Amazon DataZone で公開しているデータカタログを、SageMaker Studio からサブスクライブして、SageMaker Canvas にインポートする流れを試してみました。(備忘録メモとしての記事となります。)
Amazon DataZoneとは
Amazon DataZoneは、AWS、オンプレミス、サードパーティのソースに保存されたデータをカタログ化、検索、共有、管理するためのデータ管理サービスです。
Amazon DataZoneを使用して、組織間のデータアクセスを管理できます。
データのパブリッシュとサブスクライブのワークフローを提供しているので、これにより、データプロデューサーはアセットを、ドメイン内にデータカタログとして公開できます。
そして、データコンシューマーは、サブスクライプフローを通したアクセス制御メカニズムによって、カタログにあるデータへアクセスできるようになります。
Amazon DataZone では、さまざまなデータへのアクセス制御を一元化できるため、誰がどのデータをどのような目的で使用しているかを容易に確認することができます。
それではさっそく Amazon DataZone を通して SageMaker にデータをインポートしていく本題に入ります。
ざっくりな作業フローとしては下記となります。

1. データプロデューサープロジェクトで Amazon DataZone ポータル内にデータを公開する。
2. データコンシューマープロジェクトで、SageMaker 用の環境を作成する。
3. 作成した SageMaker 環境から、SageMaker Studio に遷移して、対象データをサブスクライブする。
4. サブスクライブ申請をプロデューサー側で承認する。
5. SageMaker Canvas で対象のデータをインポートする。
※Canvas にインポートしたデータを使って、モデルを作成する作業まではこの記事に含めておりません。
なお、この検証では AWS コンソールとして、同一アカウントでプロデューサープロジェクトと、コンシューマープロジェクトをつかいわけます。DataZone ポータルでは左上のプロジェクト名で区別できます。
準備:プロデューサーのプロジェクト作成とデータカタログ整備
いきなりですが、本題でない準備作業を、他者の力をお借りして、進めたいと思います。
AWS 社が公開しているハンズオンのメインパートの 1-4 を実施します。
4章については Cloud Formation テンプレートをそのまま実行することで、Order の Glue データカタログができた状態となります。
[第1章]

[第2章]

[第3章]

[第4章]

1. プロデューサープロジェクトでデータを公開していきます。
まずデータソースを作成します。


次の画面の詳細設定やスケジュールなどはそのまま「次へ」を押して、作成完了まで進ます。
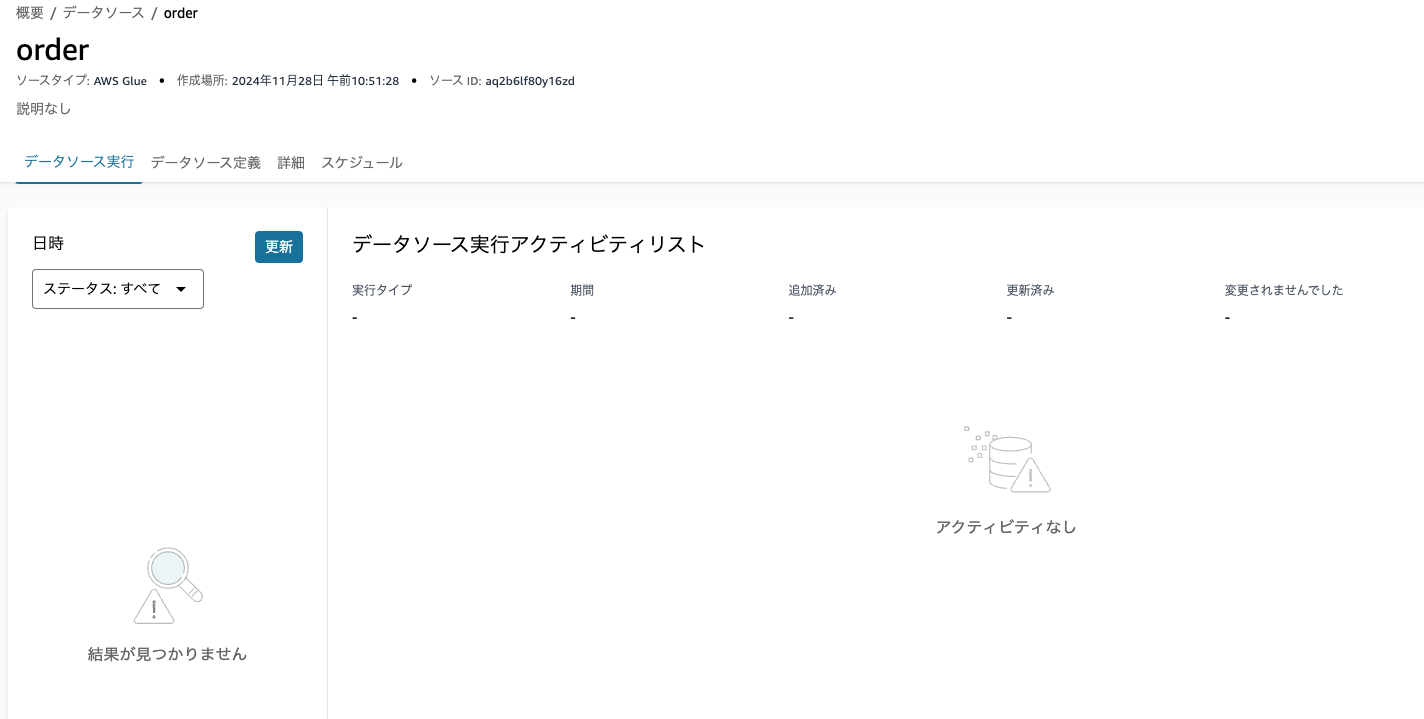
右上の「実行」ボタンを押して、アセットを取り込みます。
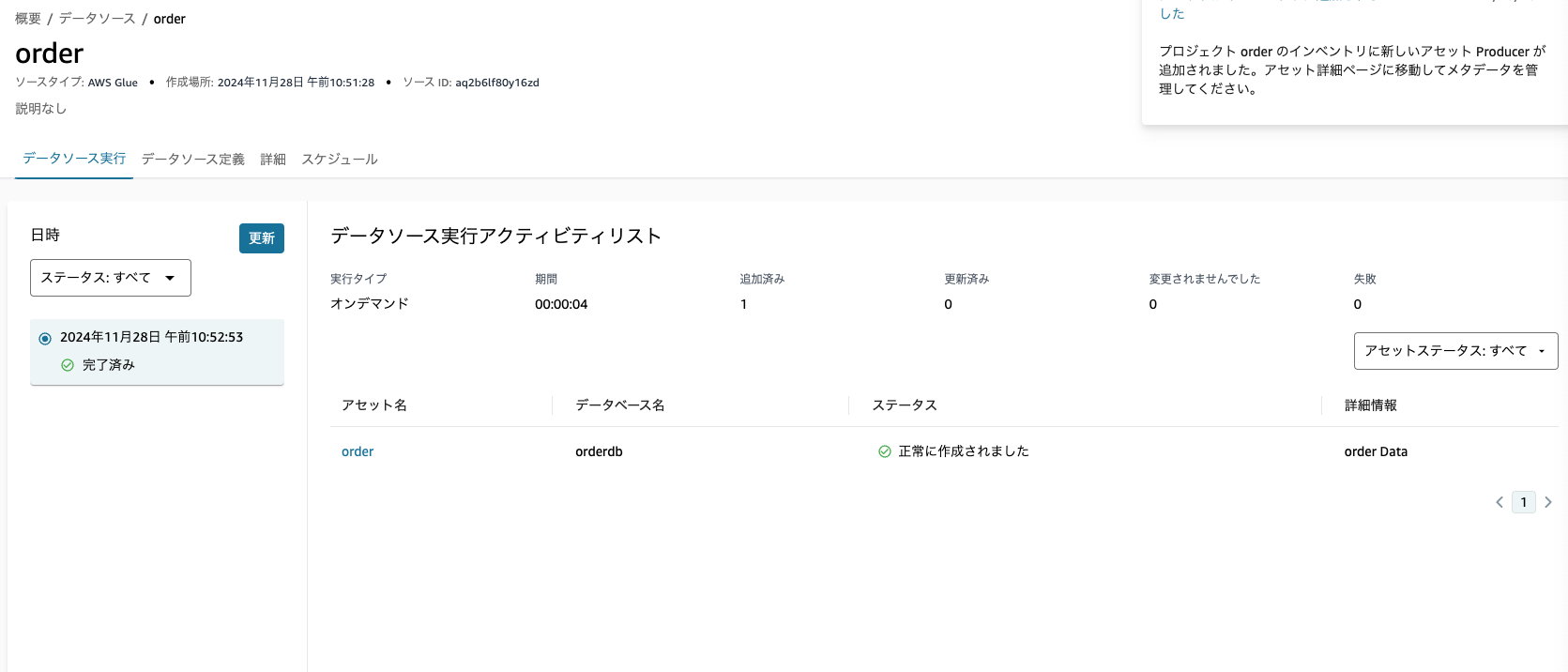
インベントリデータのアセットに「order」ができているので詳細を確認します。

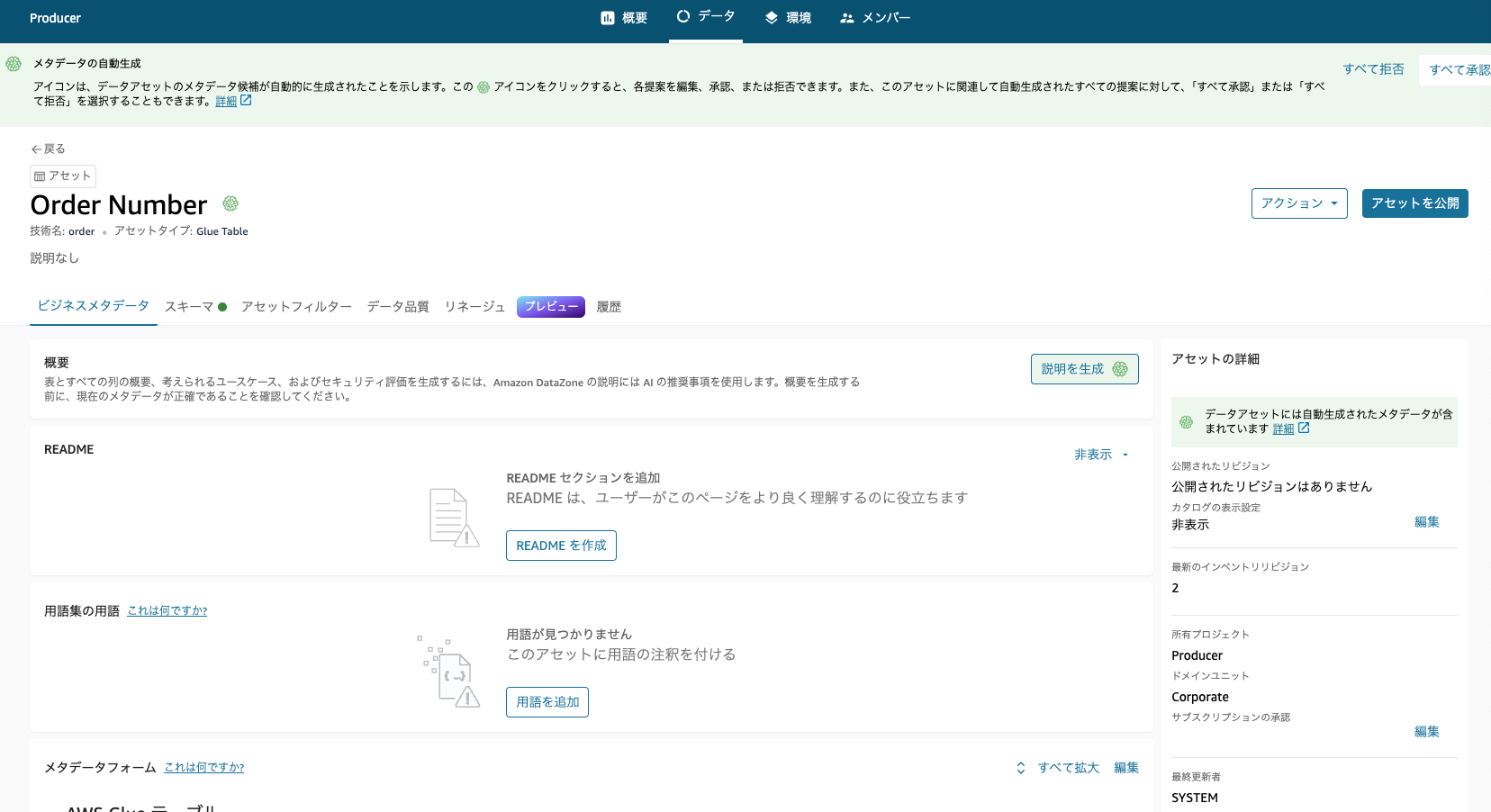
AIのメタデータ自動生成などもでてきますが、今回は無視して、右上の「アセットを公開」を押して、データ公開を進めます。

2. コンシューマープロジェクトと環境を作成していきます。
左上のプロジェクト作成操作より、「Consumer」プロジェクトを作成します。

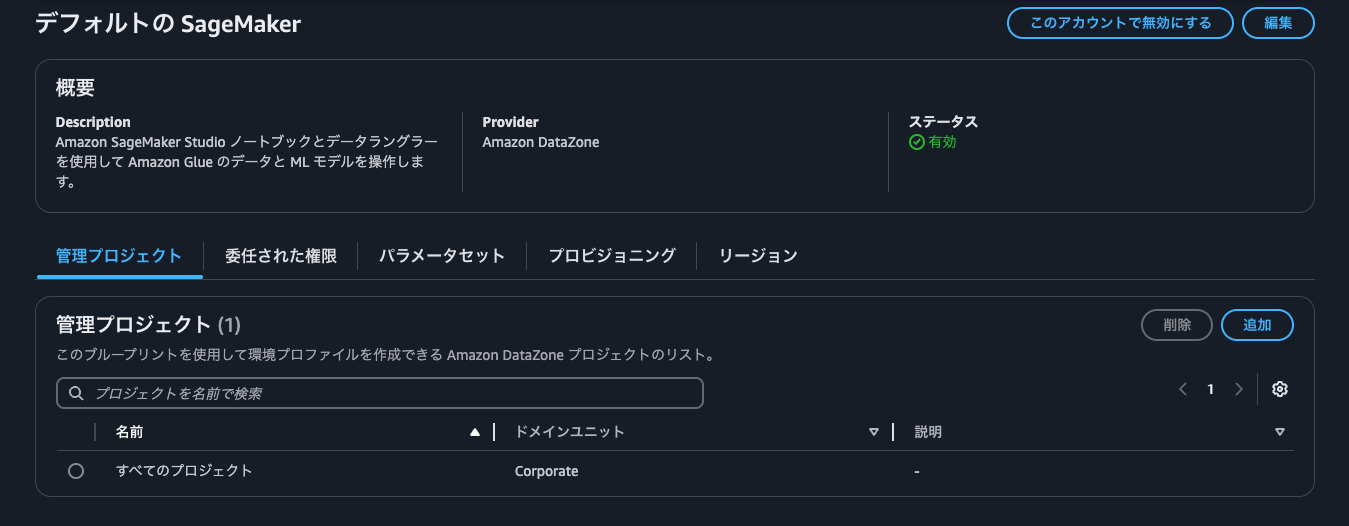
ここからコンシュマープロジェクトを作成していくのですが、そもそもの DataZone ドメインで SageMaker のブループリントを有効にする必要があります。AWS コンソールのドメイン詳細画面のブループリントタブから操作を行います。
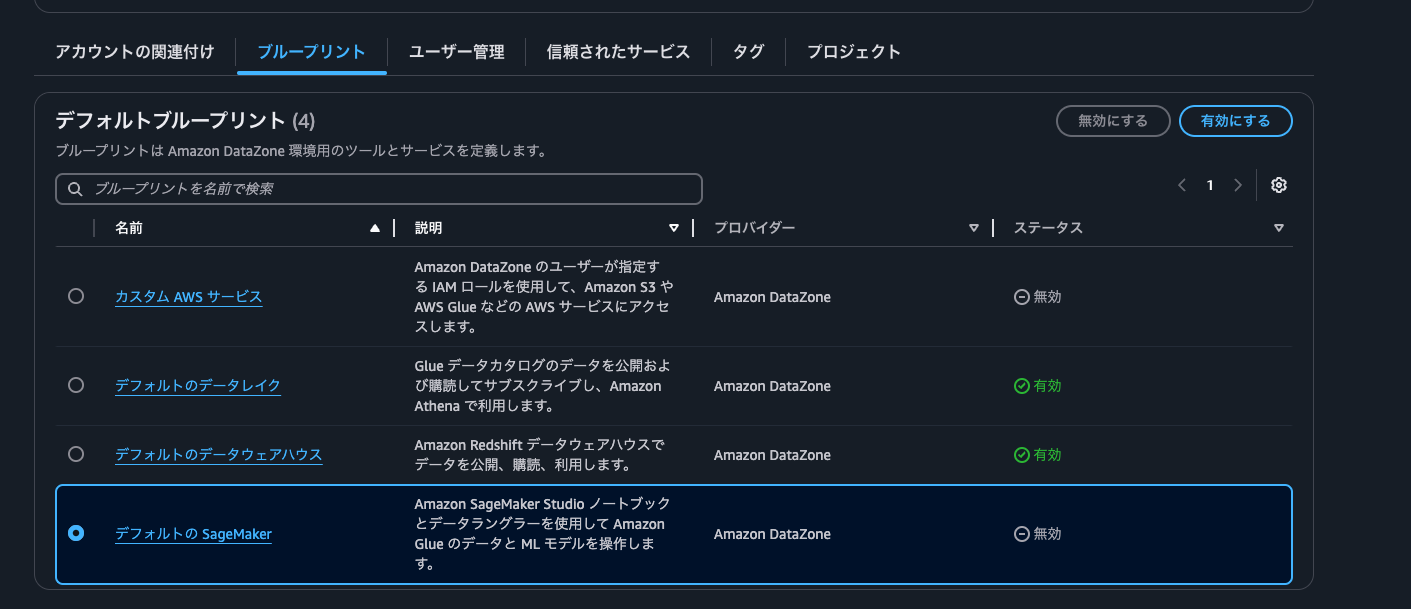
ブループリントの設定として、今回は必要なロールなど新規で作成するようにそのまま、「ブループリントを有効にする」ボタンを押します。
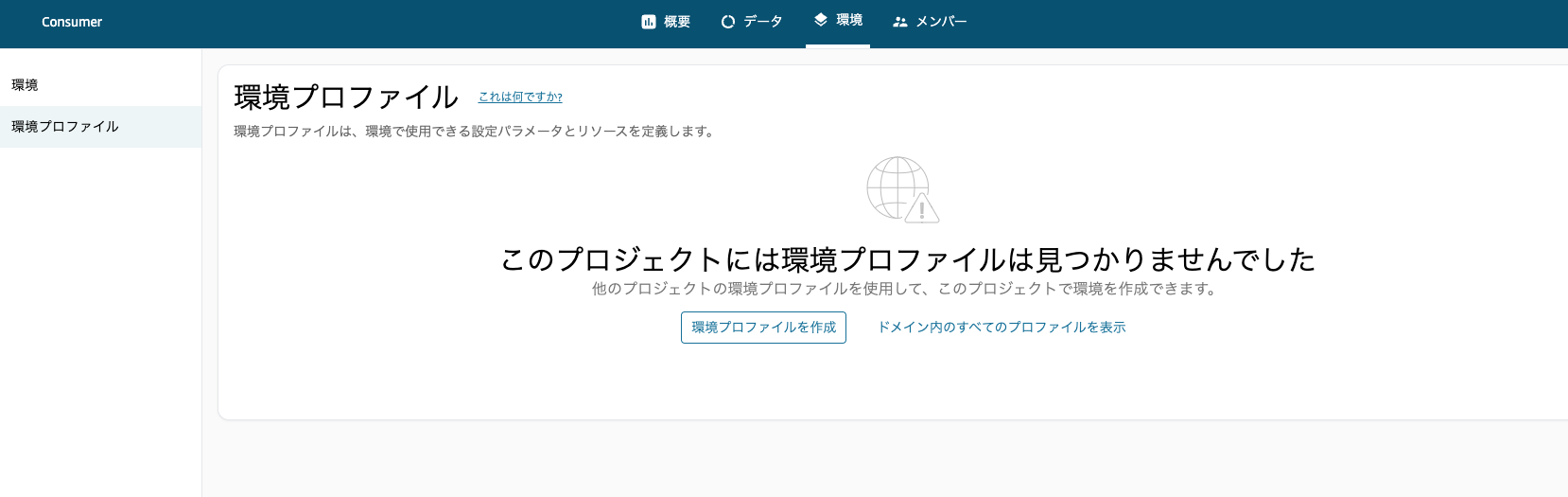
次に、DataZone ポータルに戻り、コンシュマープロジェクトで環境プロファイルを作成します。
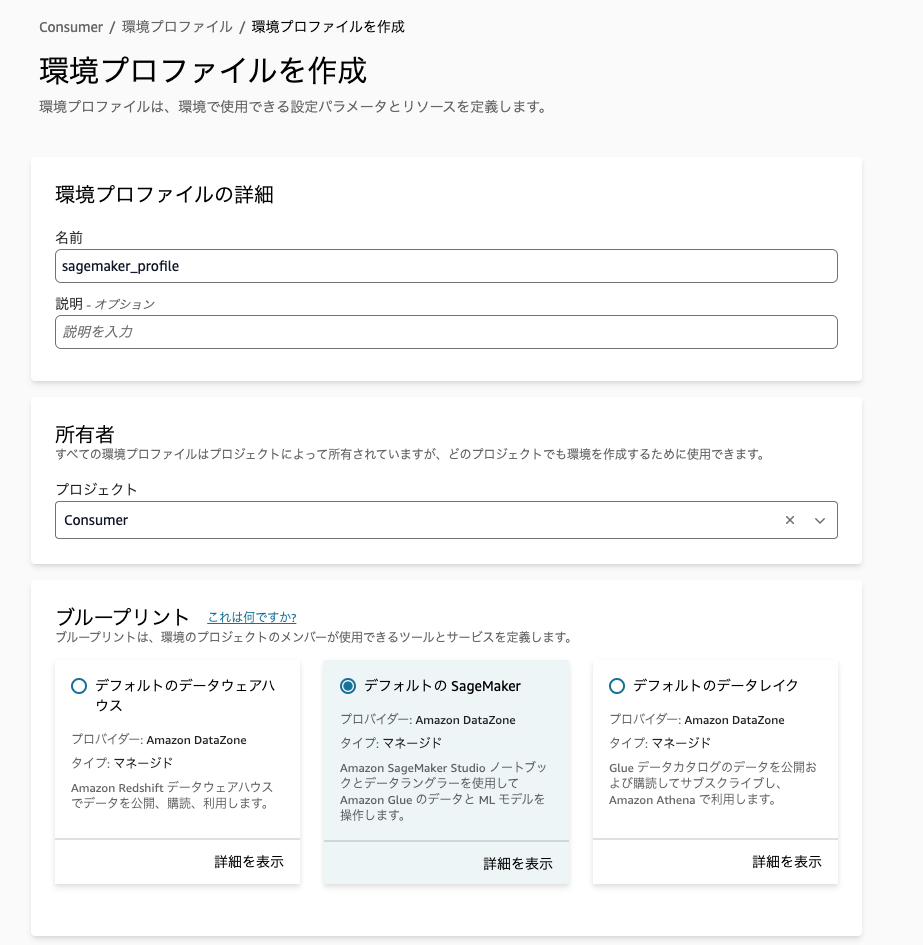
ブループリントで有効化した SageMaker を選択します。
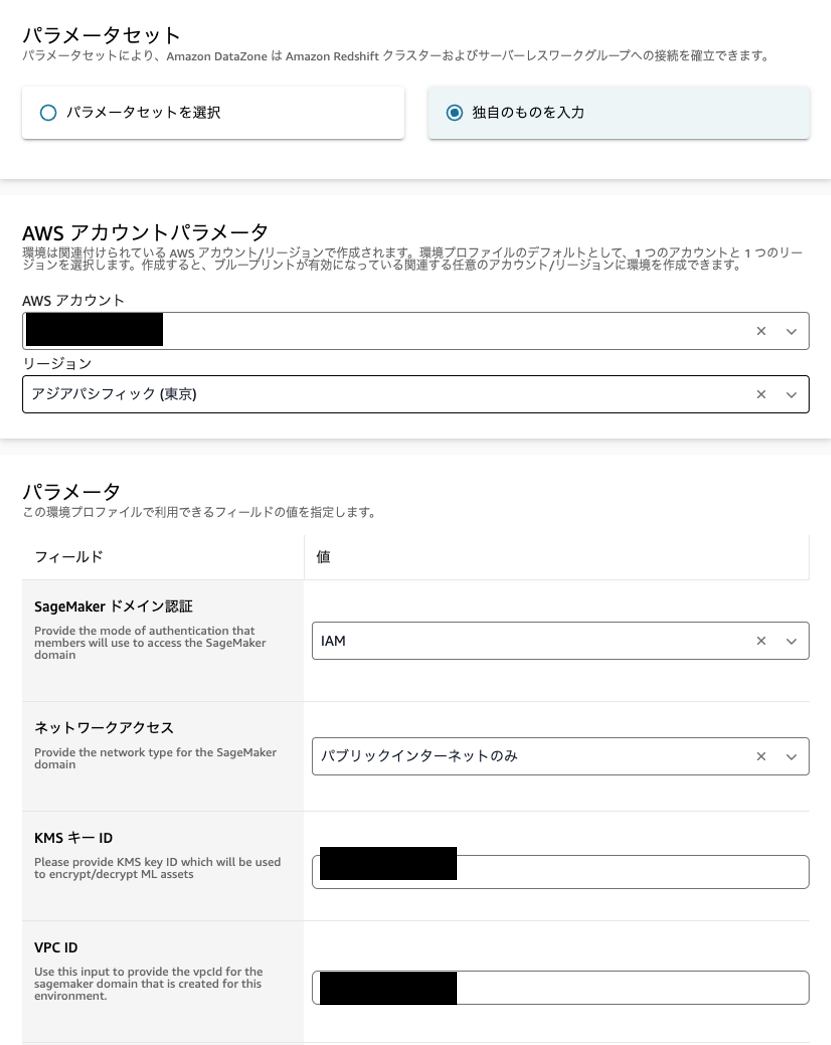
パラメータは今回独自のものを入力しました。
AWSアカウント、リージョンを自身のものを選びます。次のパラメータとして「IAM」認証、「パブリックインターネットのみ」、そしてKMSキー、VPC、サブネットを適切なものを入力します。
(SageMaker ドメインを新たに作成して、それに紐づくKMSキーやVPCの設定を踏襲するのがわかりやすいかもしれないです。)
その他の設定はそのまま、「環境プロファイルを作成」を押します。

次に作成された環境プロファイルを使って環境を作成します。

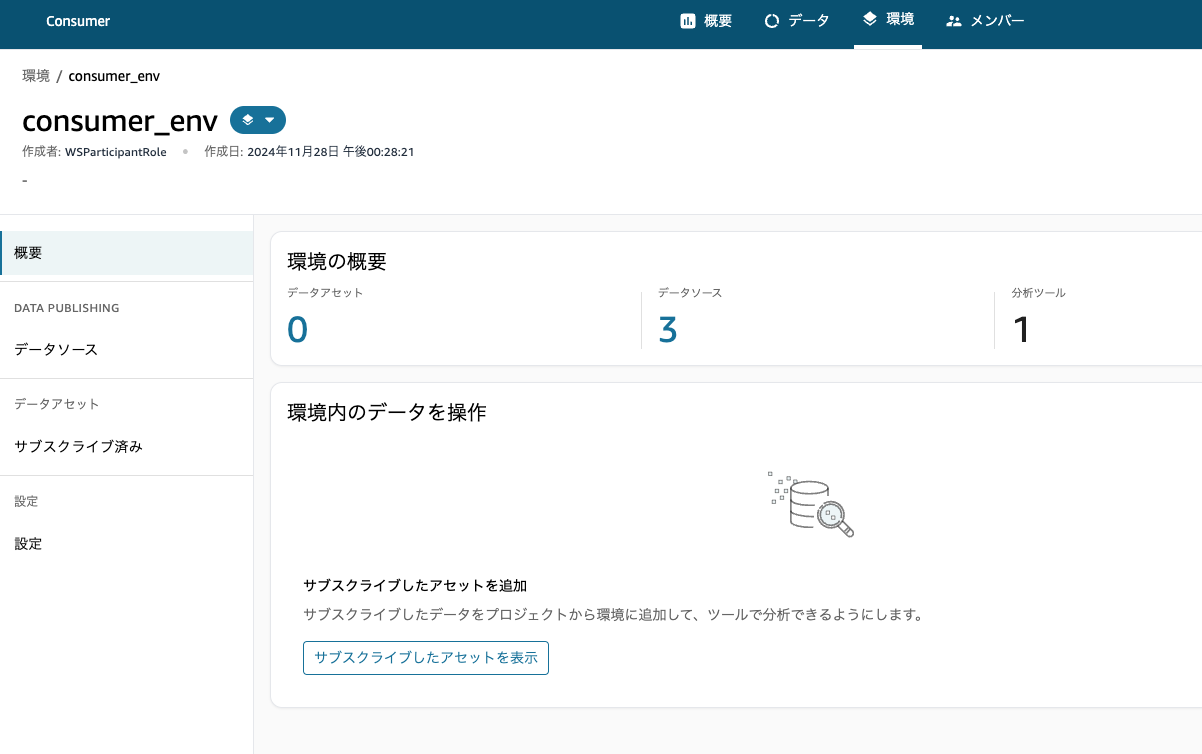
3. SageMaker Studio からデータのサブスクライブ
コンシューマーで作成した環境のディープリンクから、SageMaker Studio へ遷移します。


左の 「Assets」メニューから「Asset catalog」タブへと選択していくと、公開されているデータの「order」が確認できます。

「order」アセットをクリックして、データのスキーマ等を確認したら、右上の「Subscribe」を押します。
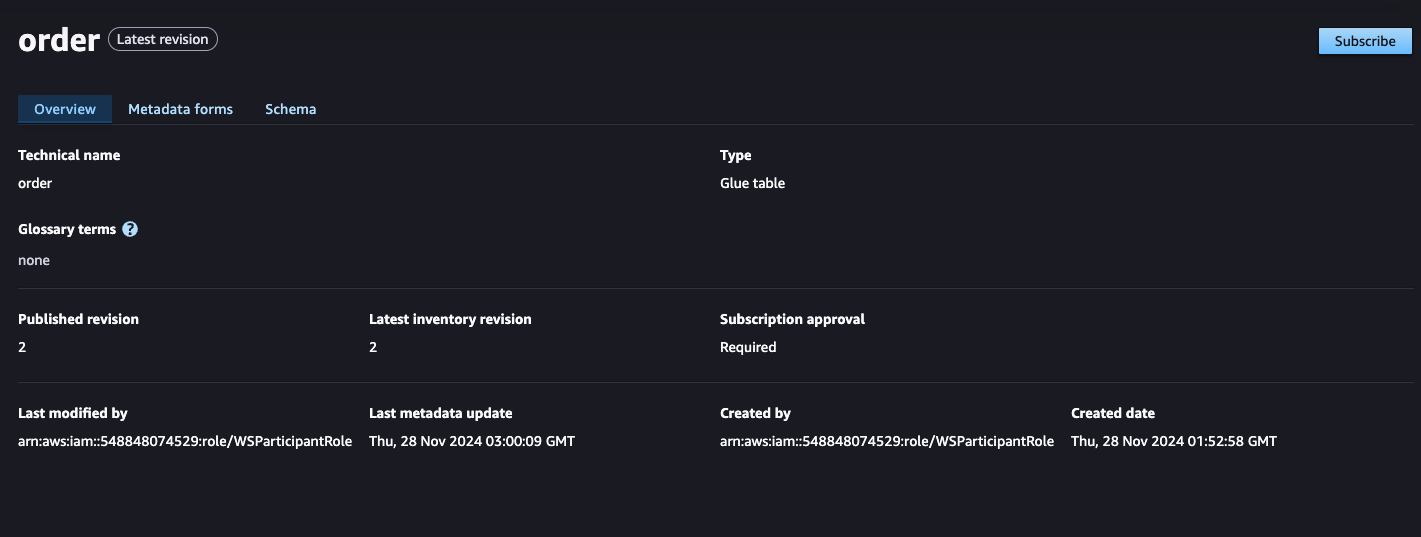
申請理由を記載して、「Submit」を押します。

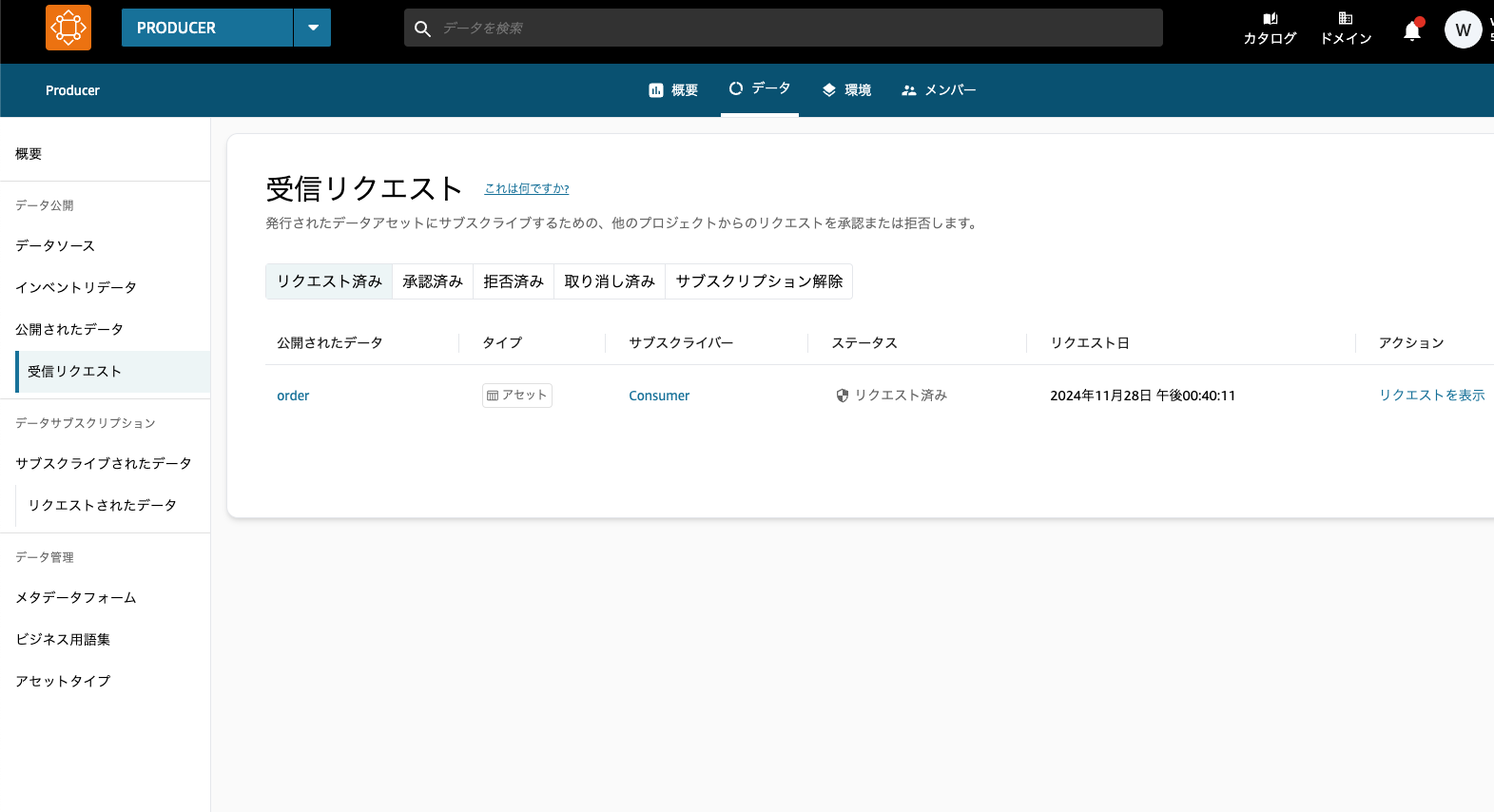
4. プロデューサープロジェクトでサブスクライブ申請を承認
プロデューサープロジェクトのデータの受信リクエストメニューを見ると、コンシューマーからのリクエストが確認できます。
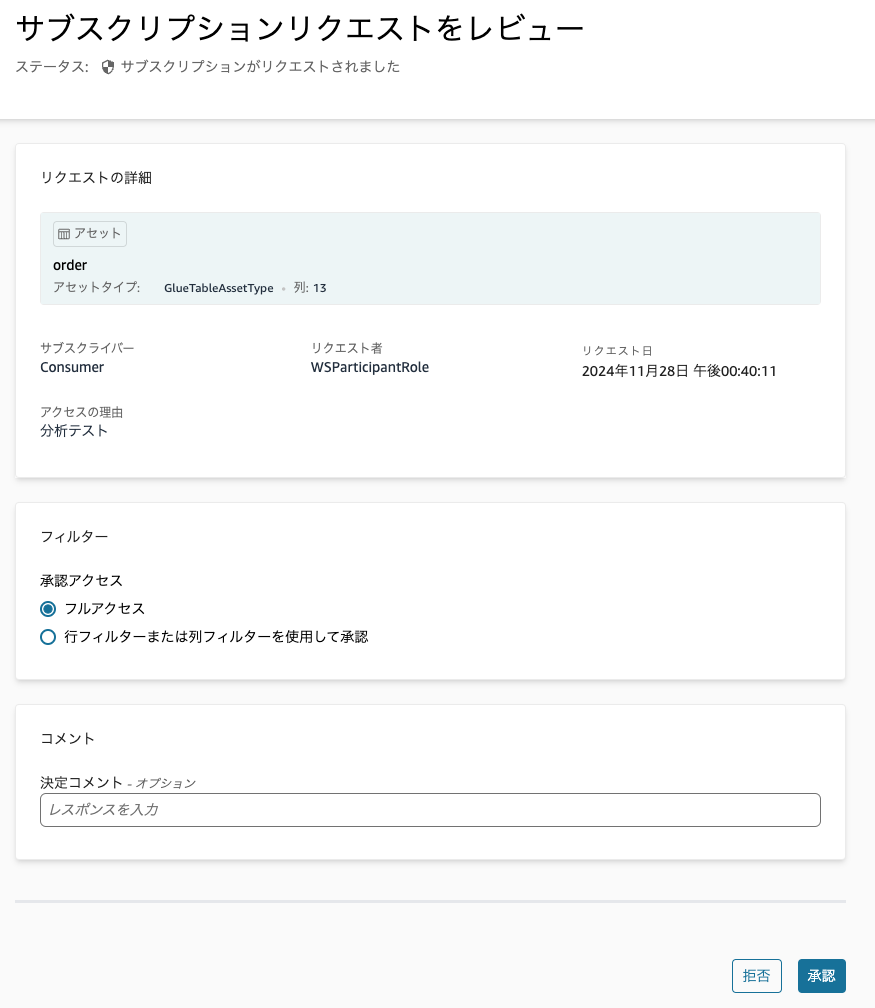
リクエストを表示して、フルアクセスとして承認します。
もう1度、コンシューマー側の SageMaker Studio のアセットを見てみると、「Subscribed assets」に「order」が表示されているを確認できました。
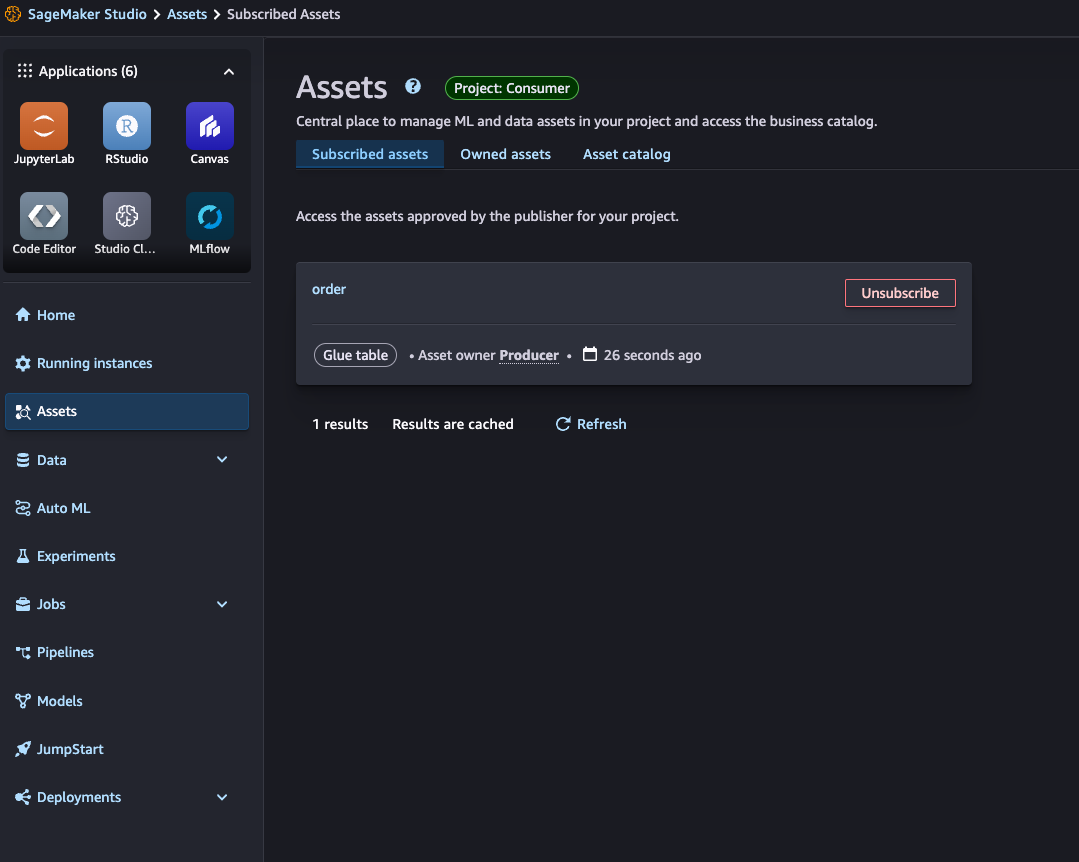
ちなみに DataZone ポータルでも同様にコンシューマープロジェクトのサブスクライブされたデータとして表示されます。

5. サブスクライブしたデータの Canvas インポート
引き続き、SageMaker Studio の画面左上から、「Canvas」を選択し、起動させます。
Canvas が起動完了したら、Canvasを開きます。

左のメニューから「Data Wrangler」を選択します。中央の「Import and prepare」ボタンを押下し、「Tabular」を選択します。
データソースに「Athena」を選択すると、「AwsDataCatalog」- 「consumer_env_sub_db」配下に、サブスクライブした「order」のデータが確認できます。

「order」データをドラッグ&ドロップすると、preview としてインポート対象のデータが確認できます。問題なければ、右下の「Import」ボタンを押します。
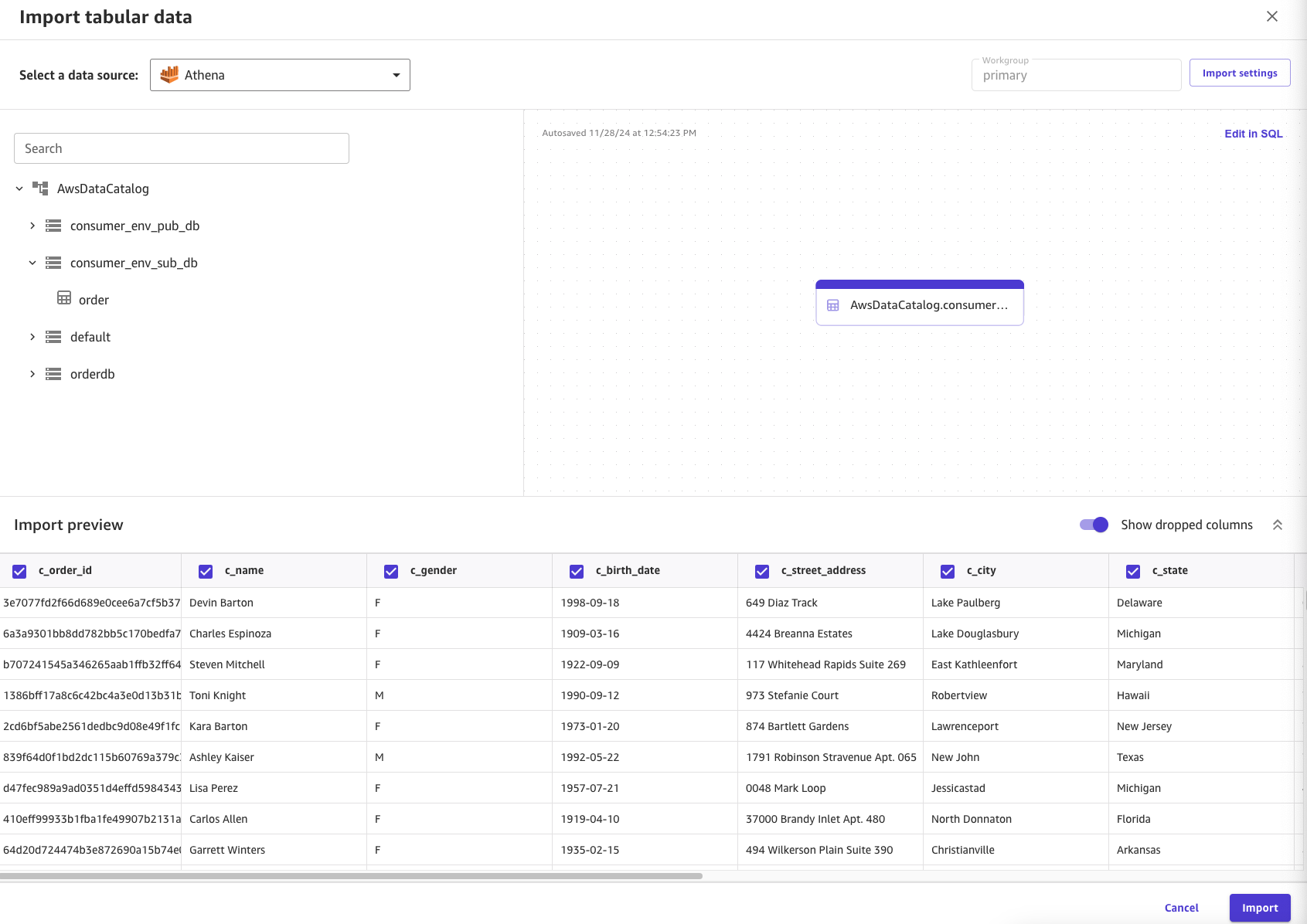
インポートが完了です。

これにより DataZone でサブスクライブしたデータを、SageMaker Canvas 内にインポートできたので、続く分析とモデル作成に利用することができます。
また作成したモデルを Model Registry に格納し、SageMaker Studio から公開することで、DataZone ポータルで検索可能となります。(ただし、2024年12月現在、モデル自体を DataZone のマネージドアセット対象とする術がないため、サブスクライブしてもモデルにアクセスさせる運用を自身で考える必要がある点は注意です。)
まとめ
今回、Amzon DataZone で公開されたデータをサブスクライブして、SageMaker Canvas でモデル作成するためにインポートするという流れを試してみました。今後 DataZone を試されるどなたかのヒントになれば幸いです。