【深層学習の実装備忘録】PyTorchを使ってCNN分類モデルを実装してみる
こんにちは!
この記事では、自分の復習も兼ねて、PyTorchの実装デモを紹介します。
今回は、MNISTデータを分類するCNNモデルを題材にします。
想定読者
- PyTorchを触り始めたばかりで、学習コード全体像を掴みたい人
-
Dataset/DataLoader/model.train()/model.eval()とかPyTorchで使う基本的なクラス・メソッドの意味を確認したい人
実行環境
- Google Colab(GPU)
- PyTorch / torchvision
ざっくりとした流れ
- MNIST前処理(Tensor化・正規化)
-
Datasetクラスの定義 -
DataLoaderクラスの準備 - CNNモデルの定義
- 学習・評価ループの実装
- 学習曲線の確認
- 新規推論の実施
0. 下準備
!pip -q install tqdm
### 必要ライブラリ
import os, random
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
from torchvision import datasets, transforms
from tqdm.auto import tqdm
import matplotlib.pyplot as plt
### 乱数固定
def set_seed(seed: int = 42):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
set_seed(42)
学習結果の再現性を上げるために、乱数シードを固定します。
また、ColabならGPUが使えるので、cuda が利用可能ならGPUを使いましょう。
### GPU使用状況の確認
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("device:", device)
1. MNIST前処理:Tensor化と標準化
学習の安定化のために、画素値を標準化するインスタンスを用意します。
### MNISTデータ前処理:画素値の標準化
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
2. Datasetクラスの定義
PyTorchでは、データを扱う単位として Dataset クラスを使います。
その重要なメソッドが、__len__ と __getitem__ です。
これらを実装することで、DataLoaderがミニバッチを組めるようになります。
### Datasetクラスの定義
class MNISTDataset(Dataset):
def __init__(self, root: str, train: bool, transform=None, download: bool = True):
super().__init__()
self.base = datasets.MNIST(root=root, train=train, transform=transform, download=download)
def __len__(self):
return len(self.base)
def __getitem__(self, idx: int):
x, y = self.base[idx] # xには画素値, yにはラベルが渡される
return x, y
train_dataset = MNISTDataset(root="./data", train=True, transform=transform, download=True)
test_dataset = MNISTDataset(root="./data", train=False, transform=transform, download=True)
3. DataLoaderクラスの準備
DataLoader クラスの操作により、ミニバッチ化・シャッフル・並列読み込みなどが可能になります。
-
shuffle=True:学習時に使用。毎エポックで順番をランダム化する。 -
shuffle=False:評価時に使用。順番固定。 -
num_workers:データ読み込みを並列化する worker 数。
### DataLoaderクラスの準備
batch_size = 128 # ミニバッチのサイズを指定
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=0, pin_memory=True)
4. CNNモデルの定義(Conv → Pool → FC)
MNISTの手書き数字の画像データ(1×28×28)を入力として、
- Conv(1→32) → ReLU → MaxPool(28→14)
- Conv(32→64) → ReLU → MaxPool(14→7)
- Flatten(64×7×7=3136)
- 全結合(3136→128→10)
という構成のシンプルなCNNを実装してみます。
オプティマイザーにはAdamを使用することにします。
形状の流れ(N:バッチサイズ)
- 入力: (N, 1, 28, 28)
- conv1後: (N, 32, 28, 28)
- pool後: (N, 32, 14, 14)
- conv2後: (N, 64, 14, 14)
- pool後: (N, 64, 7, 7)
- flatten: (N, 3136)
- fc1後: (N, 128)
- fc2後: (N, 10)(各クラスのlogit)
### モデル定義
class CNN(nn.Module):
def __init__(self, num_classes=10):
super().__init__()
# モデルを構成する各レイヤーを定義
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.dropout = nn.Dropout(0.25)
self.fc1 = nn.Linear(64 * 7 * 7, 128)
self.fc2 = nn.Linear(128, num_classes)
def forward(self, x):
# データの順伝播を定義
x = self.pool(F.relu(self.conv1(x))) # (N,32,14,14)
x = self.pool(F.relu(self.conv2(x))) # (N,64,7,7)
x = torch.flatten(x, 1)
x = self.dropout(x)
x = F.relu(self.fc1(x))
x = self.dropout(x)
x = self.fc2(x)
return x
model = CNN().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
5. 学習・評価ループの実装
5.1 学習(train)
学習ステップでは、以下が中心的な要素になります:
-
optimizer.zero_grad():前回の勾配を消す - forward:
logits = model(x):ロジット計算 - loss計算(BCEなど具体的な損失関数に依存)
-
loss.backward():勾配を計算 -
optimizer.step():実際にパラメータを更新
### モデルの訓練・評価
def train_one_epoch(model, loader, optimizer, criterion, device):
model.train()
total, correct = 0, 0
running_loss = 0.0
for x, y in tqdm(loader, desc="train", leave=False):
x, y = x.to(device), y.to(device)
optimizer.zero_grad(set_to_none=True) # 毎回のミニバッチの勾配のみを使うためにNoneでリセット
logits = model(x)
loss = criterion(logits, y)
loss.backward() # 損失の逆伝播により勾配を計算
optimizer.step() # パラメータを更新
running_loss += loss.item() * x.size(0)
pred = logits.argmax(dim=1)
correct += (pred == y).sum().item()
total += y.size(0)
return running_loss / total, correct / total
5.2 評価(eval)
評価では重み更新をしないので、以下が基本です:
-
model.eval():評価モードに設定 -
torch.no_grad():勾配を計算しないようにしてメモリ効率化
def evaluate(model, loader, criterion, device):
with torch.no_grad(): # 評価時には勾配計算を無効化する
model.eval()
total, correct = 0, 0
running_loss = 0.0
for x, y in tqdm(loader, desc="eval", leave=False):
x, y = x.to(device), y.to(device)
logits = model(x)
loss = criterion(logits, y)
running_loss += loss.item() * x.size(0)
pred = logits.argmax(dim=1)
correct += (pred == y).sum().item()
total += y.size(0)
return running_loss / total, correct / total
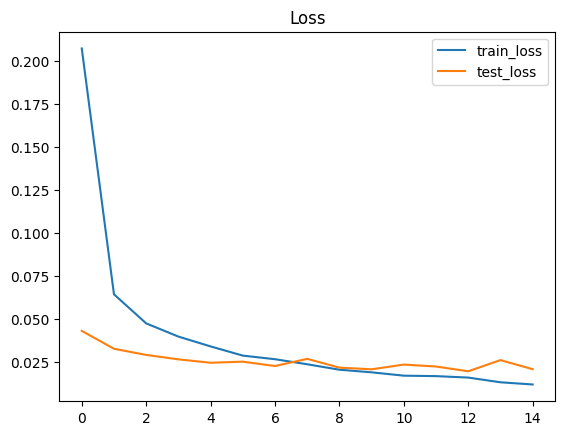
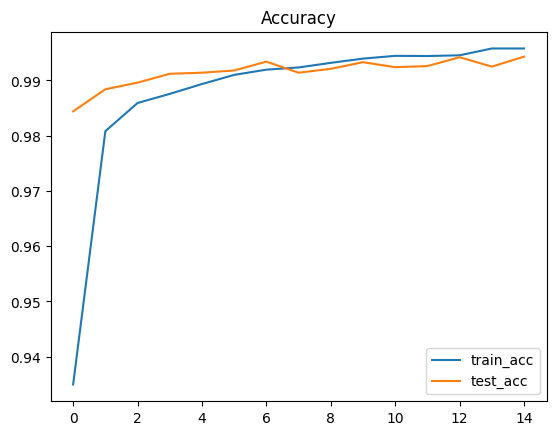
6. 学習の実行とログ表示 / 学習曲線の可視化(Loss / Accuracy)
エポックごとに
- train loss / train accuracy
- test loss / test accuracy
を出して、学習が進んでいるかを確認します。
epochs = 15
history = {"train_loss": [], "train_acc": [], "test_loss": [], "test_acc": []}
### モデル訓練
for epoch in range(1, epochs + 1):
tr_loss, tr_acc = train_one_epoch(model, train_loader, optimizer, criterion, device)
te_loss, te_acc = evaluate(model, test_loader, criterion, device)
history["train_loss"].append(tr_loss)
history["train_acc"].append(tr_acc)
history["test_loss"].append(te_loss)
history["test_acc"].append(te_acc)
print(f"Epoch {epoch:02d} | "
f"train loss {tr_loss:.4f} acc {tr_acc*100:.2f}% | "
f"test loss {te_loss:.4f} acc {te_acc*100:.2f}%")
### 学習曲線・性能評価結果
plt.figure()
plt.plot(history["train_loss"], label="train_loss")
plt.plot(history["test_loss"], label="test_loss")
plt.legend(); plt.title("Loss"); plt.show()
plt.figure()
plt.plot(history["train_acc"], label="train_acc")
plt.plot(history["test_acc"], label="test_acc")
plt.legend(); plt.title("Accuracy"); plt.show()
7. 新規推論デモ
テストデータからランダムに数枚取り、予測結果を表示します。
### 推論デモ
@torch.no_grad()
def show_predictions(model, dataset, device, n=12):
model.eval()
idxs = np.random.choice(len(dataset), size=n, replace=False)
cols = 6
rows = int(np.ceil(n / cols))
plt.figure(figsize=(cols * 2, rows * 2))
for i, idx in enumerate(idxs, 1):
x, y = dataset[idx]
logits = model(x.unsqueeze(0).to(device))
pred = logits.argmax(dim=1).item()
img = x.squeeze(0).cpu().numpy()
img = img * 0.3081 + 0.1307 # normalizeを戻す
ax = plt.subplot(rows, cols, i)
ax.imshow(img, cmap="gray")
ax.set_title(f"true:{y} pred:{pred}")
ax.axis("off")
plt.tight_layout()
plt.show()
show_predictions(model, test_dataset, device, n=12)

12枚のテストデータに対して、予測ラベルが正解ラベルと一致していることが確認できました。
改めて、深層学習ってすごいなあ。
おわりに
結局のところ、こういう基本的な題材で、基礎的な実装を理解しておくことが大事だと改めて実感しました。
- Dataset / DataLoader クラスの定義
- モデル実装の基本形
- train/evalの切り替え
- 勾配計算とパラメータ更新
- 学習曲線の確認
といった、PyTorch実装の重要ポイントが一通り確認できました。
次はOptunaでのハイパラ最適化についてまとめていきたいです。