要約
-
torchsummaryが進化したtorchsummaryXが登場。 - DataFrame型で表示されるようになり、かなり見やすく。
-
torch.*.LongTensor型に対応(個人的にかなり嬉しいポイント)。
torchsummaryとは
- https://github.com/sksq96/pytorch-summary
- ニューラルネットの入出力のサイズを確認できる。
- 以下の記事がわかりやすいです。
Pytorchでモデル構築するとき、torchsummaryがマジ使える件について
torchsummaryXとは
- https://github.com/nmhkahn/torchsummaryX
-
torchsummaryの進化版
インストール
いつも通りpipで
pip install torchsummaryX
使い方
公式GitHubより引用
.py
from torchsummaryX import summary
summary(your_model, torch.zeros((1, 3, 224, 224)))
実際にやってみるとこんな感じ(公式GitHubより引用)
.py
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
summary(Net(), torch.zeros((1, 1, 28, 28)))
表示結果は以下の通り。
=================================================================
Kernel Shape Output Shape Params Mult-Adds
Layer
0_conv1 [1, 10, 5, 5] [1, 10, 24, 24] 260.0 144.0k
1_conv2 [10, 20, 5, 5] [1, 20, 8, 8] 5.02k 320.0k
2_conv2_drop - [1, 20, 8, 8] - -
3_fc1 [320, 50] [1, 50] 16.05k 16.0k
4_fc2 [50, 10] [1, 10] 510.0 500.0
-----------------------------------------------------------------
Totals
Total params 21.84k
Trainable params 21.84k
Non-trainable params 0.0
Mult-Adds 480.5k
=================================================================
-
Kernel Shape: パラメータのシェイプ -
Output Shape: アウトプットのシェイプ -
Params: パラメータの数 -
Mult-Adds: 積和演算(2020/08/01編集。ご指摘ありがとうございます)
torchsummayと違うところ
1. 結果がDataFrame型でも表示
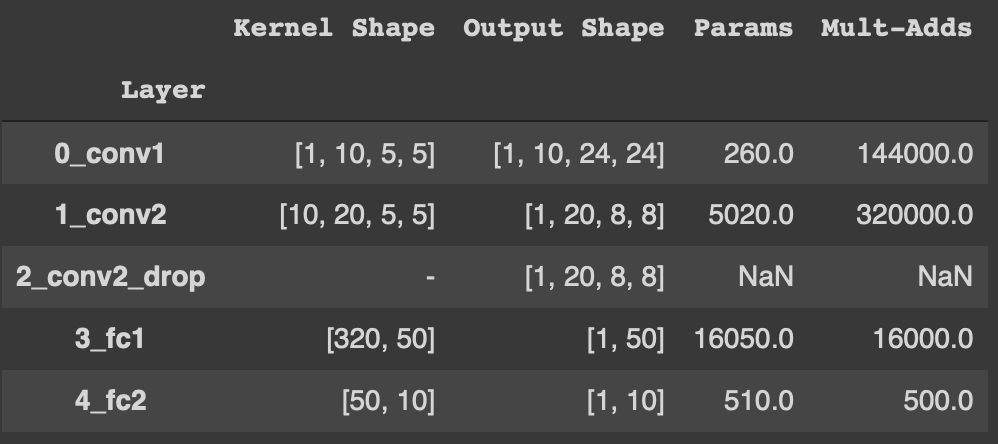
やはりDataFrame型は見やすいですね。
2. torch.*.LongTensor型に対応
個人的にかなり嬉しいポイントです。従来のtorchsummaryは入力としてtorch.*.FloatTensor型にしか対応していませんでした。そのため、入力としてtorch.*.LongTensor型を受け取る言語処理のモデルなどに対してはtorchsummaryは使えませんでした。
.py
from transformers import BertModel
from torchsummary import summary
model = BertModel.from_pretrained('bert-base-uncased')
summary(model, input_size=(1, 512))
# RuntimeError: Expected tensor for argument #1 'indices' to have scalar type Long; but got torch.FloatTensor instead (while checking arguments for embedding)
ですが、torchsummaryXではtorch.*.LongTensor型にも対応しています。
.py
from transformers import BertModel
from torchsummaryX import summary
model = BertModel.from_pretrained('bert-base-uncased')
summary(model, torch.zeros((1, 512), dtype=torch.long))
==================================================================================================================
Kernel Shape \
Layer
0_embeddings.Embedding_word_embeddings [768, 30522]
1_embeddings.Embedding_position_embeddings [768, 512]
2_embeddings.Embedding_token_type_embeddings [768, 2]
3_embeddings.LayerNorm_LayerNorm [768]
4_embeddings.Dropout_dropout -
(省略)
これで言語処理系のモデルに対しても使えるようになりました!(他の列は下に表示されています)
3. 一部モデルの表示が見やすく
従来のtorchsummaryでは一部モデルは綺麗に表示されませんでした。(サンプルはEfficientNet PyTorchから)
.py
from efficientnet_pytorch import EfficientNet
from torchsummary import summary
model = EfficientNet.from_pretrained('efficientnet-b0')
summary(model, input_size=(3,224,224))
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
ZeroPad2d-1 [-1, 3, 225, 225] 0
Conv2dStaticSamePadding-2 [-1, 32, 112, 112] 864
BatchNorm2d-3 [-1, 32, 112, 112] 64
MemoryEfficientSwish-4 [-1, 32, 112, 112] 0
ZeroPad2d-5 [-1, 32, 114, 114] 0
(省略)
torchsummaryXならばこの通りです。
.py
from efficientnet_pytorch import EfficientNet
from torchsummaryX import summary
model = EfficientNet.from_pretrained('efficientnet-b0')
summary(model, torch.zeros(1,3,224,224))
(省略)
Output Shape Params \
Layer
0__conv_stem.ZeroPad2d_static_padding [1, 3, 225, 225] -
1__bn0 [1, 32, 112, 112] 64.0
2__swish [1, 32, 112, 112] -
3__blocks.0._depthwise_conv.ZeroPad2d_static_pa... [1, 32, 114, 114] -
4__blocks.0.BatchNorm2d__bn1 [1, 32, 112, 112] 64.0
5__blocks.0.MemoryEfficientSwish__swish [1, 32, 112, 112] -
(省略)
もちろんDataFrame型でも確認できます。
結論
特に言語処理のモデルで使えるようになったことは大きなメリットです。他にもいろいろ改良されているようなので、気になった方は是非試してみてください!