やりたいこと(背景)
フロントエンドからファイルをActiveStorageでアップロードし、そのファイルを利用した処理を行う必要がある。
該当のファイルへの処理は数秒かかるためweb apiはすぐに返し、該当の処理を非同期実行することにした。
該当処理のOK / NGの結果に応じてユーザーに再度アップロード要求する必要があり、ユーザーには解析中という表示で待たせている。(処理に時間がかかりすぎた時の対応は別途検討してますが今回は省略)
サーバー処理が終わったらActionCableを利用してフロントに判定結果を返す。
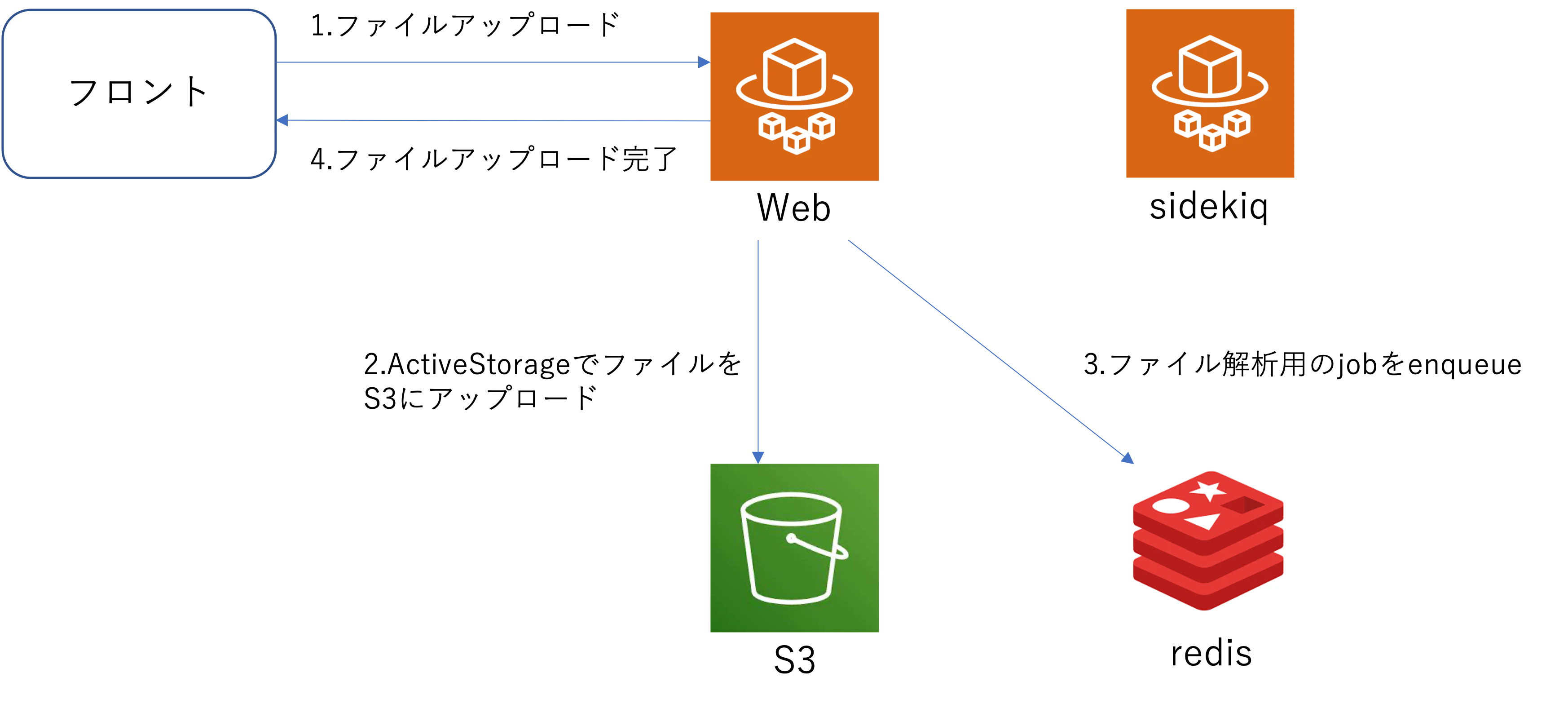
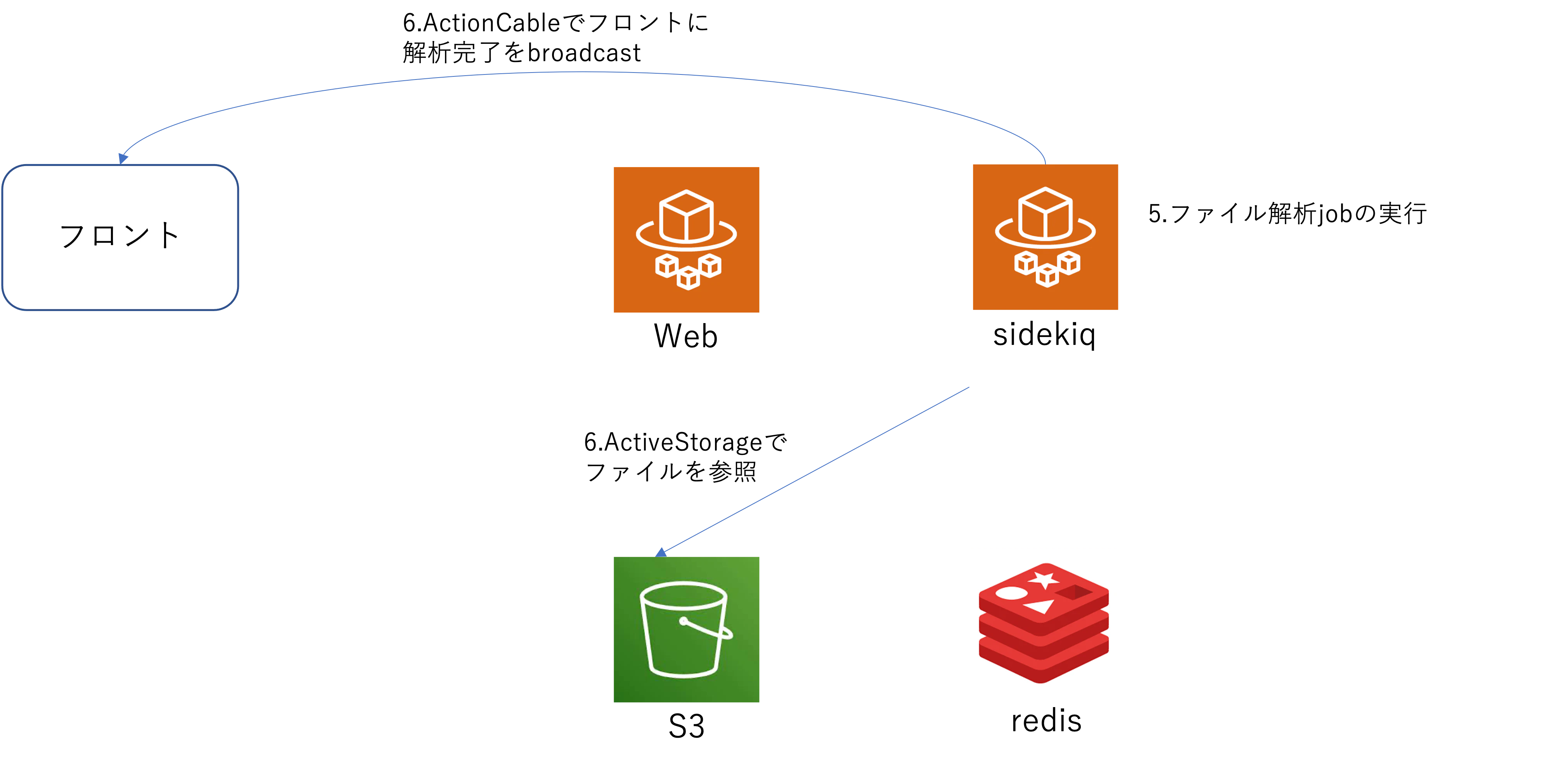
※ 簡素化しているため一部違和感があるかもしれませんが全体の流れの把握が目的のためご容赦ください。
発生した事象
step1: ステージング環境で ActiveStorage::FileNotFoundError が発生
起きた事象
解析用のworkerを perform_async で呼び出した結果、最初の1回目に高確率で ActiveStorage::FileNotFoundError が発生。
ただし、2回目のリトライ時には当該エラーが発生せず、正常終了していた。
原因
ActiveStorageのファイルアップロードジョブは非同期で行われており、「ActiveStorageのファイルアップロードジョブ」と「ファイル解析用のworker」のレースコンディションが起きていた。
対応
解析用のworkerの呼び出しを perform_in に変更した上でファイルアップロード後に実行されやすいようにした。
=> これにより ActiveStorage::FileNotFoundError の発生が落ち着いた(可能性が0ではないがそれはsidekiqのretryに流すことにしました)
SampleWorker.perform_in(0.2.second, ~~_id)
step2: 想定したパフォーマンスが出ない
起きた事象
解析用のworker自体は2-3s程度で終了する見込みであったが、フロントの体験的に遅延が起こるケースが多かった。
=> 正確には予想していた2-3sで終わることもあれば10s以上かかるケースもあった
原因(ここの詳細がメインテーマなので後述します。)
sidekiqを perform_in で実行すると Sidekiq::Sucheduled の機構に乗ります。
その場合、workerの実行までにperform_inで指定した秒数以上のpending時間がかかる。
対応
perform_async に戻し、worker側で ActiveStorage::FileNotFoundError をハンドリングするようにしました。
(別のいい対処法があればご教授願いたいです)
class SampleWorker
include Sidekiq::Worker
def perform(~~_id)
# ファイル解析処理
rescue ActiveStorage::FileNotFoundError
sleep(~) # ここの秒数は現在も調整中
SampleWorker.perform_async(~~_id)
end
end
実際の処理ではActiveStorageをattach指定るActiveRecordのcreated_atを見て直近にアップロードしたものでない時にはraiseするようにしました。
(ActiveStorageのファイルが別の理由で削除されていた時に無限にリトライされないように)
なぜ perform_in では指定した時間以上の時間がかかってしまったのか
わからないなりにコードを読んでみた。(全てを読んでるわけではないです)
参考: sidekiqコードリーディング
クラスについて確認
sidekiqのクラス関係(ざっくり)はこちら。

Jobをenqueueする
-
Sidekiq::Worker
- Railsにmoduleとして提供している。perform_inやperform_asyncを呼んだ時にSidekiq::Clientを介してredisにデータをpushする
- perform_inで指定された時間を計算してatオプションに変換する(参考)
-
Sidekiq::Client
- redisへのコネクションの管理とpushを行う * atオプションが指定されている時には "schedule" に対してatの時間と共にzaddされる
雑感:
WorkerとClientの責務分担がちょっと把握しきれなかったです。
- 何秒後に実施と指定した時にatオプションに変換するロジックがWorkerとClient両方にある。
- 元々Client側で実装していて、moduleをincludeするだけで簡単に使えるようにWorkerを追加したような気がしました。
Jobをdequeueする
-
Sidekiq::CLI
- sidekiqコマンドを解釈するための層。Launcherの実行を行う。
-
Sidekiq::Launcher
- sidekiqで必要な機能を起動する
- 以下の二つを起動
-
Sidekiq::Manager
-
Processorを必要数用意する
- 必要数のデフォルトは10で
concurrencyで外部から変更可能
- 必要数のデフォルトは10で
- Processorの起動
-
Processorを必要数用意する
- Sidekiq::Processor
-
Sidekiq::Scheduled::Poller
- 定期的に
Sidekiq::Sucheduled::Enqを呼び出す - 複数のsidekiqで実行されるため、
Sidekiq::Sucheduled::Enqを何度も呼び出さないように調整している -
random_poll_interval: Sidekiq::Sucheduled::Enqを呼び出す間隔を計算(プロセス数が増えてもいい感じになるように計算している)
-
poll_interval_average: それぞれのsidekiqプロセスでpollingする間隔。 -
average_scheduled_poll_interval: 複数のsidekiqプロセスでどれくらいのインターバルになることを期待するか(デフォルト 5s)
-
- sidekiqプロセスが10以内の時にはプロセスごとのインターバル時間の0.5-1.5倍の幅で実行される
- デフォルトの5sで考えると2.5-7.5s感覚でポーリングされる(プロセスが複数の時のワーストケースでは実行感覚がもっと広くなる)
- 定期的に
-
Sidekiq::Scheduled::Enq
- リトライ対象のものと "schedule" タグのものを取得して対象時間が過ぎているを取得してjobとしてenqueueする
perform_inしたらなぜ遅くなったのか
perform_inで実行した結果"schedule"タグでenqueueされる。
その結果 Sidekiq::Scheduled::Poller のポーリング時間が課題となっていました。
対応方針の検討で以下のパターンがありましたが、今回は後者を選択しました。
- average_scheduled_poll_intervalの感覚を短くする
- perform_inを使わずperform_asyncにする
上で行った時の懸念として、プロセス数が増えたときに同時実行のリスクが高くなり、予期せぬバグや負荷を招く可能性があると思いました。
まぁsidekiqに流したのにパフォーマンス気にするなよというごもっともなツッコミはあるのですが、、
誰かの参考になれば、そしてこうした方がいいぞというコメントいただけるとありがたいです