構造化データマークアップ入門
こんにちは!エイチーム引越し侍でインハウスSEO担当をしています、@tatechiです。
突然ですが、最近グーグル検索をして、「検索結果がゴージャスになってる!」と思うことはありませんか?
たとえば、「トマトパスタ レシピ」で検索したとき。
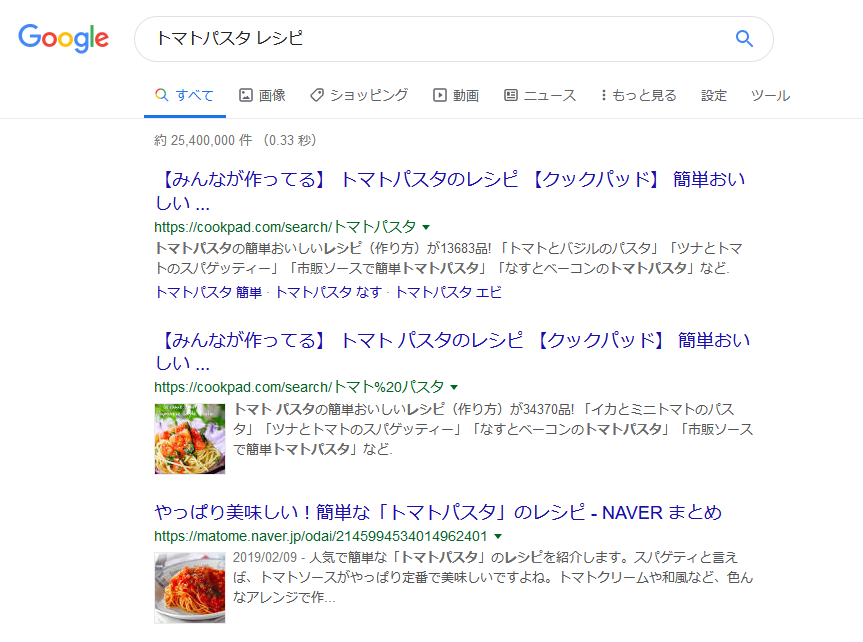
検索結果にトマトパスタの写真が出ていて、サイト名にアクセスしなくてもどんなトマトパスタを作るためのレシピがわかるようになっています。
「少し前はタイトルとディスクリプションしか出ていなかったのに…」と思うと、めちゃくちゃ豪華な検索結果になりましたよね![]() ?!
?!
このゴージャスな検索結果のことをその名の通りリッチリザルトといいます。
これは全部、![]() 構造化データマークアップ
構造化データマークアップ![]() のおかげです
のおかげです
そして近年、SEO界隈ではこの構造化データマークアップが盛り上がっています…!
今回はエンジニアが最低限知っておくべき構造化データマークアップの基礎を紹介します。
検索エンジンのトレンドの波に乗るために、ぜひ読んでみてください!
そもそも構造化データって何?
構造化データとは、Webコンテンツ内の文字の意味を正しくロボットに読ませるための形式を指します。
手塚治虫を例に挙げて説明してみると…
たとえばこんな文章。
手塚治虫は1928年11月3日に大阪府豊能郡豊中町で生まれました。
この文章からは以下の2つの情報が読み取れます。
- 手塚治虫の生年月日:1928年11月3日
- 手塚治虫の生まれた場所:大阪府豊能郡豊中町
この文章は人間ならちゃんと意味がわかるのですが、ロボットは100%読み切れるとは限りません。
では、ロボットにも上の情報を理解させるためにはどうすれば良いのか?
そこで登場するのが構造化データマークアップです。
上記の情報を構造化データマークアップすると、こんなふうに記述されます。
<script type="application/ld+json">
{
"@context": "http://schema.org",
"@type": "Person",
"name": "手塚 治虫",
"birthDate": "1994-08-19"
"birthPlace": "大阪府豊能郡豊中町"
}
</script>
この形式であれば、ロボットは正しく文章の中身を理解することができます。
そして文章の中身を正しく理解することで、検索結果をこんなにリッチにすることができます。
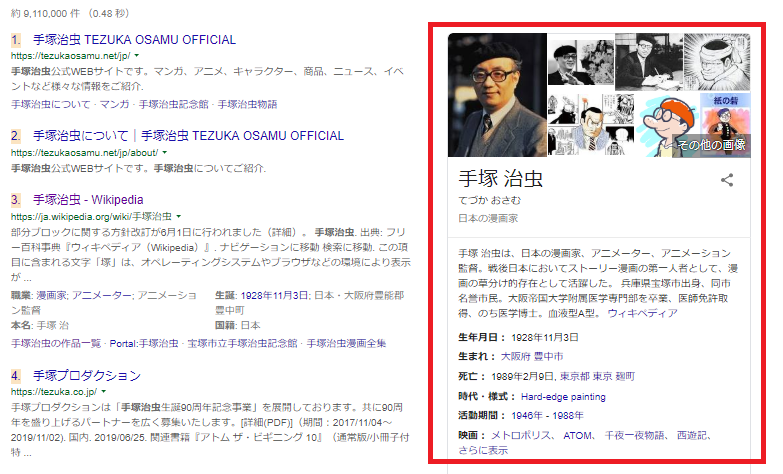
この構造化データマークアップの話題がSEO界隈で出現し始めたのは大体2013年ごろです。
それではなぜ、今構造化データマークアップが盛り上がってきているのでしょうか?
構造化データマークアップを取り入れる意義
「SEO担当者が気にしているということは、構造化データマークアップはグーグルのランキングアルゴリズムの一部なのでは![]() ?」と思う人も多いでしょう。
?」と思う人も多いでしょう。
実は、構造化データマークアップは現時点ではグーグルのランキングアルゴリズムの対象だと言及はされておりません!
しかし、構造化データマークアップをすることで、以下の2つのメリットがあります。
- 構造化データマークアップで自社の検索結果がリッチになれば、検索結果上で目立つので、CTRが上がる可能性がある
- グーグルのbotにサイト内の内容を正しく伝えられるので、適切にコンテンツを評価されて、コンテンツの価値が見直されるかもしれない
どちらも間接的な効果です。
しかし、昨今のグーグルの公式発表で構造化データマークアップに関する告知が増えてきていることから察すると、今後この構造化データマークアップの重要度が高まってくると考えて良いでしょう。
では、この構造化データを正しくマークアップするために、エンジニアが最低限知っておくべき知識を紹介していきます。
構造化データマークアップの基礎知識
構造化データマークアップを行う際に、下記のような悩みを持ったことはありませんか?
- 「schemaとJSON、どちらで組み込んだら良いのかな?」
- 「microdataではダメなのかな?」
1.の悩みを持った人は、そもそも構造化データマークアップの仕組みをわかっておりません!
そして2.の悩みを持った人は、昨今の構造化データマークアップのトレンドを理解していない可能性があります!
構造化データにはたくさんの種類があります。
まずマークアップをするときには、構造化データの仕組みを正しく理解して、どの言語で、どんなふうにマークアップをするのかを定義しなければなりません。
そのときに定義するのが、ボキャブラリーとシンタックスです。
ざっくりいうと、ボキャブラリーとシンタックスの位置づけはそれぞれ下記のようなイメージです。
- ボキャブラリー
- 構造化データの言語の種類を指定するイメージです。 構造化データにはdata-vocabularyやschema、FOAFなどいろいろな種類がありますが、「今からはschemaで話していくよ!」と伝えるためにボキャブラリーを指定します。
- シンタックス
- 単語の意味をロボットに伝えるための文法書のようなイメージです。 ボキャブラリーでschemaを指定したなら、schemaの中のどんな文法で話すのかも指定しなければいけません。
例えるなら、
- 今から日本語で話します。→ボキャブラリー:日本語
- 日本語の中でも関西弁風でいきます。→シンタックス:関西弁
みたいなイメージでしょうか![]()
では、このボキャブラリーとシンタックスはどのように定義していけば良いのでしょうか?!
詳しく説明していきます!
Googleがサポートしているボキャブラリー
Googleが現在指定しているボキャブラリーは2つあります。
- data-vocabulary.org
- schema.org
しかし、data-vocabularyは現在その機能をschemaに引き継いでいます。
なので、今から構造化データマークアップをするならば、schema一択で行きましょう!
ちなみに、Googleは公式に推奨していませんが、microformatsでマークアップした記事を構造化データテストツールにかけても、正しく認識されているそうです。
schema.orgとは
schema.orgはGoogle, Yahoo, microsoftの3社で策定を進めていたボキャブラリーの規格です。
いくつかのボキャブラリーに共通しますが、schema.orgでマークアップする際にはタイプ(型)とプロパティ(属性)を指定します。
- タイプ:「これに関するコンテンツだよ」の指定。
- プロパティ:タイプを説明する詳細項目の指定。タイプ別に設定できるプロパティは異なります。
記事ページのマークアップを例に挙げると、以下のようになります。
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Article",
"mainEntityOfPage": {
"@type": "WebPage",
"@id": "https://internet-connect.net/what-is-provider/"
},
"headline": "プロバイダとは?インターネット契約前に初心者が知っておくべき知識",
"image": "https://internet-connect.net/images/provider-net.jpg?width=1360",
"author": {
"@type": "Person",
"name": "山田太郎"
},
"publisher": {
"@type": "Organization",
"name": "株式会社A",
"logo": {
"@type": "ImageObject",
"url": "https://internet-connect.net/_nuxt/img/e29853a.png",
"width": 2,
"height": 1
}
},
"datePublished": "2019-07-01",
"dateModified": "2019-07-01"
}
</script>
このマークアップを引用して、タイプとプロパティを紹介していきます。
<script type="application/ld+json">
{
"@context": "https://schema.org",
まず、構造化データマークアップはボキャブラリーとシンタックスを指定するところから始まります。
このブロックでボキャブラリー:schema、シンタックス:JSON-LDであることを指定しています。
@type: "Article",
この部分では、このコンテンツのタイプは「記事(Article)」ですよ!とタイプ指定をしています。
image: {
@type: "ImageObject",
url: "https://internet-connect.net/images/provider-recommend.jpeg",
width: 696,
height: 522
},
また、上記の"@type: "ImageObject""では「画像」ですよ!とタイプを指定して、
urlやwidth、heightなどの画像タイプに付与できるプロパティを指定していっています。
前述のとおり、タイプによって指定できるプロパティは異なります。
このように、ボキャブラリーとシンタックスから言語の指定をして、その中でタイプ>プロパティをマークアップしていく、このフローで構造化データマークアップは完成します。
では、シンタックスにはどのようなものがあるのでしょうか?
詳しく説明していきます。
Googleがサポートしているシンタックス
グーグルがサポートしているシンタックスは主に以下の3つです。
- microdata
- RDFa
- JSON-LD
そして現在、グーグルが推奨しているのはJSON-LDです。
基本的にSEO対策を目的として構造化データマークアップをするならば、JSON-LDでマークアップしておくのが無難でしょう。
microdata
HTML5に独立した仕様で、HTML5でのみ用いることができます。
W3Cの勧告は2013年10月で止まっているため、RDFaやJSON-LDを選択したほうがよいかもしれません。
microdataの場合は、テキストを直接マークアップすることができます。
【span itemprop=""】というタグでマークアップしているのが、このmicrodataです。
RDFa
microdataと同様にテキストを直接マークアップできますが、
microdataが使えるHTML5に加えて、XHTMLなどより広い言語で使用することができます。
RDFaでは、【span property=""】というタグでマークアップをしていきます。
JSON-LD(推奨)
現在グーグルが推奨しているシンタックスです。
JSON-LDはmicrodataやRDFaとは異なり、表示されるテキストとは別でマークアップをする仕様になっています。
よって、ファイルサイズが多少なりとも大きくなってしまう、テキストの更新をした際にマークアップの内容を更新し忘れる危険がある、というデメリットがあります。
その一方で、マークアップ箇所が別で設けられているので、HTMLの記述はきれいなままで済みます。
そして何より、グーグルが推奨しているシンタックスなので、積極的に利用することをおすすめします![]()
2015年までJSON-JDはリッチスニペットには非対応でした。
しかし現在ではJSON-LDもリッチスニペットに対応しているため、安心して使用することができます。
ここまでで、構造化データの仕組みは理解できましたか?
では、構造化データマークアップをすれば、どんなリッチリザルトを出すことができるのでしょうか?
いろいろなリッチリザルト
このリッチリザルトにはいろんな種類があります。
たとえば、映画のレビュー。

(※2019年6月28日時点)
「ドラえもん のび太の月面探査記」の評価は★5つ中3.8と出ています。
これもリッチリザルトの一つです。
飲食店の価格帯
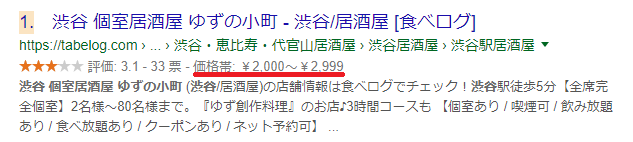
さりげないですが、飲食店の価格相場が表示されるのも、構造化データマークアップによるリッチスニペットの一つです。
【NEW!】FAQコンテンツ
また、2019年5月にグーグルからFAQという新しいリッチリザルトが公開されました。
さっそく引越し侍でマークアップしてみたところ、検索結果は以下のようになりました。
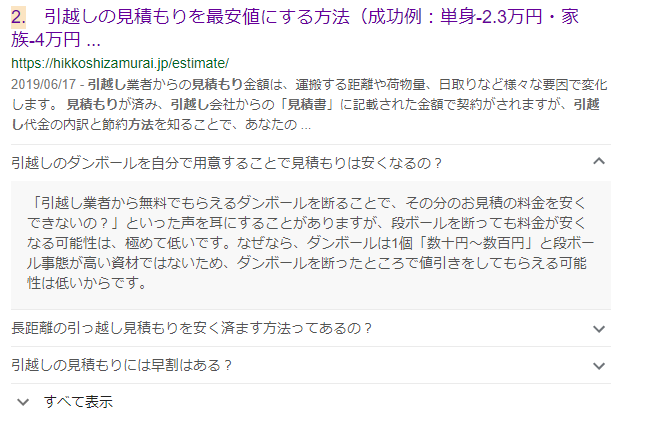
検索結果上で一問一答のようにFAQが表示されるので、サイトにアクセスすることなく、ユーザーの疑問に答えることができます。
しかし、このマークアップではユーザーのニーズはサイトへのアクセスなしで満たされる可能性があります。
その結果、サイトへの流入がむしろ減ってしまったという調査結果がアメリカでは発表されているようです![]()
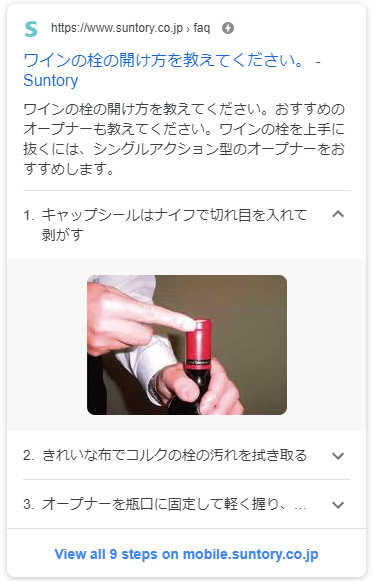
【日本未上陸】How-toコンテンツ
日本ではまだリリースされておりませんが、英語版のGoogleではスマホ表示の際にHow-toマークアップが表示されるようになりました。
「ワイン 開け方」で検索した際のリッチリザルトはこちらです。
今後もGoogleは検索結果をリッチ化させるため、そしてサイト内のコンテンツをより正確に理解してセマンティックWebを実現させるために、構造化データマークアップを推進していくことでしょう。
今回は構造化データマークアップを題材に紹介してきました。
SEO界隈はコンテンツやリンク設計だけでなく、構造化データやJavaScriptの読み取りなど、いろいろな分野で新しいニュースにあふれています。
それもSEO担当として、飽きずに仕事ができる醍醐味でもあるんです![]()
「SEO担当の仕事にもっと触れてみたい」と思った方!
エイチーム引越し侍では現在様々なサイトを運営しています。
そして、構造化データなどの新しいニュースを深く読み取り、施策に落とし込み、
実際の検索結果に影響が出るかどうかの検証を日々行っています。
▼運営サイト一例
- 引っ越し見積もりサイト:引越し侍
- インターネット・プロバイダ比較サイト:Proval
- シロアリ駆除・工事・修理のプロ探し:ファインドプロ
- エアコン取り付け工事サイト:エアコンサポートセンター
- エアコン通販サイト:エアコンお買い得ドットコム
「SEOの研究をしたい!」
「複数のサイトのSEOを担当したい!」
そんな方は、ぜひエイチーム引越し侍の採用サイトにご連絡ください。
皆さんのご連絡をお待ちしております!!
採用サイトはこちら