bbff1b_6
ca-certificates pkgs/main/win-64::ca-certificates-2026.3.19-haa95532_0
libexpat pkgs/main/win-64::libexpat-2.8.0-hd7fb8db_0
libffi pkgs/main/win-64::libffi-3.4.8-h2b21627_2
libzlib pkgs/main/win-64::libzlib-1.3.1-h1c6eee0_1
openssl pkgs/main/win-64::openssl-3.5.6-hbb43b14_0
packaging pkgs/main/win-64::packaging-26.0-py310haa95532_0
pip pkgs/main/noarch::pip-26.0.1-pyhc872135_1
python pkgs/main/win-64::python-3.10.20-h1044e36_0
done
#
# To activate this environment, use
#
# $ conda activate mujoco
#
# To deactivate an active environment, use
#
# $ conda deactivate
mujoco を activate します。
(base) C:\Users\abc>conda activate mujoco
するとプロンプトが変わります。
gymnasium、MuJoCo、必要ライブラリをインストール
gymnasium、MuJoCo、必要ライブラリをインストールします。
(mujoco) C:\Users\abc>pip install gymnasium[mujoco]
インストールが進み、以下が表示されます。
Collecting gymnasium[mujoco]
Downloading gymnasium-1.3.0-py3-none-any.whl.metadata (10 kB)
Collecting numpy>=1.21.0 (from gymnasium[mujoco])
Downloading numpy-2.2.6-cp310-cp310-win_amd64.whl.metadata (60 kB)
Collecting cloudpickle>=1.2.0 (from gymnasium[mujoco])
Downloading cloudpickle-3.1.2-py3-none-any.whl.metadata (7.1 kB)
Collecting typing-extensions>=4.3.0 (from gymnasium[mujoco])
Downloading typing_extensions-4.15.0-py3-none-any.whl.metadata (3.3 kB)
Collecting farama-notifications>=0.0.1 (from gymnasium[mujoco])
Downloading farama_notifications-0.0.6-py3-none-any.whl.metadata (729 bytes)
Collecting mujoco>=2.1.5 (from gymnasium[mujoco])
Downloading mujoco-3.8.1-cp310-cp310-win_amd64.whl.metadata (43 kB)
Collecting imageio>=2.14.1 (from gymnasium[mujoco])
Downloading imageio-2.37.3-py3-none-any.whl.metadata (9.7 kB)
Requirement already satisfied: packaging>=23.0 in .\appdata\local\miniconda3\envs\mujoco\lib\site-packages (from gymnasium[mujoco]) (26.0)
Collecting pillow>=8.3.2 (from imageio>=2.14.1->gymnasium[mujoco])
Downloading pillow-12.2.0-cp310-cp310-win_amd64.whl.metadata (9.0 kB)
Collecting absl-py (from mujoco>=2.1.5->gymnasium[mujoco])
Downloading absl_py-2.4.0-py3-none-any.whl.metadata (3.3 kB)
Collecting etils[epath] (from mujoco>=2.1.5->gymnasium[mujoco])
Downloading etils-1.13.0-py3-none-any.whl.metadata (6.5 kB)
Collecting glfw (from mujoco>=2.1.5->gymnasium[mujoco])
Downloading glfw-2.10.0-py2.py27.py3.py30.py31.py32.py33.py34.py35.py36.py37.py38.py39.py310.py311.py312.py313.py314-none-win_amd64.whl.metadata (5.4 kB)
Collecting pyopengl (from mujoco>=2.1.5->gymnasium[mujoco])
Downloading pyopengl-3.1.10-py3-none-any.whl.metadata (3.3 kB)
Collecting fsspec (from etils[epath]->mujoco>=2.1.5->gymnasium[mujoco])
Downloading fsspec-2026.4.0-py3-none-any.whl.metadata (10 kB)
Collecting importlib_resources (from etils[epath]->mujoco>=2.1.5->gymnasium[mujoco])
Downloading importlib_resources-7.1.0-py3-none-any.whl.metadata (4.0 kB)
Collecting zipp (from etils[epath]->mujoco>=2.1.5->gymnasium[mujoco])
Downloading zipp-3.23.1-py3-none-any.whl.metadata (3.6 kB)
Downloading gymnasium-1.3.0-py3-none-any.whl (953 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 953.9/953.9 kB 1.7 MB/s 0:00:00
Downloading cloudpickle-3.1.2-py3-none-any.whl (22 kB)
Downloading farama_notifications-0.0.6-py3-none-any.whl (2.9 kB)
Downloading imageio-2.37.3-py3-none-any.whl (317 kB)
Downloading mujoco-3.8.1-cp310-cp310-win_amd64.whl (5.8 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 5.8/5.8 MB 4.7 MB/s 0:00:01
Downloading numpy-2.2.6-cp310-cp310-win_amd64.whl (12.9 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 12.9/12.9 MB 7.4 MB/s 0:00:01
Downloading pillow-12.2.0-cp310-cp310-win_amd64.whl (7.1 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 7.1/7.1 MB 5.6 MB/s 0:00:01
Downloading typing_extensions-4.15.0-py3-none-any.whl (44 kB)
Downloading absl_py-2.4.0-py3-none-any.whl (135 kB)
Downloading etils-1.13.0-py3-none-any.whl (170 kB)
Downloading fsspec-2026.4.0-py3-none-any.whl (203 kB)
Downloading glfw-2.10.0-py2.py27.py3.py30.py31.py32.py33.py34.py35.py36.py37.py38.py39.py310.py311.py312.py313.py314-none-win_amd64.whl (559 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 559.5/559.5 kB 2.4 MB/s 0:00:00
Downloading importlib_resources-7.1.0-py3-none-any.whl (37 kB)
Downloading pyopengl-3.1.10-py3-none-any.whl (3.2 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 3.2/3.2 MB 3.9 MB/s 0:00:00
Downloading zipp-3.23.1-py3-none-any.whl (10 kB)
Installing collected packages: pyopengl, glfw, farama-notifications, zipp, typing-extensions, pillow, numpy, importlib_resources, fsspec, etils, cloudpickle, absl-py, imageio, gymnasium, mujoco
Successfully installed absl-py-2.4.0 cloudpickle-3.1.2 etils-1.13.0 farama-notifications-0.0.6 fsspec-2026.4.0 glfw-2.10.0 gymnasium-1.3.0 imageio-2.37.3 importlib_resources-7.1.0 mujoco-3.8.1 numpy-2.2.6 pillow-12.2.0 pyopengl-3.1.10 typing-extensions-4.15.0 zipp-3.23.1
インストールしたPythonのバージョンを確認すると、3.10.20と表示されました。
(mujoco) C:\Users\abc>python --version
Python 3.10.20
お試しプログラム(4足ロボット)
以下を test_1.py で保存します。
import gymnasium as gym
env = gym.make("HalfCheetah-v5", render_mode="human")
obs, info = env.reset()
for _ in range(1000):
action = env.action_space.sample()
obs, reward, terminated, truncated, info = env.step(action)
if terminated or truncated:
obs, info = env.reset()
env.close()
以下で実行すると、mujoco の窓が開いて実行画面が表示されます。
python test_1.py
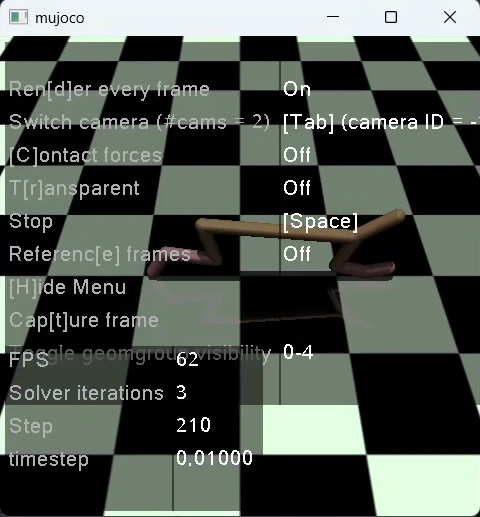
print文を3行加えた test_2.py を作成します。
import gymnasium as gym
env = gym.make("HalfCheetah-v5", render_mode="human")
obs, info = env.reset()
for _ in range(1000):
action = env.action_space.sample()
obs, reward, terminated, truncated, info = env.step(action)
print(action)
print(obs)
print(reward)
if terminated or truncated:
obs, info = env.reset()
env.close()
実行します。
python test_2.py
Mujoco窓の表示とともに、ターミナルに以下の数字が次々に表示されます。
最初の [ ] は、action で、モータ入力、関節トルクに対応します。
次の [ ] は、observation で、位置、速度、関節角度に対応します。
最後 は、reward で、前進、バランス維持に応じて変化する「良い動きの点数」です。
[-0.4690192 -0.39226764 -0.04482962 -0.43842077 -0.53744537 -0.653016 ]
[-0.57511419 3.3064715 0.19178872 0.29828296 0.01555205 -0.10465633
-0.190319 0.01033585 0.3892081 0.08942916 0.15315391 -0.57463652
-9.16393234 3.11024994 -4.42121692 -3.77340738 1.15960534]
-0.03248974847919861
次に進みます。
pip install stable-baselines3[extra]
標準的なRLアルゴリズムの PPO (Proximal Policy Optimization) を
Stable-Baselines3 ライブラリから読み込みには、以下を実行します。
from stable_baselines3 import PPO
簡単な強化学習例のプログラムを train.py の名前で保存します。この中で、observation、reward から、「どう動けば高得点か」を学習するのが、以下の部分です。
model.learn(total_timesteps=10000)
import gymnasium as gym
from stable_baselines3 import PPO
# MuJoCo環境作成
env = gym.make(
"HalfCheetah-v5",
render_mode="human"
)
# PPOモデル作成
model = PPO(
"MlpPolicy",
env,
verbose=1
)
# 学習
model.learn(total_timesteps=10000)
# 学習済みモデル保存
model.save("ppo_halfcheetah")
# 動作確認
obs, info = env.reset()
for _ in range(1000):
# 学習済みモデルが行動を決定
action, _states = model.predict(obs)
# シミュレーション1ステップ
obs, reward, terminated, truncated, info = env.step(action)
print("reward =", reward)
if terminated or truncated:
obs, info = env.reset()
env.close()
ターミナルには以下が表示されます。
Using cpu device
Wrapping the env with a `Monitor` wrapper
Wrapping the env in a DummyVecEnv.
---------------------------------
| rollout/ | |
| ep_len_mean | 1e+03 |
| ep_rew_mean | -329 |
| time/ | |
| fps | 59 |
| iterations | 1 |
| time_elapsed | 34 |
| total_timesteps | 2048 |
---------------------------------
-----------------------------------------
| rollout/ | |
| ep_len_mean | 1e+03 |
| ep_rew_mean | -362 |
| time/ | |
| fps | 58 |
| iterations | 2 |
| time_elapsed | 70 |
| total_timesteps | 4096 |
| train/ | |
| approx_kl | 0.010602163 |
| clip_fraction | 0.116 |
| clip_range | 0.2 |
| entropy_loss | -8.5 |
| explained_variance | -0.0226 |
| learning_rate | 0.0003 |
| loss | 11.5 |
| n_updates | 10 |
| policy_gradient_loss | -0.0236 |
| std | 0.997 |
| value_loss | 36.9 |
-----------------------------------------
-----------------------------------------
| rollout/ | |
| ep_len_mean | 1e+03 |
| ep_rew_mean | -384 |
| time/ | |
| fps | 58 |
| iterations | 3 |
| time_elapsed | 105 |
| total_timesteps | 6144 |
| train/ | |
| approx_kl | 0.010074905 |
| clip_fraction | 0.0908 |
| clip_range | 0.2 |
| entropy_loss | -8.48 |
| explained_variance | 0.0572 |
| learning_rate | 0.0003 |
| loss | 22.3 |
| n_updates | 20 |
| policy_gradient_loss | -0.0202 |
| std | 0.992 |
| value_loss | 56.9 |
-----------------------------------------
reward は長いので最初の5行を示します。
reward = -0.4956451546934893
reward = -0.4128020136183315
reward = -0.2205283941595545
reward = 0.13161140805508714
reward = 0.3522563840761769
reward の最後の5行です。
reward = 0.04843478134628576
reward = -1.3088060750420212
reward = 0.34733931336473667
reward = -0.31211283965304126
reward = -0.7498595298325075
少し修正して、train_2.py として保存します。
action や reward が見えるようにしています。
print("action =", action)
print("reward =", reward)
model.learn(total_timesteps=100000) timesteps を増やしました。
env = gym.make("HalfCheetah-v5") 学習中は描画を中止しました。
以下のように、評価用に描画する機能をつけています。
eval_env = gym.make(
"HalfCheetah-v5",
render_mode="human"
)
modelの保存、読み出しをします。
model.save("ppo_halfcheetah")
model = PPO.load("ppo_halfcheetah")
ランダム性を減らして、学習結果を見やすくしています。
model.predict(... deterministic=True)
import gymnasium as gym
from stable_baselines3 import PPO
# =========================
# 学習用環境(描画なし)
# =========================
train_env = gym.make("HalfCheetah-v5")
# =========================
# PPOモデル作成
# =========================
model = PPO(
"MlpPolicy",
train_env,
verbose=1
)
# =========================
# 学習
# =========================
model.learn(total_timesteps=100000)
# =========================
# モデル保存
# =========================
model.save("ppo_halfcheetah")
# 学習環境終了
train_env.close()
# =========================
# 評価用環境(描画あり)
# =========================
eval_env = gym.make(
"HalfCheetah-v5",
render_mode="human"
)
obs, info = eval_env.reset()
episode_reward = 0.0
# =========================
# 学習済みモデルで動作確認
# =========================
for step in range(1000):
# 学習済みモデルが行動を決定
action, _states = model.predict(
obs,
deterministic=True
)
# 1ステップ進める
obs, reward, terminated, truncated, info = eval_env.step(action)
# 報酬加算
episode_reward += reward
# 状態表示
print(f"step = {step}")
print("action =", action)
print("reward =", reward)
print("episode_reward =", episode_reward)
print()
# エピソード終了判定
if terminated or truncated:
print("Episode finished")
print("Total episode reward =", episode_reward)
print()
obs, info = eval_env.reset()
episode_reward = 0.0
eval_env.close()
train_2.py を実行します。
python train_2.py
以下が表示されます。
Using cpu device
Wrapping the env with a `Monitor` wrapper
Wrapping the env in a DummyVecEnv.
---------------------------------
| rollout/ | |
| ep_len_mean | 1e+03 |
| ep_rew_mean | -301 |
| time/ | |
| fps | 1562 |
| iterations | 1 |
| time_elapsed | 1 |
| total_timesteps | 2048 |
---------------------------------
-----------------------------------------
| rollout/ | |
| ep_len_mean | 1e+03 |
| ep_rew_mean | -326 |
| time/ | |
| fps | 1042 |
| iterations | 2 |
| time_elapsed | 3 |
| total_timesteps | 4096 |
| train/ | |
| approx_kl | 0.009963954 |
| clip_fraction | 0.107 |
| clip_range | 0.2 |
| entropy_loss | -8.49 |
| explained_variance | -0.0213 |
| learning_rate | 0.0003 |
| loss | 5.33 |
| n_updates | 10 |
| policy_gradient_loss | -0.0198 |
| std | 0.994 |
| value_loss | 25.8 |
-----------------------------------------
..... 途中、省略
-----------------------------------------
| rollout/ | |
| ep_len_mean | 1e+03 |
| ep_rew_mean | -247 |
| time/ | |
| fps | 814 |
| iterations | 49 |
| time_elapsed | 123 |
| total_timesteps | 100352 |
| train/ | |
| approx_kl | 0.018926369 |
| clip_fraction | 0.217 |
| clip_range | 0.2 |
| entropy_loss | -6.89 |
| explained_variance | 0.436 |
| learning_rate | 0.0003 |
| loss | 7 |
| n_updates | 480 |
| policy_gradient_loss | -0.0468 |
| std | 0.76 |
| value_loss | 14.3 |
-----------------------------------------
step = 0
action = [-0.02175267 0.30369982 0.18869618 -0.05244339 0.09539972 -0.15118413]
reward = -0.10944947973532537
episode_reward = -0.10944947973532537
step = 1
action = [ 0.66264415 0.44866985 0.5343544 -0.23900607 0.3509975 -0.24790289]
reward = 0.06423681628069866
episode_reward = -0.04521266345462671
step = 2
action = [ 0.4551286 0.04348888 0.19891143 -1. -0.1137085 0.06919625]
reward = -0.36207879443496815
episode_reward = -0.40729145788959487
step = 3
action = [ 0.8246351 0.7891798 -0.6026738 -0.22114672 -0.33056822 0.06510978]
reward = -0.3188610094204375
episode_reward = -0.7261524673100324
step = 4
action = [0.24244113 0.9991389 0.14572112 0.02882219 0.19112948 0.78972477]
reward = -0.2510946977725554
episode_reward = -0.9772471650825878
step = 5
action = [0.8916024 0.7098668 0.10329821 0.13063903 0.22861105 0.5338265 ]
reward = 0.010869410366164456
episode_reward = -0.9663777547164234
..... 途中、省略
step = 994
action = [ 0.27582875 0.9940285 0.19338393 -1. -0.7063558 0.12023824]
reward = -0.4864532121685272
episode_reward = 490.3367638344697
step = 995
action = [ 0.10379335 1. 0.15973903 -0.77909005 -0.3028011 0.5953676 ]
reward = -0.3236384665097205
episode_reward = 490.01312536796
step = 996
action = [ 0.05009459 -0.75707287 0.12526731 0.8731726 0.84345764 0.29362303]
reward = -0.6572707466358167
episode_reward = 489.35585462132417
step = 997
action = [-0.31607327 -1. -0.0792566 -0.14742835 -0.00860788 -0.29452598]
reward = 0.2406161126269808
episode_reward = 489.59647073395115
step = 998
action = [-0.816169 -0.66011983 -0.15579075 0.43639624 -0.6302066 -0.0803916 ]
reward = 1.2506609470636931
episode_reward = 490.84713168101484
step = 999
action = [-0.5012408 0.20824292 0.00384989 0.43335795 0.00100581 0.29468468]
reward = 0.3464003217864615
episode_reward = 491.1935320028013
Episode finished
Total episode reward = 491.1935320028013
次は、この学習済みPPOと完全ランダムで本当に差があるのかを比較します。
そのため、以下の部分を
action, _states = model.predict(
obs,
deterministic=True
)
こちらに変更して、train_3.py の名前で保存します。
action = eval_env.action_space.sample()
train_3.py を実行します。
python train_3.py
最後の reward の部分のみ以下に示します。reward が -322 になり、明らかに学習済み PPO の 491 と差があることが確認できました。
step = 999
action = [ 0.93022263 0.65502393 0.73661524 -0.7024038 -0.5735753 -0.6856789 ]
reward = -0.11973034797472337
episode_reward = -321.62810872518173
Episode finished
Total episode reward = -321.62810872518173
お試しプログラム(倒立振り子)
次は、振り子でやってみます。以下を train_4.py で保存します。
import gymnasium as gym
from stable_baselines3 import PPO
# =========================
# 学習用環境(描画なし)
# =========================
train_env = gym.make("InvertedPendulum-v5")
# =========================
# PPOモデル作成
# =========================
model = PPO(
"MlpPolicy",
train_env,
verbose=1
)
# =========================
# 学習
# =========================
model.learn(total_timesteps=50000)
# =========================
# モデル保存
# =========================
model.save("ppo_halfcheetah")
# 学習環境終了
train_env.close()
# =========================
# 評価用環境(描画あり)
# =========================
eval_env = gym.make(
"InvertedPendulum-v5",
render_mode="human",
width=1400,
height=900
)
obs, info = eval_env.reset()
eval_env.unwrapped.mujoco_renderer.viewer.cam.distance = 2.0
eval_env.unwrapped.mujoco_renderer.viewer.cam.elevation = -20
episode_reward = 0.0
# =========================
# 学習済みモデルで動作確認
# =========================
for step in range(1000):
# 学習済みモデルが行動を決定
action, _states = model.predict(
obs,
deterministic=True
)
# 1ステップ進める
obs, reward, terminated, truncated, info = eval_env.step(action)
# 報酬加算
episode_reward += reward
# 状態表示
print(f"step = {step}")
print("action =", action)
print("reward =", reward)
print("episode_reward =", episode_reward)
print()
# エピソード終了判定
if terminated or truncated:
print("Episode finished")
print("Total episode reward =", episode_reward)
print()
obs, info = eval_env.reset()
episode_reward = 0.0
eval_env.close()
train_4.py を実行します。
python train_4.py
実行結果の最後の部分は以下の通りです。
step = 999
action = [-1.816079e-08]
reward = 1
episode_reward = 1000.0
Episode finished
Total episode reward = 1000.0
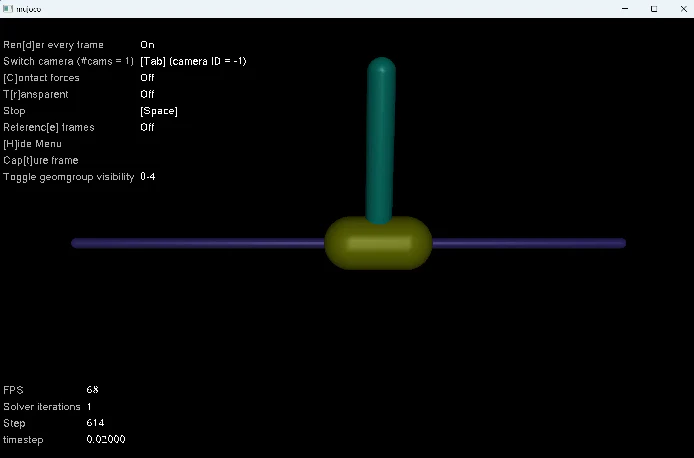
描画の様子は以下の通りです。安定していました。
model.learn(total_timesteps=######) この数値を変化させました。振り子の安定には、30000程度以上が必要なようです。
終わりに
初めてのMujocoでしたが、ChatGPTのナビゲートでスムーズに体験することができました。