Google創成期の学術論文をめっちゃ詳しく解説してみた
こんにちは!エイチーム引越し侍SEO担当をしています、@tatechiです。
突然ですがみなさん、↓の3つの質問に答えることはできますか?
- googleの語源は何?
- 創業時のgoogleはどこが革新的だったの?
- googleが検索結果を返す仕組みはどうなっているの?
SEO担当としてGoogleのことを知るのはとっても大切なことです。
ですが、Googleの仕組みって、意外と知らない人も多いのではないでしょうか?
今回はGoogle誕生の瞬間ともいえる学術論文"The Anatomy of a Large-Scale Hypertextual Web Search Engine"をテーマに挙げて、かみ砕いてGoogleの基礎を紹介していきます。
先ほどの3つの質問のうち、1つでも即答できなかった人は、ぜひ読んでみてください!
Googleが誕生したときのWEB業界
当時の検索エンジンは大きく2つの種類に分けられました。
- 人間チェック検索エンジン
- 人が目視で確認した基準をもとに検索結果を返すため、高品質。 ただし、主観的で、構築・維持にかかるコストが大きい、改善に時間がかかる、難解なトピックスまでカバーできない、といった問題がある 当時のYahoo!はこちらに該当します。
- 自動化検索エンジン
- キーワードのマッチ度に依存した検索結果が表示されるため、スパムが多く低品質。
人が目視でチェックするなんて、今じゃ絶対考えられないですよね…
もしも今でも検索結果が人の目で決まっていたら、わいろが横行していたかも![]() ?!
?!
ぱっと見ただけでもわかるように、当時の2種類の検索エンジンの両方に大きな課題がありました。
その課題を解決するために生まれたプロトタイプが"Google"です。
では、なぜGoogleならば、上記の問題を解決できるのか?
その鍵となるのが、ページランクの導入です。
(小ネタ)Googleの語源
ちなみに、システム名の"Google"とは、10の100乗という英単語、googolに由来しています。
ラリー・ペイジが"googol"の単語のスペルを間違えて、"google"と書いてしまったことで、その名が決まったそうです。
今も昔も、googleってお茶目なところがありますよね![]()
ページランクの導入
論文内では、Googleの検索エンジンの特長的なポイントは、以下の2つだと述べられています。
- それぞれのページの品質ランク(ページランク)の計算に、Webのリンク構造を使うこと
- 検索結果の改善のためにリンクを利用すること
セルゲィ・ブリンとラリー・ペイジは、なんと51,800,000,000ものハイパーリンクをウェブ上から集め、リンクマップを作ってみたそうです!
そうすると、どうも引用重要度の指標としてページランクを使用したら、人々の主観的な重要度によく似た結果になったんだとか。
このことから、**「これまでの自動化検索エンジンのキーワードのマッチ度に加えて、ページランクによる優先順位付けを導入すれば、検索エンジンの質はもっと高くなる!」**と考えたわけです。
ページランクの計算方法
この当時でも、学術論文などでは特定のページへの引用数やバックリンク数を数えることで、Webでの評価が行われていました。
しかし、Googleのページランクではここにさらに2つの工夫を加えています。
- すべてのページからのリンクを同等としてカウントしない
- ページ上のリンク数によって平準化する
これは具体的にどう考えるのか?詳しく説明していきます。
ページAはページT1・・・Tnからリンクを貼られていると仮定します。
パラメータdは減衰係数で、0と1の間で設定されます。(※通常d=0.85に設定されます)
C(A)はページAから出て行くリンクの数と想定する。
そのとき、ページAのPageRankは以下の計算式から割り出されます。
PageRank(A)=(1-d)+d(PR(T1)/C(T1)+・・・+PR(Tn)/C(Tn))
では、検索エンジンはこのページランクをどのように処理するのでしょうか?!
システム構造の説明に入ります!
Googleのシステム構造
当時のGoogleのシステムは、大きく12個の機関に分けられます。
その12個の機関のフローを描いた図が以下のものです。
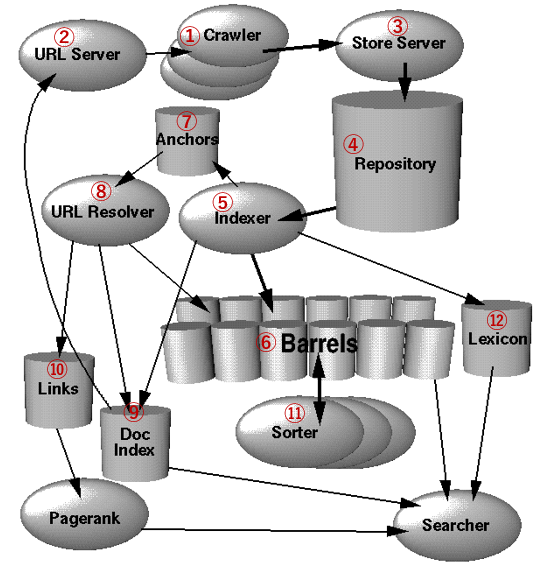
引用:The Anatomy of a Large-Scale Hypertextual Web Search Engine
(※Googleの論文で登場する図に、筆者が番号を勝手につけています。)
それぞれの機関の役割について説明していきます。
まずは全体像を説明していくので、見たことのない言葉もたくさん出てきますが、どうか離脱しないでざっと読んでみてください!
- ①クローラー
- Webのクローリングをする
- ②URLサーバー
- クローラーにフェッチするURLのリストを送信する
- ③ストアサーバー
- フェッチされたWebページが送信される場所。ストアサーバーは次にウェブページを圧縮して④レポジトリに格納する。
- ④レポジトリ
- ストアサーバーによって圧縮されたWebページを格納する。
- ⑤インデクサ
- レポジトリに格納されたデータを読み込み、ドキュメントを解凍し、解析する。そして各文書はヒットと呼ばれる一連の単語に変換される。
- ⑥バレル
- バレルとは"樽を意味している。⑤Indexerで変換されたヒットを格納する場所。
- ⑦アンカーファイル
- ⑤インデクサがそれぞれのウェブページのリンクを解析し、その情報を格納する場所。
- ⑧URLリゾルバー
- アンカーファイルを読み取り、相対URLを絶対URLに変換し、⑨docIDに変換する場所。このdocIDから⑩リンクデータベースを生成する。
- ⑪ソーター
- 並び替えの"sort"に"er"がついた英単語。⑥バレルの情報を取得し、docIDで並び替える。ここで逆インデックス(転置リスト)を作るために、wordIDによって整理し、オフセットのリストを作る。
- ⑫レキシコン
- インデクサーによって作られた辞書ファイルと、ソーターによって作られた転置リストをまとめる。Webサーバーによってサーチャーが実行されたら、転置リスト(逆インデックス)で単語を探し、ページランクとレキシコンを使用してクエリに応答する。
ここまででわかりづらい箇所も多々あったかと思います。
それぞれの内容についてくわしく説明していきますね。
クローリングとは
そもそもグーグルが検索結果を決めて表示するまでのフリーは大きく3つのステップに分けられます。
- クロール
- インデックス
- ランキング
その一つ目のステップ「クロール」とは、グーグルのbotがウェブページを発見することを指します。
インデックスとは
クロールの次のステップであるインデックスとは、直訳すると索引・見出しなどの意味を持ちます。
SEOにおけるインデックスとは、クローラーが集めたWebページのデータを、検索エンジンのデータベースに、処理しやすいように加工された状態で、格納されることを指します。
そして、検索エンジンによって処理しやすいかたちに変換する中間処理のプログラムが、先ほど登場した⑤インデクサということになります。
インデクサの役割
前述のとおり、インデクサは検索エンジンが処理しやすいかたちにデータを変換してから、データベース(バレルやレキシコン)に格納する役割を果たしています。
そのときに行う変換処理が、先ほど登場したヒット・docID・wordIDなどに関わってきます。
たとえば、"I like search engines."という文章があったとします。
検索エンジンというシステムはこの文章をこのまま格納するのが苦手です。
よって、この文章を単語ごとに"I"、"like"、"search"、"engines"とバラバラにすることにしました。
このバラバラにされた単語が、先ほど登場した「ヒット」です。
転置とは
たとえば、下記のような文書1・2があったとします。
文書1:このページでは検索エンジンについて解説します。
文書2:転置索引は検索エンジンの重要な要素です。
この文書を解析した結果を以下の表とします。

しかし、グーグルの検索エンジンはこの表の左から右しか見れないとイメージしてください。
そうすると、グーグルは「検索」という言葉を文書1も2も含んでいることに気づくことができません。
(もしくは、気づくために文書1・2の全文を見に行くので、処理に時間がかかるでしょう。)
では、検索エンジンが「検索」という言葉が文書1・2の両方に含まれていることに効率的に気付くには、どうしたらよいのでしょうか?
そんなときに作られるのが転置ファイルです。
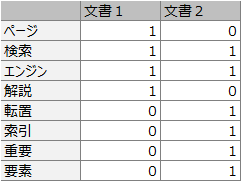
このように表の縦と横をひっくり返すことで、左から右しか見れない検索エンジンでも、「検索」という単語を文書1・2の両方が持っていることにいち早く気づくことができるでしょう。
この作業を行っているのが⑪ソーターでした。
バレスに格納した単語区切りの情報をまずは文書1・2のようなdocIDで並び替え、その後で上の転置ファイルを作成して、単語ごとにwordIDを割り振ります。
そしてwordIDごとにそれを含む文書の一覧を持つことで、検索エンジンは効率的にその単語を含む文章を見つけることができます。
その結果、ユーザーからのリクエストに対していち早いレスポンスを返すことができるのです。
ここまではクロール・インデックスの基本処理を説明しました。
では、グーグルのリンク構造理解について説明していきます。
Googleのリンク構造解釈
冒頭でもお話ししたように、当時の検索エンジンの中でGoogleが優れていた点はリンク解析によって導き出されるページランクをもとに、検索結果のランク付けを行える点です。
それを可能にしているのが、⑦アンカーファイルと⑧URLリゾルバーです。
アンカーファイルとURLリゾルバーの役割
アンカーファイルには、インデクサがWebページ内のすべてのリンクを解析した結果が格納されています。
そして、URLリゾルバーでは、アンカーファイルを読み取って、そのWebページからどのWebページにリンクが貼られているのか、どのようなアンカーテキストでリンクが設置されているのかを分析して、リンクデータベースを作成しています。
そしてこのリンクデータベースの情報をもとにページランクが計算されて、ランキングアルゴリズムに反映されているのです。
「かつてのSEOではリンクの獲得が重要視されていた」というのはご存知ですか?
これは、リンク解析において、自サイトが他のサイトから特定のアンカーテキストでたくさんリンクを貼られていれば、そのアンカーテキストに含まれるキーワードでの順位が上がる仕組みに付け込んだものでした。
もちろん、現在のグーグルでは改善が進み、上記の方法でのSEO対策はブラックハットSEOとしてリスキーな手法になっています。
しかし、この考え方こそが、当時の検索業界においてグーグルが革新をもたらしたアイデアだったのです。
今回はGoogle創成期の非常に古い特許を扱いました。
現在の検索アルゴリズムはより複雑で、様々な指標を見ながらサイトの評価を行っています。
「今こんな古い情報を追いかけてどうするの?」という方も多いのではないでしょうか?
しかし、Googleの基礎を理解してこそ、行うことができる施策も多々あります。
SEO担当がこんなことを知ってどうなるの?と思った方!
エイチーム引越し侍では現在様々なサイトを運営しています。
そして、この論文でグーグルの構造を理解して、そこから得た仮説を施策に落とし込み、
実際の検索結果に影響が出るかどうかの検証を日々行っています。
▼運営サイト一例
「SEOの研究をしたい!」
「複数のサイトのSEOを担当したい!」
そんな方は、ぜひエイチーム引越し侍の採用サイトにご連絡ください。
皆さんのご連絡をお待ちしております!!