CSVファイルを簡単にselectしたかった。
H2 Databaseの準備
H2 Database Engineを公式サイトからダウンロード。
$ wget http://www.h2database.com/h2-2018-03-18.zip
$ unzip h2-2018-03-18.zip
$ sh ./h2/bin/h2.sh
流れでsh実行しちゃってるが、ブラウザが立ち上がり、コンソールが表示されれば準備OK
CSVをselectする
今回のCSVは郵便番号の一覧を使う。
$ wget https://www.post.japanpost.jp/zipcode/dl/kogaki/zip/ken_all.zip
$ unzip ken_all.zip
$ ls KEN_ALL.CSV
KEN_ALL.CSV
sqlはブラウザのコンソールから投げられる。
CSVファイルをテーブルとして扱うには CSVREAD関数を使えばOK。
select *
from
csvread('./KEN_ALL.CSV', null, 'shift-jis', ',')
limit 5
;
これでselectできる。
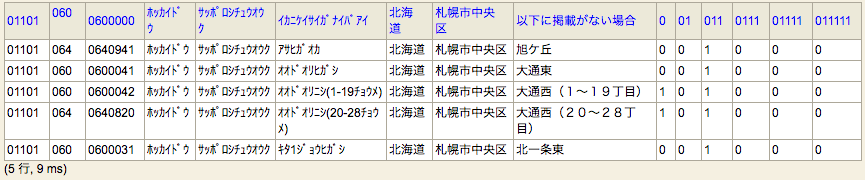
ヘッダーがおかしい。
CSVREADの第2引数をnullにするとCSVの1行目をヘッダーとして扱う模様。
select *
from
csvread('./KEN_ALL.CSV', ',,,,,,,,,,,,,,,', 'shift-jis', ',')
limit 5
;
カンマを入れると簡単に出せた。
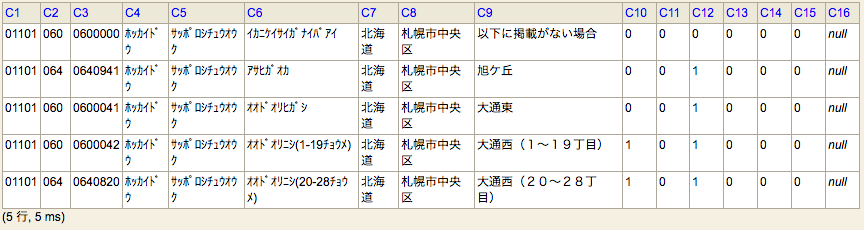
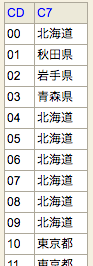
地域番号の一覧
郵便番号の3桁の内、頭2桁が地域番号になるので切り取ってグループ化する。
C10については 一町域が二以上の郵便番号で表される場合の表示 (注3) (「1」は該当、「0」は該当せず)とのことで、地域が曖昧な郵便番号を省く。
select substr(c2,0,2) cd, c7
from
csvread('./KEN_ALL.CSV', ',,,,,,,,,,,,,,', 'shift-jis', ',')
where 1=1
and c10=0
group by substr(c2,0,2), c7
order by cd
;
まとめ
単純なselectなら直ぐ返ってくるので便利。
テーブル結合しようとすると全然返ってこないので、パフォーマンス出したい場合はテーブルを作っちゃったほうがいい。
create table kenall as select * from csvread('./KEN_ALL.CSV', ',,,,,,,,,,,,,,', 'shift-jis', ',')
ちなみに、CSVファイル指定のカレントディレクトリは h2の親になってるのでご参考まで。
./KEN_ALL.CSV
./h2/bin/h2.sh
ちゃんちゃん。