概要
便利な正規表現関数を利用してテキストマッチングを行ってみたいと思います。
記事は下記の流れとなっています。
1. 正規表現とは
2. データ紹介
3. 正規表現関数を使った実践
4. BigQueryで使える正規表現関数について
※BigQueryのSQL言語設定は、標準です。
正規表現とは
以下Wikipediaからの抜粋です。
https://ja.wikipedia.org/wiki/%E6%AD%A3%E8%A6%8F%E8%A1%A8%E7%8F%BE
正規表現(せいきひょうげん、英: regular expression)とは、文字列の集合を一つの文字列で表現する方法の一つである。
ここで言うところの"文字列の集合"を不特定多数の人のメールアドレスと読みかえて、"一つの文字列で表現"をドメインと読みかえてみるとわかりやすいかもしれません。メールアドレスの構成は
[アカウント名] @ [ドメイン名] となっていますよね。例えば携帯会社A(ドメイン名:a.com)を利用している人だけを集計の対象としたい場合に、「@の前はなんでもよくて、ドメイン名はa.comの人 」なんていうざっくりした指定表現をできるのが正規表現です。
よく使う正規表現を下記に記載します。
集計対象に応じて、これらの正規表現を組み合わせて使います。
| 正規表現 | 意味 |
|---|---|
| . | 改行文字以外の任意の1文字 |
| * | 直前の1文字の0回以上の繰り返しに一致 |
| ^ | 行頭 |
| $ | 行末 |
| + | 直前の文字の1個以上の連続 |
| ? | 直前の文字の0または1文字にマッチ |
| \d | 0~9の数字 |
| pattern1|pattern2 | pattern1あるいはpattern2のいずれかにマッチ |
| \ | .やをリテラルで扱いたいとき (例: \. \) |
これらの記号を適切に組み合わせて、目的の正規表現を作るには、練習を要すると思われます。
簡単なWITH文を書いて、挙動を確認するのがおすすめです。
データ紹介
テーブル:book_app.book_buy_log
| buy_timestamp | login_email_address | book_name | price_yen |
|---|---|---|---|
| 2091/1/1 1:03 | email_A@email1.com | A(株)_omoroi_hon_1 | 3000 |
| 2092/2/2 2:02 | email_A@email1.com | A(株)_omoroi_hon_2 | 3000 |
| 2092/2/2 2:12 | email_A@email1.com | COGRAPH(株)_tanosii_hon_1 | 2000 |
| 2093/3/3 3:30 | email_A@email1.com | COGRAPH(株)_tanosii_hon_2 | 2000 |
| 2093/3/3 4:00 | email_A@email1.com | (有)A_tumaranai_hon_1 | 9999 |
| 2091/1/1 1:04 | email_B@email2.com | B(株)_kawaii_hon | 55000 |
| 2091/1/1 1:05 | email_B@email2.com | A(株)_omoroi_hon_1 | 3000 |
| 2092/1/1 1:05 | email_B@email2.com | (有)A_tumaranai_hon_1 | 9999 |
| 2091/1/1 1:07 | email_C@email3.com | A(株)_omoroi_hon_1 | 3000 |
| 2092/2/4 2:00 | email_C@email3.com | A(株)_omoroi_hon_2 | 3000 |
| 2093/3/3 9:03 | email_C@email3.com | A(株)_omoroi_hon_3 | 3000 |
| 2094/4/4 4:04 | email_C@email3.com | A(株)_omoroi_hon_4 | 3000 |
| 2091/1/1 1:17 | email_C@email3.com | COGRAPH(株)_tanosii_hon_1 | 2000 |
| 2092/2/2 2:05 | email_C@email3.com | COGRAPH(株)_tanosii_hon_2 | 2000 |
| 2093/3/3 3:33 | email_C@email3.com | COGRAPH(株)_tanosii_hon_3 | 2000 |
| 2094/4/4 4:14 | email_C@email3.com | COGRAPH(株)_tanosii_hon_4 | 2000 |
| 2091/9/1 1:27 | email_D@email4.com | (有)A_tumaranai_hon_1 | 9999 |
| 2092/8/2 2:02 | email_C@email3.com | (株)A_tumaranai_hon_98 | 99999 |
| 2091/10/1 1:17 | email_C@email3.com | B(株)_kawaii_hon | 55000 |
| 2092/2/2 2:02 | email_D@email4.com | (有)A_tumaranai_hon_1 | 9999 |
| 2093/3/3 3:03 | email_E@email5.com | (有)A_tumaranai_hon_1 | 9999 |
| スキーマ詳細は以下の通りです。 | |||
 |
正規表現関数を使った実践
早速ですが、正規表現関数を使って集計をしてみましょう。
ここで使うのはREGEXP_REPLACE関数です。
REGEXP_REPLACE(value, regex, replacement)
正規表現 regex と一致する value のすべての部分文字列が replacement で置き換えられて、STRING が返されます。
集計内容
メールアドレスからユーザー特定し、本のタイトル毎に購入金額を集計します。
すこし曖昧な指示になっているので、下記に例を示します、、、
テーブル:例
| buy_timestamp | login_email_address | book_name | price_yen |
|---|---|---|---|
| 2091/1/1 1:03 | email_A@email1.com | A(株)_omoroi_hon_1 | 3000 |
| 2092/2/2 2:02 | email_A@email1.com | A(株)_omoroi_hon_2 | 3000 |
上の場合は、アカウント名がemail_Aで一致していて、本のタイトルがomoroi_honで一致しているので合計は6000円。といったように集計するものとします。タイトルの前についている社名と、後ろについている数字は、無視するものとします。例えば、結果は下の通りとなります。
出力テーブル:例
|email_type|book_title|total_price_yen|
|----|----|-----|----|
|email_A|omoroi_hon|6000|
上記の集計内容を、正規表現関数を利用して集計してみましょう。
WITH with_1 AS (
SELECT
REGEXP_REPLACE(login_email_address, '@.+', '') AS email_type
, REGEXP_REPLACE(book_name, r'_\d*$', '') AS book_title
, price_yen
FROM
book_app.book_buy_log
) (
SELECT
email_type
, REGEXP_REPLACE(book_title, '^.+?_', '') AS book_title
, SUM(price_yen) AS total_price_yen
FROM
with_1
GROUP BY
email_type
, REGEXP_REPLACE(book_title, '^.+?_', '')
)
ORDER BY
email_type;
出力は以下の通りです。

結果
しっかりと結果が返ってきました。
ここでは、REGEXP_REPLACE関数を使って集計しました。
なお正規表現関数を使わず、ごり押しで集計した場合のクエリは以下の通りです。
WITH with_1 AS (
SELECT
buy_timestamp
, login_email_address
, SUBSTR(
login_email_address
, 1
, LENGTH(login_email_address) - 11
) AS email_type
, book_name
, CASE
WHEN SUBSTR(book_name, 5, 1) = '_'
THEN SUBSTR(book_name, 6, LENGTH(book_name))
ELSE SUBSTR(book_name, 12, LENGTH(book_name) - 11)
END AS book_title
, price_yen
FROM
book_app.book_buy_log
)
, with_2 AS (
SELECT
buy_timestamp
, login_email_address
, email_type
, book_name
, CASE
WHEN SUBSTR(book_title, LENGTH(book_title) - 2, 3) = 'hon'
THEN book_title
WHEN SUBSTR(book_title, LENGTH(book_title) - 4, 3) = 'hon'
THEN SUBSTR(book_title, 1, LENGTH(book_title) - 2)
ELSE SUBSTR(book_title, 1, LENGTH(book_title) - 3)
END AS book_title
, price_yen
FROM
with_1
)
SELECT
email_type
, book_title
, SUM(price_yen) AS total_price_yen
FROM
with_2
GROUP BY
email_type
, book_title
ORDER BY
email_type;
冗長で、汎用性が低いコードになってしまいました、、、
コードを書くのも大変ですし、メールアドレスや本のタイトル名の構成が変わると、正しい集計結果が出なくなる可能性があります。
BigQueryで使える正規表現関数
実践から、REGEXP_REPLACE関数がとても便利な関数であることが分かったと思います。
BigQueryで使うことができる正規表現関数には、他にREGEXP_CONTAINS、REGEXP_EXTRACT、REGEXP_EXTRACT_ALLが用意されているようです。こちらについても説明をしたいと思います。
REGEXP_CONTAINS関数使用例
REGEXP_CONTAINS(value, regex)
value が正規表現 regex に対して部分一致である場合、TRUE を返します。
上の説明を読んだ感じ、WHERE句内でLIKEの代わりに使用できる関数といったところでしょうか。
A(株)から出版されているものに絞って抽出します。実行するコードは次の通りです。
SELECT
*
FROM
book_app.book_buy_log
WHERE
REGEXP_CONTAINS(book_name, '^A\\(株\\).*');
正規表現でA(株)から始まるものを表現しています。

正規表現にマッチしたものが抽出できていますね。
REGEXP_EXTRACT関数使用例
REGEXP_EXTRACT(value, regex)
正規表現 regex と一致する value 内の最初の部分文字列を返します。
一致がない場合、NULL を返します。
今度は、正規表現に一致した箇所を抜き出してくる感じですね。
例えば、メールアドレスのドメインの種類が知りたいとします。その際のコードは以下の通りです。
SELECT DISTINCT
REGEXP_EXTRACT(login_email_address, '@.*') AS domain
FROM
book_app.book_buy_log
ORDER BY
domain;
問題なく結果が出力されました。

REGEXP_EXTRACT_ALL関数使用例
REGEXP_EXTRACT_ALL(value, regex)
正規表現 value と一致する regex のすべての部分文字列の配列を返します。
REGEXP_EXTRACTと似た関数ですが、異なる点としては、正規表現に一致した箇所をすべて抜き出してくる点です。こちらも実際に使ってみましょう。
SELECT
login_email_address
, REGEXP_EXTRACT_ALL(login_email_address, 'email') AS email_address_extract
FROM
book_app.book_buy_log;
結果の抜粋はこちらです。
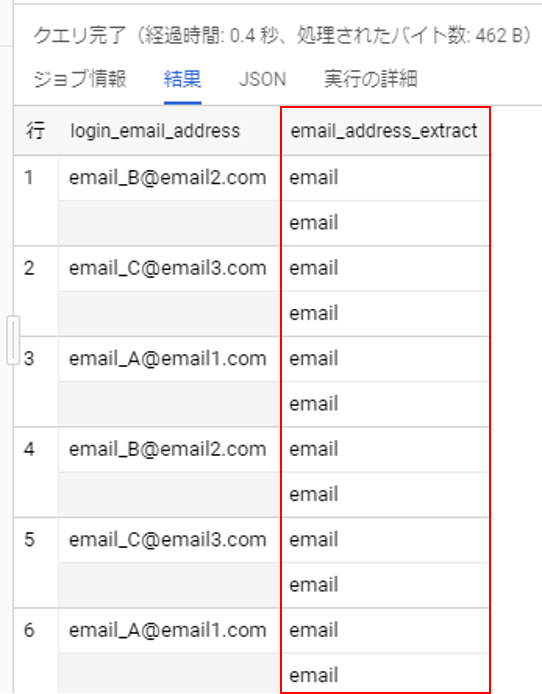
一つの行に対して、emailが二つずつ一致し、それらが抽出されました。
このような形で表現されるのですね。
まとめ
以上、BigQueryにて正規表現関数を使いテキストマッチングを行いました。
SUBSTRやCASE文を使って、がちゃがちゃとコードを書くのに比較して、コード量が減り、シンプルになるだけでなく、汎用性が高くなりましたね。便利な関数をしっかり使っていきましょう。
参考サイト
https://ja.wikipedia.org/wiki/%E6%AD%A3%E8%A6%8F%E8%A1%A8%E7%8F%BE
https://cloud.google.com/bigquery/docs/reference/standard-sql/functions-and-operators?hl=ja#regexp_contains
https://github.com/google/re2/wiki/Syntax