音声検索の先駆け!ハミングバードアップデートとは一体何だったのか
こんにちは!エイチーム引越し侍SEO担当をしています、@tatechiです。
今回は【SEO特許分析シリーズ第2弾】として音声検索の先駆けであるハミングバードアップデートの特許を分析していきます。
>SEO特許分析シリーズ第1弾:「【マニアックWeb担当者必見!】Google創成期の学術論文をめっちゃ詳しく解説してみた」はこちら
近年急速に進んでいる音声検索。
日本にいるとあまり実感は湧きませんが、広告代理店iProspectの調査によると、「半年以内に音声検索を利用したことがあるか」という質問に対して、インドでは82%・中国では77%が「利用した」と回答しており、世の中に浸透してきているようです![]()
音声検索という分野は、一見すると最近急に発達してきたテクノロジーのように思えます。
しかし、グーグルはなんと音声検索の準備を遅くとも2013年の時点から行っていました。
将来必ず来るであろう音声検索の準備として、検索アルゴリズムのアップデートを行っていたのです。
それがハミングバードアップデートです。
今回は音声検索の先駆けといえる、ハミングバードアップデートの仕組みを記述しているとされている特許、"Synonym identification based on co-occurring terms"をテーマに挙げて、音声検索に活用されている言語処理のアルゴリズムを紐解いていきます!
特許に入る前に、そもそもハミングバードアップデートとは?
ハミングバードアップデートとは、複雑な検索キーワードに対して、そのキーワードの背景と文脈を理解してより関連性が高く的確な検索結果を提示するためのアルゴリズムです。
ハミングバードアップデートでは、特に「会話型検索(つまり音声検索)の処理能力」が上がったと言われています。
ちなみに、ハミングバードとは「ハチドリ」の意味。

ハチドリはとても素早く動くことができることから、「素早く正確に」対応できるようなアップデートとして命名されています。
パンダアップデートやペンギンアップデートのように有名ではないハミングバードアップデート。
しかし、ハミングバードアップデートは検索エンジンの大きな進歩の一つだったと個人的には思っています![]()
ここからは、ハミングバードアップデートが検索エンジンにもたらした変化を説明していきます。
ハミングバードアップデートで何が変わったのか
では、ハミングバードアップデート以降、グーグルの検索結果はどのように変わったのでしょうか?
「五反田の近くの泊まれる場所」で検索した場合のイメージを例に挙げて説明してきます。
(※やや極端な例を挙げて説明していきます。当時の実際の検索結果とは異なる可能性があるのでご了承ください…)
- ハミングバード以前
- 「五反田」、「近く」、「泊まれる」、「場所」というキーワードの文字列が含まれるキーワードを返すアルゴリズムでした。 なので極端な例だと、「五反田の駅の近くの場所に住んでいると、友達から『今日泊まれる?』って連絡が来ることがある~」という文章のコンテンツも、検索上位に返ってくる可能性があります。
- ハミングバード以降
- 検索エンジン側が「泊まれる場所」=「ホテル」・「宿泊施設」と認識するようになりま した。
つまり、ハミングバードアップデートによってGoogleは検索クエリ(キーワード)の意図や背景・文脈を理解できるようになりました!
そしてその結果、会話型検索を行ったときに、ユーザーの意図や文脈に沿った検索結果を返せるようになりました!
それでは、どのような言語処理が行われて、このハミングバードアップデートは可能になっているのでしょうか?
特許から読み解いていきましょう!
Googleの特許:"Synonym identification based on co-occurring terms"
ここからは、"Synonym identification based on co-occurring terms"(共起語に基づいた同義語の識別)を分析しながら、ハミングバードアップデートの理解を深めていきましょう。
まずは全体の流れから
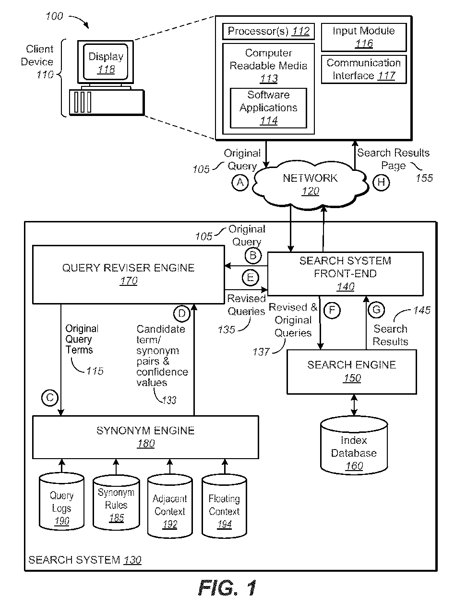
(参照:Synonym identification based on co-occurring terms )
上の図は、検索リクエストから検索システムが検索結果を届けるまでの流れが書かれています。
図の中に割り振られている数字をもとに説明をしていきますが、ややこしい点はざっと読み飛ばしてしまっても大丈夫です![]()
システム100には、クライアントデバイス110と検索システム130、そしてそれらをつなぐネットワーク120が含まれています。
- クライアントデバイス110:パソコンやスマホなど、ユーザーが検索リクエストを行う端末
- 検索システム130:検索エンジンを含んだシステム一式
- ネットワーク120:クライアントデバイス110と検索システム130をつなぐネットワーク
そして、検索システム130には、検索エンジン150と、クエリ修正エンジン(query revise engine)170、そして同義語エンジン(synonym engine)180が含まれています。
検索システム130は、ユーザーが端末に入力したオリジナルクエリ105(B)を受け取ります。
そして、クエリ修正エンジン170などでいろいろな作業を行った後で、修正クエリ135を検索エンジンに提示しているのが、この図からわかります。
ここで大切な点は、ユーザーが検索ボックスに入力した初期クエリを検索システム130の中で変換して、検索結果を提供しているということです。
人間が入力したクエリを検索システムが解釈し、より良い形に変換・修正して、修正済みクエリを検索エンジンに投げている、というすごい処理が行われているんですね![]() !
!
この変換のフローを詳しく説明していきます。
検索システムがクエリを書き換えるまでの流れ
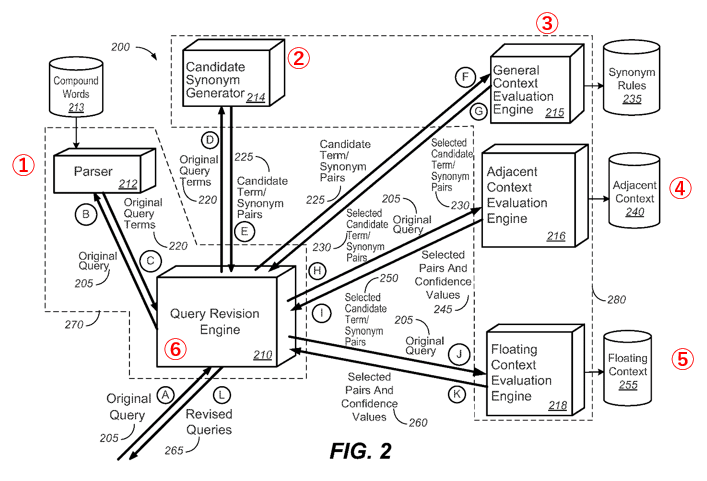
(参照:Synonym identification based on co-occurring terms )
ここからは、検索システムが初期クエリを書き換えるときの流れを重点的に説明していきます。
ここで主役になるのが、先ほど登場したクエリ修正エンジン170です。
ここからは図が変わったことで番号が振りなおされ、クエリ修正エンジン210として紹介します。
上の図には、赤字で①~⑤の番号を付けています。
ここからはその番号に沿って、どのような処理が行われるのか見ていきましょう。
まずは詳細説明バージョンから行きます!
1. 212パーサーが検索クエリ内にあるスキップキーワードや、複合語・フレーズを識別
スキップキーワードとは、検索において意味をなさないキーワードを指します。
例えば、検索クエリが"I want to read a book of Shakespeare Romeo and Juliet"の場合、"a"などはスキップキーワードと見なされます。
また、"Romeo and Juliet(ロミオとジュリエット)"という言葉はフレーズになって初めて意味を発揮します。
単純に"Romeo"という言葉をたくさん含んだ検索結果を返しても、ユーザーが求める検索結果にはならないでしょう。
この212パーサーでは、そのスキップキーワードやフレーズを識別します。
2. 214同義語候補ジェネレーターで同義語候補のペアを作成
次に214同義語候補ジェネレーターでは、いつどのような状況でも同義語となる言葉のペアを作成します。
3. 214同義語候補ジェネレーターで作られた同義語セットを215一般コンテキスト評価エンジンに送信
前述のとおり、214一般コンテキスト評価エンジンでは、普遍的な同義語をチェックします。
例:解約→解除、キャンセル、取りやめ、など
このときに235同義語ルールデータベースを用いて、各同義語には信頼スコアが割り振られます。
4. 216隣接コンテキスト評価エンジンにも同義語候補セットを送る
216隣接コンテキスト評価エンジンも、隣接コンテキストデータベースを用いて各同義語候補に信頼スコアをつけます。
5. 218浮遊コンテキスト評価エンジンにも同義語候補セットを送る
218浮遊コンテキスト評価エンジンも、隣接コンテキストデータベースを用いて各同義語候補に信頼スコアをつけます。
6. 修正版のクエリを検索エンジンに送信
3~5の処理で受け取った同義語候補と信頼スコアをもとに、最終的な同義語候補を割り出し、修正版のクエリを検索エンジンに投げます。
ここまでの説明だと正直わかりづらいですよね…![]()
ざっくり説明すると、以下のような流れになります。
- スキップする(検索エンジンに送る意味のない)キーワードを識別する
- フレーズ・複合語でないと意味をなさないキーワードを識別する
- 214同義語候補ジェネレーターで普遍的に同義語となる候補のセットとその信頼スコアを出す
- 216隣接コンテキスト評価エンジンで3で出された同義語候補に信頼スコアをつける
- 218浮遊コンテキスト評価エンジンでも3で出された同義語候補に信頼スコアをつける
- 信頼スコアをもとに適切な同義語を候補の中から選び、検索クエリを修正する
214同義語候補ジェネレーターで普遍的な同義語を出すのはまだイメージがつきますが、216隣接コンテキスト評価エンジン・218浮遊コンテキスト評価エンジンって謎ですよね…![]()
ここからは、216隣接コンテキスト評価エンジン・218浮遊コンテキスト評価エンジンに焦点を当てて説明していきます。
216隣接コンテキスト評価エンジンで行う処理
216隣接コンテキスト評価エンジンで行う処理は、文字通り特定のキーワードに隣り合った単語をもとに、同義語の評価を行います。
「I want to read a book of Shakespeare "Romeo and Juluet"」という検索クエリを例に挙げて説明していきましょう。
216隣接コンテキスト評価エンジンよりも前に処理が行われる、214同義語候補ジェネレーターでは、【スキップキーワードの識別】【同義語候補の提供】の二点の処理が行われています。
まず、スキップキーワードが除外された結果、検索クエリは以下のようになりました。
Before:I want to read a book of Shakespeare "Romeo and Juluet"
After :read book Shakespeare Romeo and Juliet
だいぶシンプルになりましたよね??
そしてこの場合では、214同義語候補ジェネレーターは"book"="play"が同義語の関係では?と提示してきたと仮定しましょう。
そのとき、216隣接コンテキスト評価エンジンは書き換え対象である"book"という単語と隣接しているreadとShakespeareの2単語を見に行きます。
まずreadを見に行ったとき、216隣接コンテキスト評価エンジンは以下の2単語のセットが自然であるかをチェックします。
After① :read play
「劇を読む?」「読む・遊ぶ?」どちらにしても不自然な言葉ですよね。
この場合、信頼スコアは閾値を超えないでしょう。
対して、Shakespeareを見に行った時。
After②:play Shakespeare
「シェイクスピアの劇」ということで意味が通じますよね?
よって、この観点から見ると、"book"="play"の同義語の関係は成立することになり、信頼スコアは閾値を超えてきます。
このとき、少なくともどちらか片側の隣接単語の信頼スコアが閾値を上回ったら、隣接コンテキスト評価エンジンは、それが同義語であると判断します。
逆に、ここで閾値を上回る同義語セットが出てこなかった場合には、216隣接コンテキスト評価エンジンは同義語なしと判断し、210クエリ修正エンジンに結果を返すことはありません。
218浮遊コンテキスト評価エンジンで行う処理
218浮遊コンテキスト評価エンジンは、216隣接コンテキスト評価エンジンとは違って、隣接していない単語からも同義語かどうかを判断します。
先ほどと同様に、ロミオとジュリエットを例にあげて説明していきましょう。
216隣接コンテキスト評価エンジンで見たときは、book=playの同義語関係が成り立つと判断されました。
でも「本」と「劇」って正直違いますよね![]()
ここに疑いのメスを入れるのが、218浮遊コンテキスト評価エンジンです。
218浮遊コンテキスト評価エンジンは(おそらくナレッジグラフを活用しているため)シェークスピアが劇作家であることを認識し、それによって、book Shakespeareもplay Shakespeareも成り立ってしまったこと、でも劇と本は別物であること、の両面を把握して、book→playの同義語関係は成り立たないと判断できる機関です。
すごく賢いですよね![]()
では、別の検索クエリを例に挙げてみてみましょう。
検索クエリ:What is the number of pilots that are female at AA as of January 2011?
同義語候補①:AA→American Airline
同義語候補②:AA→Alcoholic Anonymous(アルコール中毒者更生会)
216隣接コンテキスト評価エンジンで見るとき、チェック対象は以下の2つになります。
- female AA
- AA January
同義語候補①も②も意味的に成り立ってしまいそうですよね…
しかし、218浮遊コンテキスト評価エンジンでは、AA→American Airlineと正しく判断できます。
なぜなら、218浮遊コンテキスト評価エンジンは文章全体が評価対象になります。
そして、"pilot"という単語の存在に気づき、それは同義語候補①American Airlineの共起語であると認識できるからです。
このようなステップを踏んで、検索システムは検索エンジンにクエリを送信する前に、クエリをより良いかたちに書き換えます。
その結果、「泊まれる場所」のような曖昧な検索クエリでも、「ホテル」という同義語に書き換えられた状態で検索結果を提示されるので、ユーザーのニーズに沿った答えを返すことができるのです。
この処理ができるから、「今日のここの天気を教えて」という音声検索に対して、グーグルはクエリを「2019年7月16日 天気 東京都品川区」などに書き換えて検索エンジンにリクエストを送れます。
それができるから、今日の・ユーザーがいる場所にあった天気を検索して返すことができるのです![]()
今回はややマニアックなハミングバードアップデートの特許を扱いました。
現在の検索アルゴリズムはより複雑で、様々な指標を見ながらサイトの評価を行っています。
「今こんな古い情報を追いかけてどうするの?」という方も多いのではないでしょうか?
しかし、Googleの基礎を理解してこそ、行うことができる施策も多々あります。
SEO担当がこんなことを知ってどうなるの?と思った方!
エイチーム引越し侍では現在様々なサイトを運営しています。
そして、この論文でグーグルの構造を理解して、そこから得た仮説を施策に落とし込み、
実際の検索結果に影響が出るかどうかの検証を日々行っています。
▼運営サイト一例
「もっと深くSEOを理解をしたい!」
「複数のサイトのSEOを担当したい!」
そんな方は、ぜひエイチーム引越し侍の採用サイトにご連絡ください。
皆さんのご連絡をお待ちしております!!