はじめに
この記事はDevOps on AWS大全の一部です。
DevOps on AWS大全の一覧はこちら。
この記事ではAmazon Athenaに関連する内容を超詳細にまとめています。
具体的には以下流れで説明します。
- Amazon Athenaとは
- Amazon Athenaの活用
- Amazon Athena for Advance
- Amazon Athenaのベストプラクティス
AWSの区分でいう「Level 200:トピックの入門知識を持っていることを前提に、ベストプラクティス、サービス機能を解説するレベル」の内容です。
この記事を読んでほしい人
- Amazon Athenaがどういうサービスか説明できるようになりたい人
- Amazon Athenaを採用するときのベストプラクティスを説明できるようになりたい人
- AWS Certified DevOps Engineer Professionalを目指している人
Amazon Athenaとは
Amazon Athenaは、サーバーレスなクエリサービスであり、Amazon S3に保存されたデータに対してSQLクエリを実行することができます。
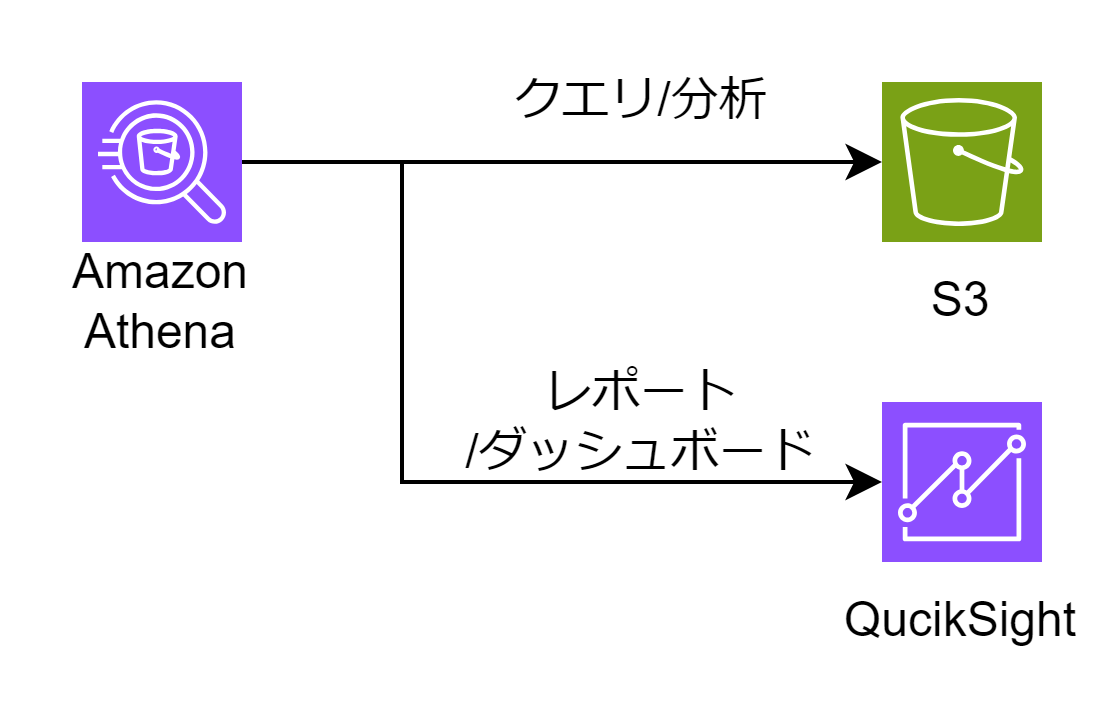
Athenaは、インフラストラクチャの管理やスケーリングに悩まずに、SQLを使ってデータを分析することができるため、簡易なデータ分析ツールとして非常に有用です。
また、Amazon Athenaは一般的に可視化サービスのAmazon QuickSightとセットで使われます。
Amazon Athenaで分析した結果をAmazon QuickSighetでレポーティングやダッシュボードとして利用者に提供するという使い方です。
Amazon Athenaの活用
データレイクのクエリ
Amazon Athenaを使用すると、Amazon S3に保存されたデータに対してSQLクエリを実行できます。
これにより、データレイク内の膨大なデータセットから必要な情報を迅速に取得できます。
S3に保存したデータに対してクエリ発行できるので実プロジェクトではBI用途のみならず、インシデント調査にも活用されています。
具体的にはVPC FlowLogsやELB Logsといったネットワーク系のログの分析やCloudTrailのトレイルログといった監査系のログ分析から、不審なアクセスや操作がないかを分析します。
フェデレーテッドクエリ
Amazon Athena Federated Queryは、異なるデータソースからのデータをAthenaで統合的にクエリできる機能です。
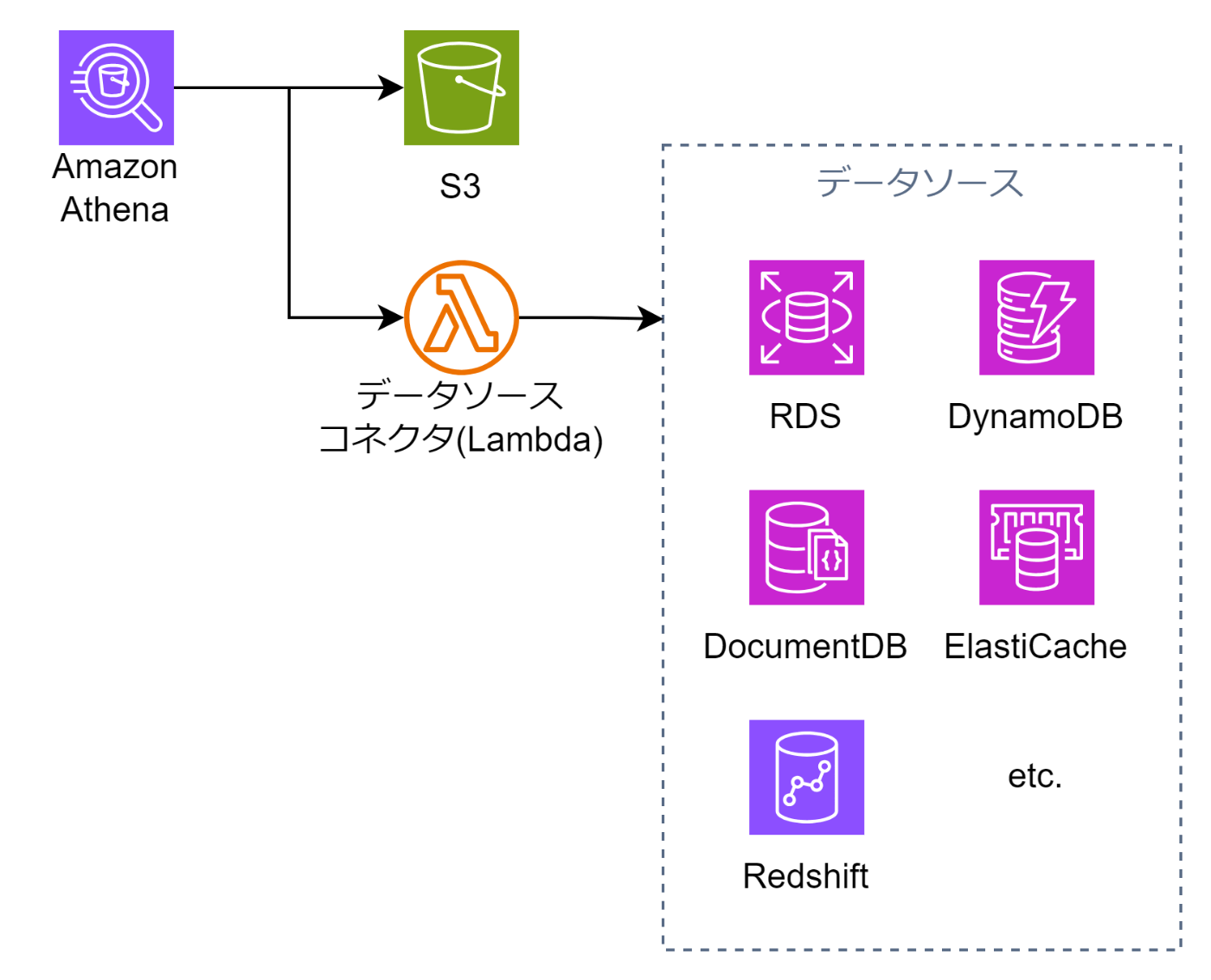
対応データソースにはAmazon RDS、Redshift、Aurora、S3などがあり、SQLを使用してこれらのデータソースに対して横ぐしを通したクエリを発行できます。
Amazon Athenaの説明文はこのブログも含めてS3に対してクエリ発行可能という記載が多いですが、このフェデレーテッドクエリを使うことでS3以外のデータソースに対してもクエリ発行をすることができます。
S3以外のデータソースに接続するときにはLambdaの上に構築されるデータソースコネクターを利用する必要があることに注意しましょう。
分析用途のダッシュボード作成
Athenaの結果をAmazon QuickSightでビジュアライズすることで、ビジネスインテリジェンスや分析用途のダッシュボードを簡単に作成できます。
これにより、簡易なデータ分析基盤としてAthena+QuickSight+S3を用いることができるようになります。
もちろん、ELTツールなどもないので本格的な分析は難しいですが実プロジェクトではこの簡易さが結構重宝します。
具体的には、PoCとしてのデータ分析を行う際に非常に有用です。
手元にあるデータが本当に有用なのかはある程度分析をしてみないとわからないものの、有用性が判断できない時点で重厚長大なデータ分析基盤を作ることは一般的にコストの関係から難しいです。
そのため、簡単に作れるAthena+QuickSight+S3の構成が重宝します。
Amazon Athena for Advance
パーティショニングの活用
大規模なデータセットに対しては、データのパーティショニングを活用することが重要です。
パーティショニングにより、データを効率的に分割し、クエリの実行速度を向上させることができます。
特に日付や地域などのキーでパーティショニングすることが効果的です。
AWS Glue Data Catalogの統合
AthenaはAWS Glue Data Catalogと統合されており、データのメタデータ管理が簡単になっています。
Glue Data Catalogを使用することで、Athenaからデータの検索やクエリをスムーズに行うことができます。
Prestoクエリエンジンの最適化
AthenaはPrestoクエリエンジンをベースにしており、複雑なクエリの最適化や効率的な実行が可能です。
Prestoのクエリ言語に慣れることで、より高度なクエリを作成できます。
Amazon Athenaのベストプラクティス
最後にAmazon Athenaを利用する際のベストプラクティスをまとめました。
| ベストプラクティス | 詳細 |
|---|---|
| パーティショニングの活用 | 日付やカテゴリなどでデータを適切にパーティション分割する。 |
| 圧縮とフォーマット | ソースデータを圧縮し、データ形式はParquetやORC形式を選択する。 |
| キャッシュの活用 | クエリ結果をキャッシュし、同じクエリの高速な実行を実現する。 |
| クエリの最適化 | 実行計画を検討し、パフォーマンスのボトルネックを最適化する。 |
Amazon Athenaはサーバレスなクエリサービスですが、性能を引き出しつつコストを下げるために考えるべきポイントは一般的なクエリサービスと同じです。
データセットの特徴にもよりますが、実プロジェクトの感覚では圧縮とフォーマットがコストと性能の最適化につながります。
元のデータがParquetやORCなどカラムナ形式ではない場合、Glueなどを用いて変換したうえでS3などに保存するとよいでしょう。
まとめ
この記事ではAmazon Athenaに関連する内容を超詳細にまとめました。
- Amazon Athenaとは
- Amazon Athenaの活用
- Amazon Athena for Advance
- Amazon Athenaのベストプラクティス
次回からはインシデントとイベントへの対応を説明します。