1. 概要
この記事の内容
セッションログデータを対象にしたDeep Learningベースのレコメンド手法を提案した以下の論文を読んで内容をまとめ,考察を行った.
論文を読んだ背景と目的
- クリックなどといったWeb行動ログを用いたユーザー行動の予測について,一般的な手法を把握したい.
- ありふれた設定なので,研究例や事例が多くあるものと考えられる.
- 上記の設定において,現在の主流はDeep Learning(特にRecurrent Neural Network)を用いた手法であることがわかっている.
- session-based recommendationと総称される
- その中でも一連の研究の流れの発端である上述のB. Hidasi et al.(2015)について,問題設定・前提条件・課題・その後の発展を整理したい.それにより,
- そこから派生した手法を調べる際のキャッチアップを容易にしたい
- 今後調査が必要そうな項目を洗い出したい
- 複数の手法を比較・考察する際のベースラインとしたい
論文の要約
- 長期にわたるユーザー履歴が取得困難な状況を想定して,1セッション分のデータから精度良くレコメンドを行いたい
- Recurrent Neural Network(RNN)をレコメンドの問題設定向けに改良を施した
- Gated Rucurrent Unit (GRU, Cho et al.(2014)) を中心としたネットワーク
- 損失関数は,レコメンドで用いられるランキング損失をベースに設定した
- 2種類のデータセットにおいて,既存手法を大きく上回る精度が得られた(最大で+30.5%)
- データセット: RecSys Challenge 2015(ECサイトクリック履歴), 動画サイト視聴履歴
- 比較手法: Item-KNNほか
- 比較指標: Recall@20, Mean Reciprocal Rank@20 (どちらも一般的なレコメンドの評価指標)
おことわり
- 本文中に掲載した図は,断りのない限り論文中から引用した.
- モデルや評価指標の詳細について本記事では触れない.
2. 論文の背景
-
以下のようなケースを念頭に,1session分の短期の行動履歴から,ユーザー同定をせずにレコメンドを行いたい
- ユーザーIDの特定が困難なケース
- 小規模のECサイトや,ニュースサイトなど
- ユーザー同定ができたとしても,セキュリティの制約から避ける傾向にある
- 長期間にわたるユーザー行動履歴の取得が困難なケース
- 小さいサイトでは1ユーザーあたりのセッション数が少ない
- 同一ユーザーでも異なるセッションを独立に扱う必要のあるケース
- ドメインによってはセッションが切り替わると行動が大きく変わってしまう場合がある
- 例)ECサイトにおける検討段階と購買段階
- ユーザーIDの特定が困難なケース
-
従来手法では行動履歴を反映させたレコメンドができていない
- 従来手法:item同士の類似度や共起性,item間の遷移率などに基づく
- 多くの場合,直近の行動のみしか着目していない
- 行動の順番についても考慮がなされていない
-
一方,近年Deep Learningが様々な分野で成果を上げている.
- 特に自然言語などの系列データに対しては,RNNとその派生手法が効果的であることがわかっている.
- したがって,クリック履歴データに対してもRNNの応用が期待できる
3. 論文の目的
以下に挙げる問題設定に対して,後述のRecurrent Nueral Network(RNN)を応用した手法で,sessionデータに基づくレコメンド性能が従来手法に比べて改善することを検証する.
問題設定
セッションごとに区切られたイベント実行ログの系列が与えられたとする.
あるイベントが実行された時,次のイベントで選択されるアイテム(商品やページ)を予測する.
手法の概要
Figure 1に示すような,Gated Recurrent Unit(GRU)を中心としたネットワークアーキテクチャを採用した:
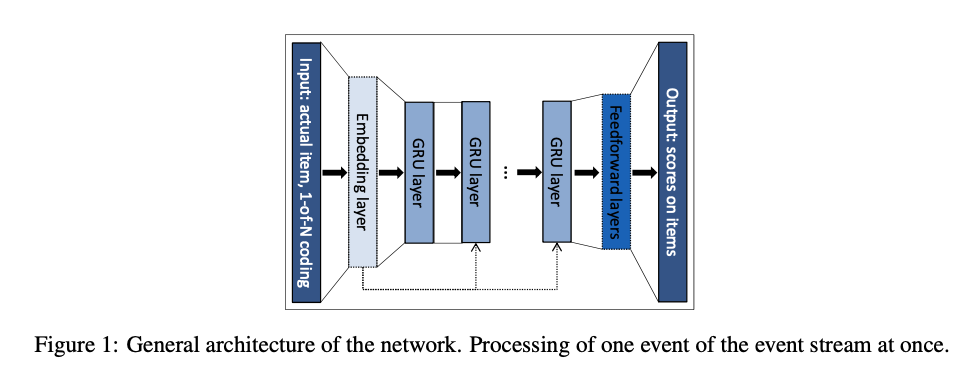
- GRU: ゲート付きRNNと呼ばれるモデルの一種.同じくゲート付きRNNとして代表的なLSTM(F.A.Gers et al. (1999))と比べて,パラメータ数が少なく計算時間が短くて済む.
- 入力データ:アイテムを1-of-N codingしたベクトル
- 長さは全アイテム数,入力アイテムを0-1で表現する
- 出力:各アイテムに対する予測スコア
<参考>GRUについて
- Cho, Kyunghyun, et al. "On the properties of neural machine translation: Encoder-decoder approaches." arXiv preprint arXiv:1409.1259 (2014).
- 斎藤 康毅,ゼロから作るDeep Learning ❷ ――自然言語処理編,オライリー・ジャパン(2018)
4. 論文の検証内容
- 2種類の評価用データセット,2種類の評価指標を用意し,それぞれ従来手法を上回るかを見た.
- モデルの設定についても,合計6パターン作成し比較を行った.
評価用データセット
- RSC15: RecSys Challenge 2015
- レコメンドアルゴリズムの評価の際によく用いられるデータセットのひとつ.
- 内容:ECサイトにおける商品ページのクリックログ(6ヶ月分)
- データ量:
- セッション数:7,966,257(train) + 15,324(test)
- イベント数:31,637,239(train) + 71,222(test)
- アイテム(商品ページ)数:37,483

※上記のキャプションは当記事著者が作成した.
※後述の前処理によりデータを削っているため,データフレームの行数やセッション数は,上に記したデータ量と一致しない.
- VIDEO: 非公開データセット(多分)
- YouTube-likeな動画配信プラットフォームの視聴データ
- 内容:視聴コンテンツログ(2ヶ月分)
- データ量
- セッション数:300万程度
- イベント数:1300万程度
- アイテム(動画コンテンツ)数:330,000程度
評価指標
以下の,レコメンドの評価における代表的な指標を用いた.
いずれも,全アイテムに対して予測スコアなどを元に順位を振り,上位20件のアイテムを元に評価を行う.
- Recall@20
- 全テストデータ中,実際に選択されたアイテムが予測アイテム上位20件に含まれていた割合
- MeanReciprocalRank(MRR)@20
- 実際に選択されたアイテムの予測順位の逆数を取り,全テストデータで平均値をとる.
- ただし,選択されたアイテムが予測上位20件に含まれていなければ0とする
- Recall@20と異なり,予測順位についても評価の対象になる
- 実際に選択されたアイテムの予測順位の逆数を取り,全テストデータで平均値をとる.
比較手法
- Item-KNN
- アイテムの類似度ベースの手法
- 直近に選択されたアイテムと予測対象アイテムについて,同一セッション内で両方出現した回数を個別に出現した回数で割り,予測スコアとして用いる.
これ以外にも典型的な手法を3種類用意したが,いずれも今回の問題設定ではItem-KNNを下回った(後述).
モデルの設定パターン
- ハイパーパラメータ(2パターン)
- 層の大きさ(GRUのUnit数): 100 or 1000
- 損失関数(3パターン)
- pairwise ranking loss: 正解データの予測スコアが他のアイテムの予測スコアより高いほど良いモデルとする
- BPR ... 後述のBPR-MFで提案された損失関数
- TOP1 ... BPRと似ているが,正則化項を加え突出して予測スコアの高いアイテムが現れにくくしたもの,と理解している.
- 分類損失: レコメンドではなく分類問題として扱う
- Cross-entropy
- pairwise ranking loss: 正解データの予測スコアが他のアイテムの予測スコアより高いほど良いモデルとする
モデル学習・予測方法について備考
- テストデータ中の各イベントを対象に,次に選択されるアイテムを予測し評価を行った
- セッション末のイベントは対象外(正解データが作れないため)
- 訓練データ・テストデータは日付で分けた
- RSC15: はじめの6ヶ月を訓練データ,その翌日をテストデータ
- VIDEO: 最終日以外を訓練データ,最終日をテストデータ
- 前処理の際にデータを除外している
- イベント数1のセッションは除外
- 訓練データに含まれていなかったアイテムは,テストデータから除外
- VIDEOについては,あまりに長いセッションは除外(Botの可能性がある)
- VIDEOデータセットはアイテム数が多いため,予測スコア算出対象アイテムを,出現回数が全体の上位30,000件のものに絞った
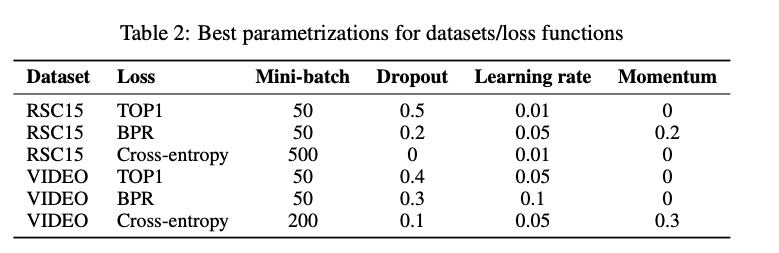
- GRUのUnit数以外のハイパーパラメータは事前にチューニングした(下記Table 2)
- 学習データ内でvalidとevalに分けて,ランダムサーチした
- 対象データセット,損失関数ごとに個別にチューニングを行っている
- GRU層の数は,最も性能が良かった1層で固定した
5. 論文の結果
ベースライン
今回のデータセットを用いて,上述のItem-KNNを含めて4種類の手法についてベースラインとなる評価値を算出した.いずれの場合もItem-KNNが最良だった(下記Table 1参照).
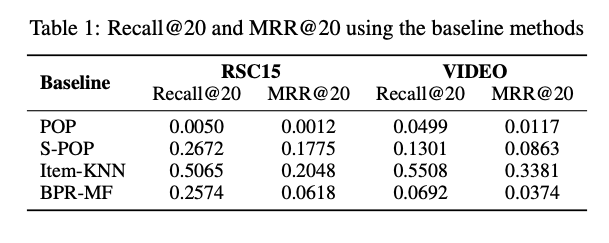
なお,Item-KNN以外に用いた手法の概要は以下の通りである.
- POP: popularity predictor
- 全データ中,出現回数が多いアイテムを順にレコメンドする
- 全ユーザーに対して同じランキングを見せる,最も素朴な手法.ベースラインとしてよく用いられる.
- S-POP: the most popular items of the current session
- 各セッション内で,出現回数の多いアイテムを順にレコメンドする
- リピーターが多いケースで有効な手法
- BPR-MF: Rendle, Steffen, et al. "BPR: Bayesian personalized ranking from implicit feedback." arXiv preprint arXiv:1205.2618 (2012).
- Matrix Factorizationという典型的なレコメンド手法の一つ
- 各セッション内の各アイテム合計出現回数を入力特徴量としている
以降ではItem-KNNのみ比較の対象として扱う.
提案手法の結果
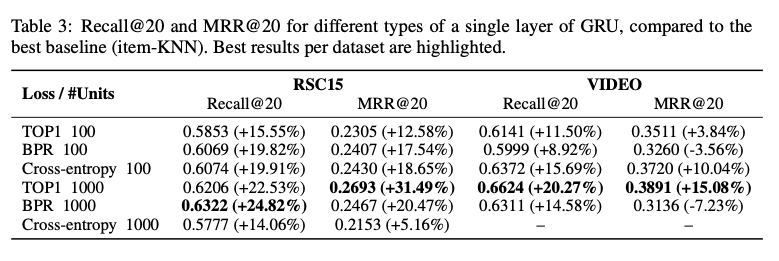
※VIDEOにおいてUnit数1000,cross-entropyで学習を行った場合,結果が数値的に不安定になったため,結果から除外した.
- 一部の条件を除き,今回のGRUベースの手法はitem-KNNを上回る性能を示した.
- 例外:VIDEOデータセットにおいて,損失関数にBPR,評価指標にMRR@20を採用したケース
6. 論文の結論
- 全体を通して,今回のGRUベースの手法は既存手法を大きく上回る性能を持つことが示された.
- 学習時の損失関数は,TOP1を用いるのが妥当であろう.
- BPRはデータ・評価方法によっては既存手法を下回る
- cross-entropyはUnit数を増やすと数値的に不安定になる
以下,当記事著者の所感・考察
良さそうだと思った点
- 1セッション分の短いデータから,ユーザーの特定をせずにレコメンドを行える
- ただし,1セッション分がどれだけ短くていいかは別途確認が必要.
- 行動順序や周期性も含めた行動パターンをもとに予測が可能かもしれない
- 一方で,今回どのような要因が性能向上に寄与したのかはよくわからないので,RNN自体を理解したうえで考察したい.
今回の手法ではできないこと
今回の問題設定・前提をもとに,論文手法を直接適用する際には以下のような制約があると考えている:
- セッションを跨いだ過去の履歴は利用できない
- 例(ゲームアプリ):ユーザーの熟練度に応じて推薦内容を変化させることはできない
- 直後に発生するイベントしか予測できない
- 直後よりあとのイベントは予測対象外(指定期間内に購入,など)
- 発生までの時間がわからない(数分後なのか,数時間後なのか)
- 予測対象アイテム以外の予測はできない
- 複数の行動を対象にした予測はできない(例:複数回購入の予測,お気に入り追加後に購入するかの予測)
その後の展開
- セッションを跨いだ履歴の利用に対しては,ユーザー同定が可能なケースへの拡張が行われている:
- 今回用いられた損失関数TOP1, BPRについては,のちの研究で同著者らにより勾配消失問題が指摘され,改良がなされている
- Hidasi, Balázs, and Alexandros Karatzoglou. "Recurrent neural networks with top-k gains for session-based recommendations." Proceedings of the 27th ACM International Conference on Information and Knowledge Management. 2018.
- ... 損失関数を工夫することで今回の手法を分類・回帰問題に拡張することは可能と考えられるが,上記からすると注意が必要かもしれない.
その他,近年の自然言語処理技術の発展も随時取り入れられているようであり,今後の展開をもう少し追って調査したい:
- 例:Attention, Transformer
- Attentionについては,以下のようなものがある
- Li, Jing, et al. "Neural attentive session-based recommendation." Proceedings of the 2017 ACM on Conference on Information and Knowledge Management. 2017.
- Guo, Long, et al. "Buying or browsing?: predicting real-time purchasing intent using attention-based deep network with multiple behavior." Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2019.
- Transformerについては,今回の問題設定と似た現在開催中のkaggleのコンペ(Riiid)でnotebookが複数公開されている
- Attentionについては,以下のようなものがある
今後の調査で参考になりそうな資料
実装コード
-
論文著者によるオリジナルの実装コード(Theano使用)
- この他にも,GitHub上に多くの実装が公開されている(Keras, PyTorchなど)