はじめに
EfficientNetをファインチューニングするコードをPyTorch Lightningで実装しました。
画像分類モデルを作成する際の初手として使用することを想定し、ある程度使い回しが効くように実装したつもりですので、ちょっと長いですが最後まで目を通して頂けますと幸いです。
なお、Google Colaboratoryで実行できるnotebookもgitで公開しているので、間違っている点などあれば是非ご指摘いただけますと幸いです。
pytorch_lightning_image_classification.ipynb
Efficient-Netとは
2019年当時SoTAを達成した画像認識モデルです。転移学習にも適しているということで、今回はEfficientNetのファインチューニングを行います。
【参考記事】
2019年最強の画像認識モデルEfficientNet解説
PyTorch Lightningとは
Pytorchだと頻出しがちな.to(device)がloss.backward()などの定型的な処理やfor文無しでのコーディングが可能となるフレームワークです。また、EarlyStoppingが簡単に実装できる点も個人的には大きなメリットです。
【参考記事】
PyTorch 三国志(Ignite・Catalyst・Lightning)
PyTorch Lightning 2021 (for MLコンペ)
環境
Google Colaboratory
使用するデータ
pytorchのチュートリアルでも使用されているアリとハチのデータセットを使って分類モデルを作成します。
import os
import urllib.request
import zipfile
url = "https://download.pytorch.org/tutorial/hymenoptera_data.zip"
save_path = "hymenoptera_data.zip"
if not os.path.exists(save_path):
urllib.request.urlretrieve(url, save_path)
zip = zipfile.ZipFile(save_path)
zip.extractall()
zip.close()
os.remove(save_path)
事前準備
事前準備として各種インストール、インポートを行います。pytorch-lightningはバージョンによって挙動や引数が結構変わるので、バージョンを指定します。
# 各種インストール(captureはpipの過程を非表示にするため)
%%capture
!pip install pytorch-lightning==1.4.9
!pip install timm
# インポート
import glob
import random
import pickle
import numpy as np
import pandas as pd
import pytorch_lightning as pl
import timm
import torch
import torch.nn as nn
import torch.optim as optim
from PIL import Image
from pytorch_lightning.callbacks import EarlyStopping, ModelCheckpoint
from sklearn.model_selection import train_test_split
from torch.utils.data import DataLoader, Dataset
from torchvision import transforms
seedの固定も行います。
# seedの固定
def fix_seed(seed):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
SEED = 0
fix_seed(SEED)
実装の流れ
ここからが本格的な実装となりますが、大まかな流れは下記の通りとなります。
-
LightningDataModuleでモデルに使用するデータ周りを定義
-
LightningModuleでモデル構造と各Phase(train/valid/test)の挙動を定義 -
Trainerで学習時の各種設定を定義(Epoch数やEarly Stoppingなど) - 学習の実行、精度検証、モデルの保存
1. LightningDataModuleでモデルに使用するデータ周りを定義
自作Datasetの定義
DataModuleを作成する前段階として、自作Datasetのclassを定義します。transformはtrainとvalid/testで異なるためここでは定義せず(trainはaugmentationを実施)、引数として持たせておきます。なお、ラベリング部分は他のデータを使用するときは適宜変更が必要となります。
class MyDataset(Dataset):
def __init__(self, file_list, transform=None):
self.file_list = file_list
self.transform = transform
def __len__(self):
return len(self.file_list)
def __getitem__(self, index):
# 画像を読みこんで、指定の方法でtransform
img_path = self.file_list[index]
img = Image.open(img_path)
img_transformed = self.transform(img)
# pathに含まれる文字を使用してラベリングを実施
if 'ants' in img_path:
label = 0
else:
label = 1
return img_transformed, label
LightningDataModuleの定義
続いて、LightningDataModuleを継承してDataModuleを作成するためのclassを定義します。
train/valid/testの画像pathリストが引数となっており、fit、testそれぞれのフェーズに応じて必要なDataset、DataLoaderが作成されます。先ほどの自作Datasetを定義した際に後回しにしていたtransformの方法については__init__で定義してます。
class CreateDataModule(pl.LightningDataModule):
def __init__(self, train_path, val_path, test_path, img_size=224,
mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225),
batch_size=16):
super().__init__()
self.train_path = train_path
self.val_path = val_path
self.test_path = test_path
self.batch_size = batch_size
# train時、val/test時の前処理をそれぞれ定義
self.train_transforms = transforms.Compose([
transforms.RandomResizedCrop(img_size, scale=(0.5, 1.0)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean, std)
])
self.val_test_transforms = transforms.Compose([
transforms.Resize(img_size),
transforms.CenterCrop(img_size),
transforms.ToTensor(),
transforms.Normalize(mean, std)
])
# データのダウンロードなどを行う場合は定義、今回は不要
def prepare_data(self):
pass
# Trainer.fit()ではtrain/valのDatasetを、Trainer.test()ではtestのDatasetを生成
def setup(self, stage=None):
if stage == 'fit' or stage is None:
self.train_dataset = MyDataset(self.train_path, self.train_transforms)
self.val_dataset = MyDataset(self.val_path, self.val_test_transforms)
if stage == 'test' or stage is None:
self.test_dataset = MyDataset(self.test_path, self.val_test_transforms)
# こちらもTrainer.fit()ではtrain/valのDataLoaderを、Trainer.test()ではtestのDataLoaderを生成
# trainはshuffleあり、val/testはshuffleなし
def train_dataloader(self):
return DataLoader(self.train_dataset, batch_size=self.batch_size, shuffle=True)
def val_dataloader(self):
return DataLoader(self.val_dataset, batch_size=self.batch_size)
def test_dataloader(self):
return DataLoader(self.test_dataset, batch_size=self.batch_size)
DataModuleのインスタンスを作成
定義してきたclassを使用してインスタンスを作成します。
train/valid/testそれぞれの画像へのpathが引数となるため、最初にそれぞれのpathリストを作成し、引数として渡します。
# seedを固定
fix_seed(SEED)
# valフォルダはtestとして使用
test_path = [path for path in glob.glob("./hymenoptera_data/val/*/*.jpg")]
# trainフォルダの画像を7:3でtrain:validに分割
modeling_path = [path for path in glob.glob("./hymenoptera_data/train/*/*.jpg")]
train_path, val_path = train_test_split(modeling_path, train_size=0.7)
# インスタンスを作成
data_module = CreateDataModule(train_path,val_path,test_path)
2. LightningModuleでモデル構造と各Phaseの挙動を定義
データの準備ができたら、LightningModuleを継承してモデルの定義を行います。
モデル構造の定義
__init__、forwardを定義するところは普通にpytorchで実装する場合とほぼ変わりません。
今回はtimmを使用して学習済みモデルをダウンロードし、classifier部分を付替えることでファインチューニングを実施します。
各Phaseの挙動
def xx_stepで、training/validation/testの各フェーズごとにミニバッチの処理を定義します。関数名をフックに各フェーズで必要となる処理、例えばtraining時のmodel.train()やloss.backward()、validation時のmodel.valid()やtorch.no_grad()といった処理は内部的に行ってくれるため、記述は不要です。全フェーズで必要な.to(device)などの処理も内部的にやってくれます。
class ImageClassifier(pl.LightningModule):
def __init__(self, model_name, n_classes, lr=0.0001, criterion=torch.nn.CrossEntropyLoss()):
super().__init__()
self.save_hyperparameters()
# timmで学習済みモデルをダウンロードし、classifier部分を付替え
# n_classesにはラベルの件数を渡す(今回はアリとハチの2つなので2)
self.model = timm.create_model(model_name, pretrained=True)
self.model.classifier = nn.Linear(self.model.classifier.in_features, n_classes)
self.lr = lr
self.criterion = criterion
# 順伝搬
def forward(self, imgs, labels=None):
preds = self.model(imgs)
loss = 0
if labels is not None:
loss = self.criterion(preds, labels)
return loss, preds
# trainのミニバッチに対して行う処理
def training_step(self, batch, batch_idx):
imgs, labels = batch
loss, preds = self.forward(imgs=imgs, labels=labels)
return {'loss': loss, 'batch_preds': preds.detach(), 'batch_labels': labels.detach()}
# validation、testでもtrain_stepと同じ処理を行う
def validation_step(self, batch, batch_idx):
return self.training_step(batch, batch_idx)
def test_step(self, batch, batch_idx):
return self.training_step(batch, batch_idx)
# epoch終了時にvalidationのlossとaccuracyを記録
def validation_epoch_end(self, outputs, mode="val"):
# loss計算
epoch_preds = torch.cat([x['batch_preds'] for x in outputs])
epoch_labels = torch.cat([x['batch_labels'] for x in outputs])
epoch_loss = self.criterion(epoch_preds, epoch_labels)
self.log(f"{mode}_loss", epoch_loss, logger=True)
# accuracy計算
num_correct = (epoch_preds.argmax(dim=1) == epoch_labels).sum().item()
epoch_accuracy = num_correct / len(epoch_labels)
self.log(f"{mode}_accuracy", epoch_accuracy, logger=True)
def test_epoch_end(self, outputs):
return self.validation_epoch_end(outputs, "test")
def configure_optimizers(self):
optimizer = optim.AdamW(lr=self.lr, params=self.model.parameters())
scheduler = {'scheduler': optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.2)}
return [optimizer], [scheduler]
モデルインスタンスの作成
上記のクラスを使ってモデルインスタンスを作成します。なお、引数のmodel_nameは下記から選ぶことができます。
https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/efficientnet.py
また、今回はアリとハチという2種類の分類モデルとなるため、n_classesは2に設定します。
# モデルインスタンスの作成
model = ImageClassifier(model_name="efficientnet_b0", n_classes=2)
3. Trainerでtrain時の各種設定を定義
TrainerではEarlyStoppingやモデルの保存先、epoch数などを設定します。
# EarlyStoppingの設定
# 3epochで'val_loss'が0.05以上減少しなければ学習をストップ
early_stop_callback = EarlyStopping(
monitor='val_loss', min_delta=0.05, patience=3, mode='min')
# モデルの保存先
# epoch数に応じて、「epoch=0.ckpt」のような形で保存
checkpoint_callback = ModelCheckpoint(
filename='{epoch}', monitor='val_loss', mode='min', verbose=True)
# trainerの設定
trainer = pl.Trainer(max_epochs=20,
gpus=1,
callbacks=[checkpoint_callback, early_stop_callback],
log_every_n_steps=10)
4. 学習の実行、精度検証、モデルの保存
学習の実行
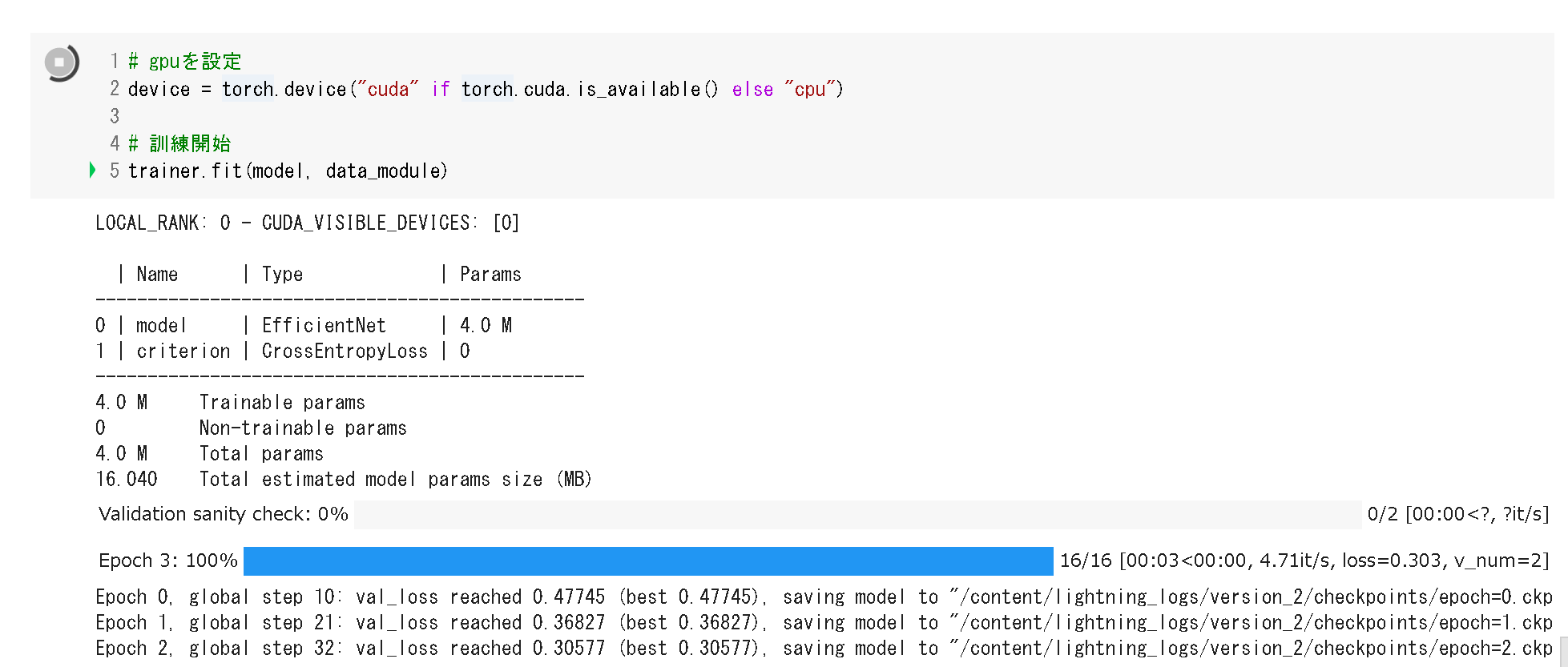
ここまでインスタンスを作成してきたdata_module、model、trainerを使用して学習を実行します。勝手にループしてくれるので、for文の記述は不要です。また、進捗も自動でいい感じに表示してくれます。
# gpuを設定
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 訓練開始
trainer.fit(model, data_module)
精度検証
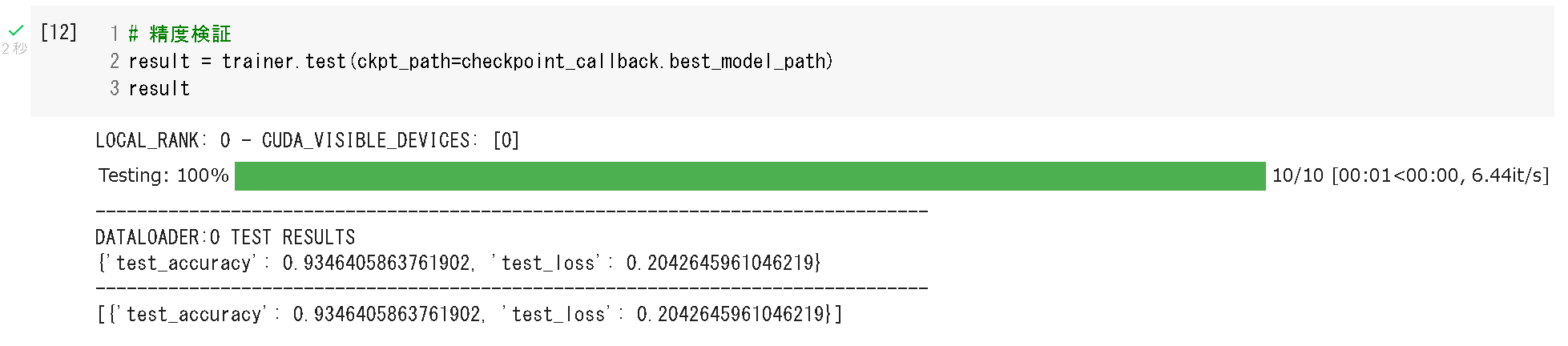
学習が終わったら。testデータでモデルの精度検証を行います。test_dataloaderはdata_moduleで定義済みなので、trainer.test()にてtestデータへの当てはめが可能です。今回は明示的に引数で最良時点のモデルを指定しました。
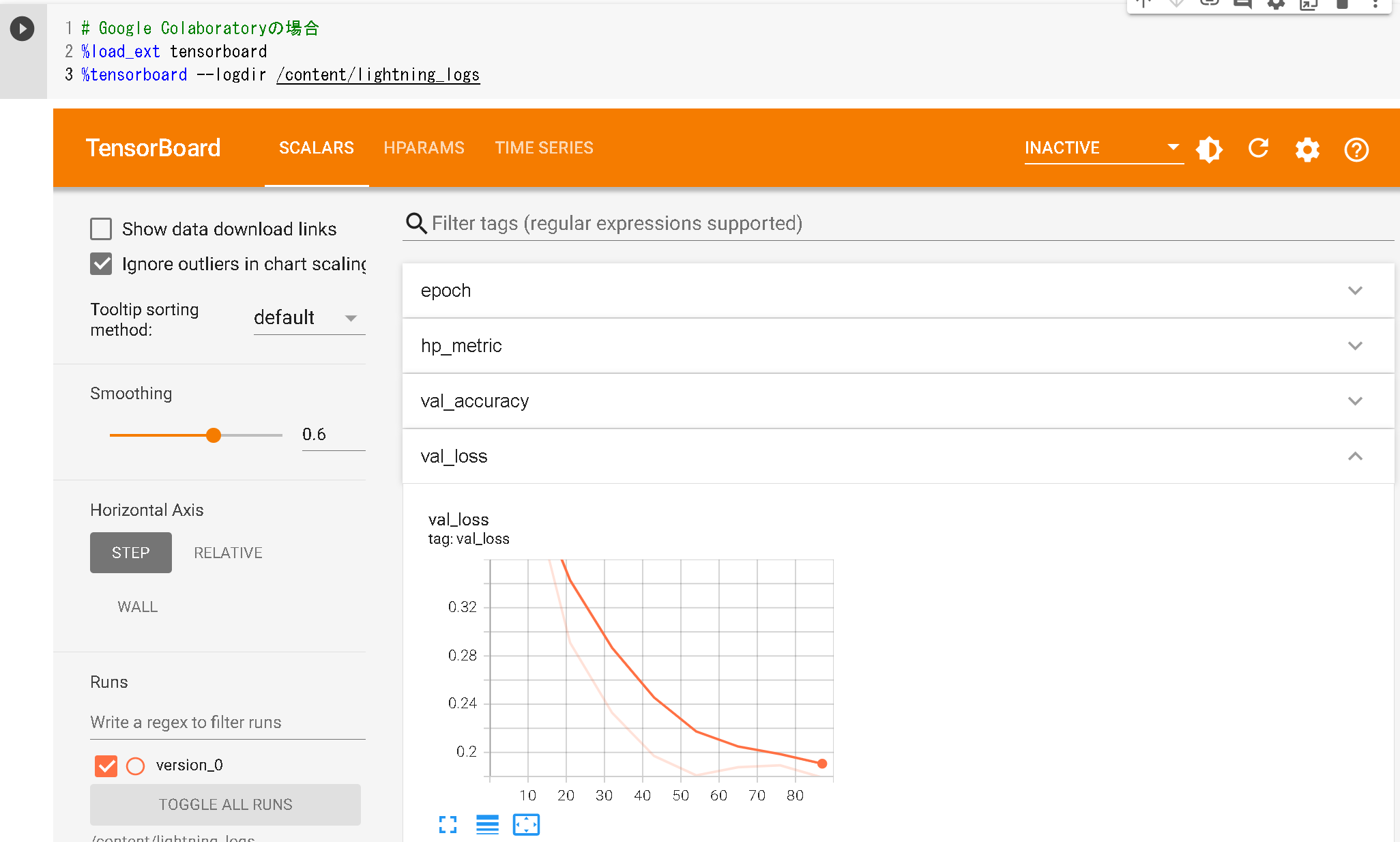
また、学習過程については、モデリング用クラス作成時にself.log()で定義したlossの動きをTensorBoardで確認可能です。
# 精度検証
result = trainer.test(ckpt_path=checkpoint_callback.best_model_path)
result
# tensorboardでの確認
%load_ext tensorboard
%tensorboard --logdir /content/lightning_logs
モデルの保存
最後に、モデルの保存を行います。
# 最良モデルの保存
best_model = ImageClassifier.load_from_checkpoint(checkpoint_callback.best_model_path)
with open('./best_model.pkl', mode='wb') as fp:
pickle.dump(best_model, fp)
参考
【PyTorch×転移学習】学習済みモデルライブラリTIMMのご紹介
関連記事
Pytorch Lightning関連で、過去にBERTの文章分類モデルの実装記事も公開していますので、ご興味のある方はこちらもご参照ください。
Pytorch Lightningを使用したBERT文書分類モデルの実装