CouchbaseServerを触ってみよう
5章 Couchbaseの横断検索機能を利用してみよう
この記事は、SoftwareDesign 2016年12月号(以下、SD誌)のKVS特集中のCouchbaseServer紹介記事に関する補足記事となります。
CouchbaseServerの簡単な紹介から、実際に手を動かして利用してみるところまでを対象としています。
Couchbaseサーバに関する公式のドキュメントは大量にあるのですが、バージョンが古いものも大量に残っていたり、リンク切れなどがあるため、まずざっくり触ってみたいというときに参考にして頂きたいと思います。
この記事はCouchbase4.5を元に記載しています。
横断検索を利用
KVSとして使っているだけではドキュメントの中身を利用した検索が出来ませんが、View機能やN1QL機能を利用することでドキュメントの中身を利用した検索が可能となります。
ここでは、先ほどの例で入力したu_timestampを利用して更新時間で絞り込んでドキュメントを取得することを試してみます。
ダミーデータの登録
以下のスクリプトで、10万件のDUMMY_DOC1ドキュメントとDUMMY_DOC2ドキュメントを投入します。
それぞれ、doctypeとu_timestampを含むJSONドキュメントとして登録されます。
vi cb_mk_dummy.php
<?php
define("DUMMY_NUM", 100000);
define("BUCKET_NAME", "sample");
define("BUCKET_PASSWD", "password");
// Connect to Couchbase
$cluster = new CouchbaseCluster("localhost");
$bucket = $cluster->openBucket(BUCKET_NAME, BUCKET_PASSWD);
// Store DUMMY_DOC1 docments
for($i=0; $i<DUMMY_NUM; $i++){
$bucket->upsert(
"D1:${i}",
[
"doctype" => "DUMMY_DOC1",
"user_id" => ${i},
"email" => "dummy_user_${i}@***.**",
"sex" => rand(1,2),
"u_timestamp" => time()-rand(1, 86400*365) // 過去1年間の中でランダム
]
);
}
echo "Add ".DUMMY_NUM." DUMMY_DOC1 docments.\n";
// Store DUMMY_DOC2 docments
for($i=0; $i<DUMMY_NUM; $i++){
$bucket->upsert(
"D2:${i}",
[
"doctype" => "DUMMY_DOC2",
"doc_id" => ${i},
"u_timestamp" => time()-rand(1, 86400*365)
]
);
}
echo "Add ".DUMMY_NUM." DUMMY_DOC2 docments.\n";
?>
スクリプト実行結果
time php cb_mk_dummy.php
Add 100000 DUMMY_DOC1 docments.
Add 100000 DUMMY_DOC2 docments.
real 0m22.385s
user 0m4.892s
sys 0m2.644s
1秒あたり1000ドキュメントしか挿入できていないようですが、これはシングルスレッドでの操作であるためであり、マルチスレッドでのWebサービスとして動作させている場合などはこの数値を大きく超えた速度での操作が可能です。
Viewを利用した検索
ここでは、Viewを利用した検索を行ってみます。
全体の流れは以下のとおりです。
- Development Viewの追加
- Development Viewを利用したIndexの確認
- Production Viewにpublish
- Poduction Viewを利用した検索の実施
Viewの新規作成
Viewを利用した検索を行うためには、まずバケットに対してViewを追加する必要があります。
以下の方法で、doctypeとu_datetimeに対する複合Indexを作成します。
Development Viewの追加
Production Viewを作る前に、DevelopmentViewを作成する必要があります。
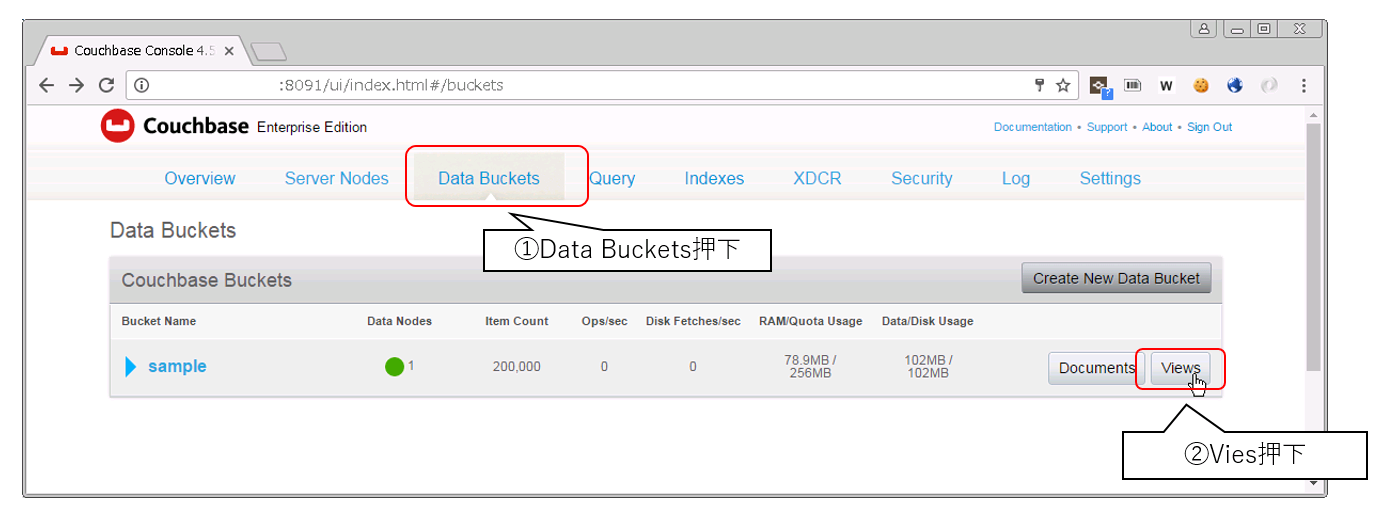
- 管理画面にて、対象のバケットの横の[Views]ボタンを押下します。
-
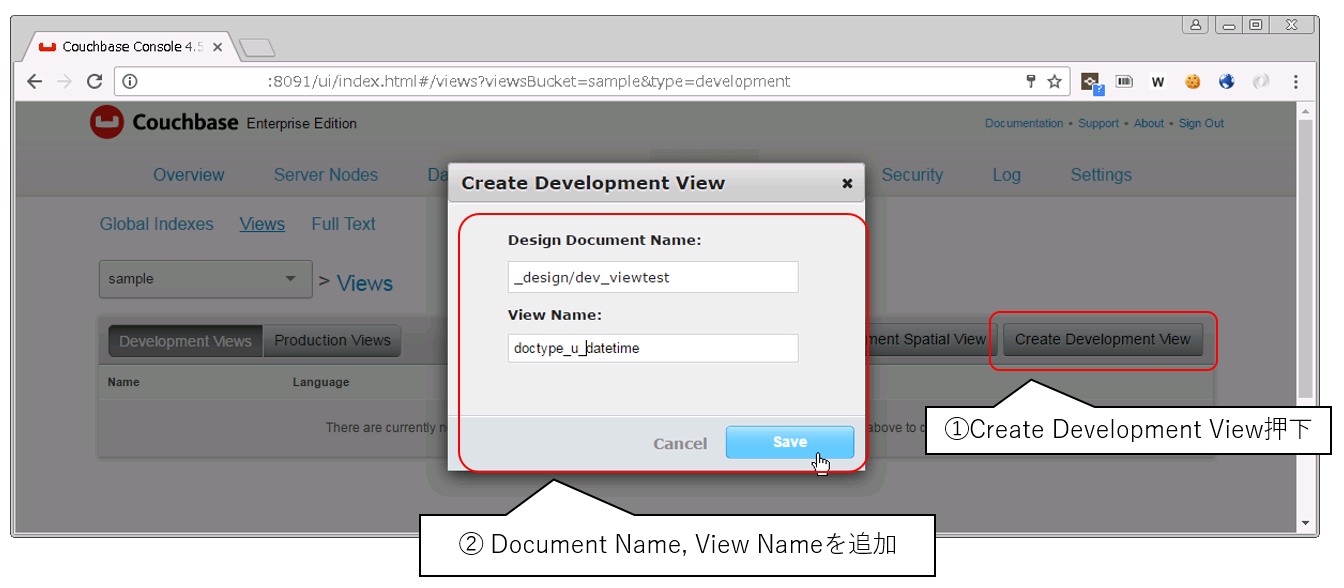
次の画面では、[Create Development View]ボタンを押下して下さい。
-
Design Document Name : _design/dev_viewtest と入力
-
View Name : doctype_u_datetimeと入力
-
次の画面で[Add View]押下
-
VIEW CODEの下のmap部分に以下のJava Script入力し、[Save]ボタンを押下します。
/*
以下の複合KeyおよびValueを持つIndexを作成します。
Key : ドキュメント中のdoctypeの値とu_timestampの値を":"で連結した文字列
Value : ドキュメントのKey
*/function (doc, meta) {
index_key = doc.doctype + ":" + doc.u_timestamp;
index_value = meta.id;
emit(index_key, index_value);
}
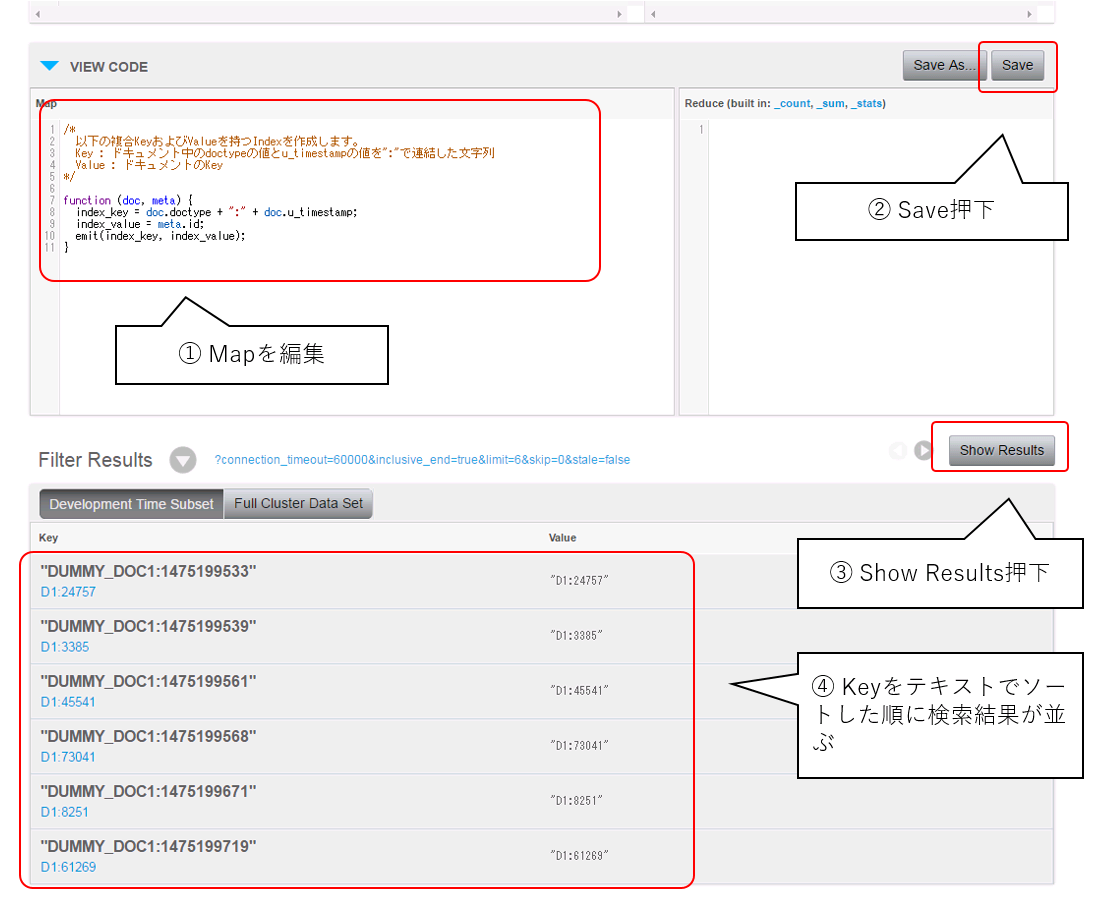
作成したkeyの値でソートされたインデックスが表示されます。
今回のダミーデータでは10万件のデータを1時間の範囲に作成しましたので、同一のKeyをもつIndexが複数作られる筈ですが、それが観測されません。これは、Development Time Subsetによる検索はバケットのデータ全体を対象としておらず、一部のサンプルだけを利用しているためです。
そこで、Full Cluster Data Setを選択することで検索対象を全体とします。
今度は最初に全体を走査してIndexを再構築しますので暫く時間がかかりますが、バケット全体からの検索結果を取得することが出来ました。
※今回はvalue部分をドキュメントの主キーとしましたが、この部分を配列構造とすることも可能です。
ProductionViewにPublish
一通りDevelopment Viewの動作を確認したあとは、 _design/dev_viewtest に対して、[Publish]操作を行うことでProduction Viewに昇格することが出来ます。
Production ViewではIndexのMapの編集等はできなくなります。
Poduction Viewを利用した検索の実施
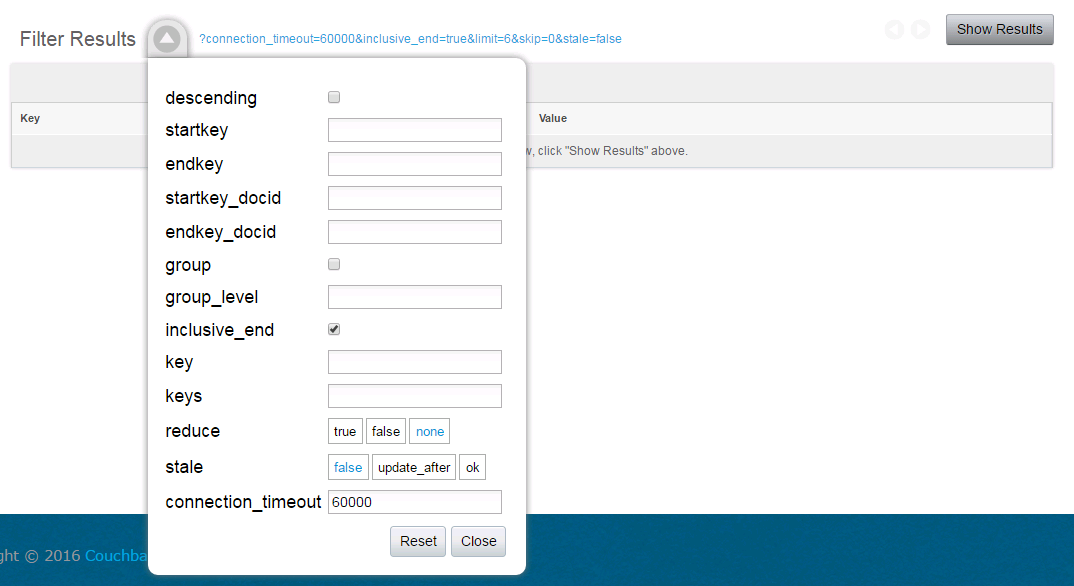
管理コンソールから、Production ViewのFilter Resultsの横に折りたたまれたオプションを展開して検索オプションを指定することが出来ます。
例)
DUMMY_DOC2で、unix_timestampとして1475200000以降に更新されたドキュメントの取得をする場合、
startkey部分に"DUMMY_DOC2:1475200000"を入力してから、[Show Results]を押下してみて下さい。
また、endkey部分も指定することで、ドキュメントの前方一致によるlike検索のようなことを行うことも可能です。
こちらはFilter Resultsの横にあるリンクを押下することで、httpのGETメソッドでJSONとして取得をすることも可能です。
http://[Global IP]:8092/sample/_design/viewtest/_view/doctype_u_datetime?connection_timeout=60000&inclusive_end=true&limit=6&skip=0&stale=false
※ただし、[Global IP]とした部分にはデフォルトではローカルIPが入ってしまいますので、その部分を書き換えたうえで、8092ポートを開放して下さい。
スクリプトを利用した検索の実施
また、各言語用のSDKを用いてスクリプト中からデータを取得することも可能です。
vi view_example.php
<?php
define("BUCKET_NAME", "sample");
define("BUCKET_PASSWD", "password");
define("DESIGN_DOCUMENT_NAME", "viewtest");
define("VIEW_NAME", "doctype_u_datetime");
// Connect to Couchbase
$cluster = new CouchbaseCluster("localhost");
$bucket = $cluster->openBucket(BUCKET_NAME, BUCKET_PASSWD);
echo "Reversing dummy docs\n";
$custom = ["startkey" => '"DUMMY_DOC2:1475200000"'];
$query = CouchbaseViewQuery::from(DESIGN_DOCUMENT_NAME, VIEW_NAME)->limit(4)->custom($custom);
$results = $bucket->query($query);
print_r($results);
?>
実行結果は以下のとおりです。
$ php view_example.php
Reversing dummy docs.
stdClass Object
(
[total_rows] => 200000
[rows] => Array
(
[0] => stdClass Object
(
[id] => D2:1173
[key] => DUMMY_DOC2:1475200000
[value] => D2:1173
)
[1] => stdClass Object
(
[id] => D2:13636
[key] => DUMMY_DOC2:1475200000
[value] => D2:13636
)
[2] => stdClass Object
(
[id] => D2:19507
[key] => DUMMY_DOC2:1475200000
[value] => D2:19507
)
[3] => stdClass Object
(
[id] => D2:20937
[key] => DUMMY_DOC2:1475200000
[value] => D2:20937
)
)
)
Viewを利用する際に注意すること
特にlimitを指定してページングしながらデータを取得する際にはまりやすいのですが、Viewの利用時以下のことに注意する必要があります。
- startkeyの指定部分は明示的に文字列であることを示すために"ダブルクオーテーション"で囲わなければエラーになる
- Indexの更新タイミングに気を付ける必要がある。(ドキュメントの中身と一致しない可能性がでる)
- ページングの途中でIndexを更新すると既に取得済みのデータが取れたり、逆にデータが飛んだりするリスクがあるため、Index更新をスクリプトで管理する必要がある
- Indexが更新されない限りは検索結果の順序は保証されるが、複数のIndexにおいてKeyが同一になるケースがある
- skipをSQLにおけるoffsetの代わりに指定すると、skip行数が大きくなったときに線形に時間がかかるようになる
- ページングのため、startkey_docid(検索結果の中に該当ドキュメントが現れるまでスキップするオプション)を指定するときには、そのdocidが含まれる様にstartkeyも変更する必要がある。
とはいえ、後述するN1QLよりも安定した部分もあり、また高速なアクセスが可能なのはメリットになります。
N1QLを利用した検索
Couchbase4.0以降に正式にサポートされたN1QL機能を利用してみましょう。
CouchbaseはまさにNoSQL(Not Only SQL)で、KVS機能だけでなく、SQLも利用可能です。
当初はcbqというコマンドラインツールを利用したアクセスをしていたのですが、最新版のCouchbase4.5では管理コンソールからクエリの実行が可能ですので気軽に試すことが出来ます。
※この機能を利用するためにはCouchbaseインストール後の最初に管理コンソールを立ち上げたときに、IndexサービスとQueryサービスを有効にする必要があります。
Indexの作成
まずは、Queryタグを選択、その後適当なクエリを実行してみましょう。
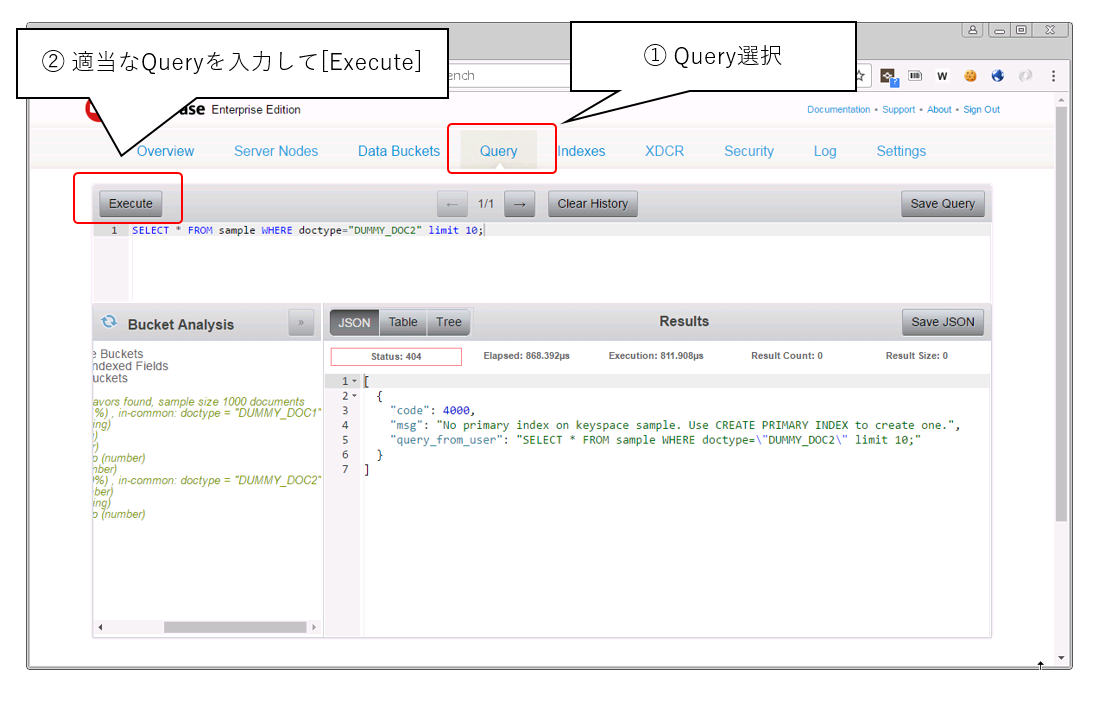
SELECT * FROM sample WHERE doctype="DUMMY_DOC2" limit 10;
すると、
[
{
"code": 4000,
"msg": "No primary index on keyspace sample. Use CREATE PRIMARY INDEX to create one.",
"query_from_user": "SELECT * FROM sample WHERE doctype=\"DUMMY_DOC2\" limit 10;"
}
]
と返答されてしまいました。
N1QLを利用するためにはまず最初にPRIMARY INDEXを一つ作成しなければなりません。
CREATE PRIMARY INDEX;
をExecuteすると、数秒間
{"status": "Executing Statement"}
と表示されたあとで、
{
"results": [],
"metrics": {
"elapsedTime": "20.295733492s",
"executionTime": "20.295685846s",
"resultCount": 0,
"resultSize": 0
}
}
と表示され、PrimaryIndexの作成がされます。
その上でもう一度以下のクエリを実行してみます。
SELECT * FROM sample WHERE doctype="DUMMY_DOC2" limit 10;
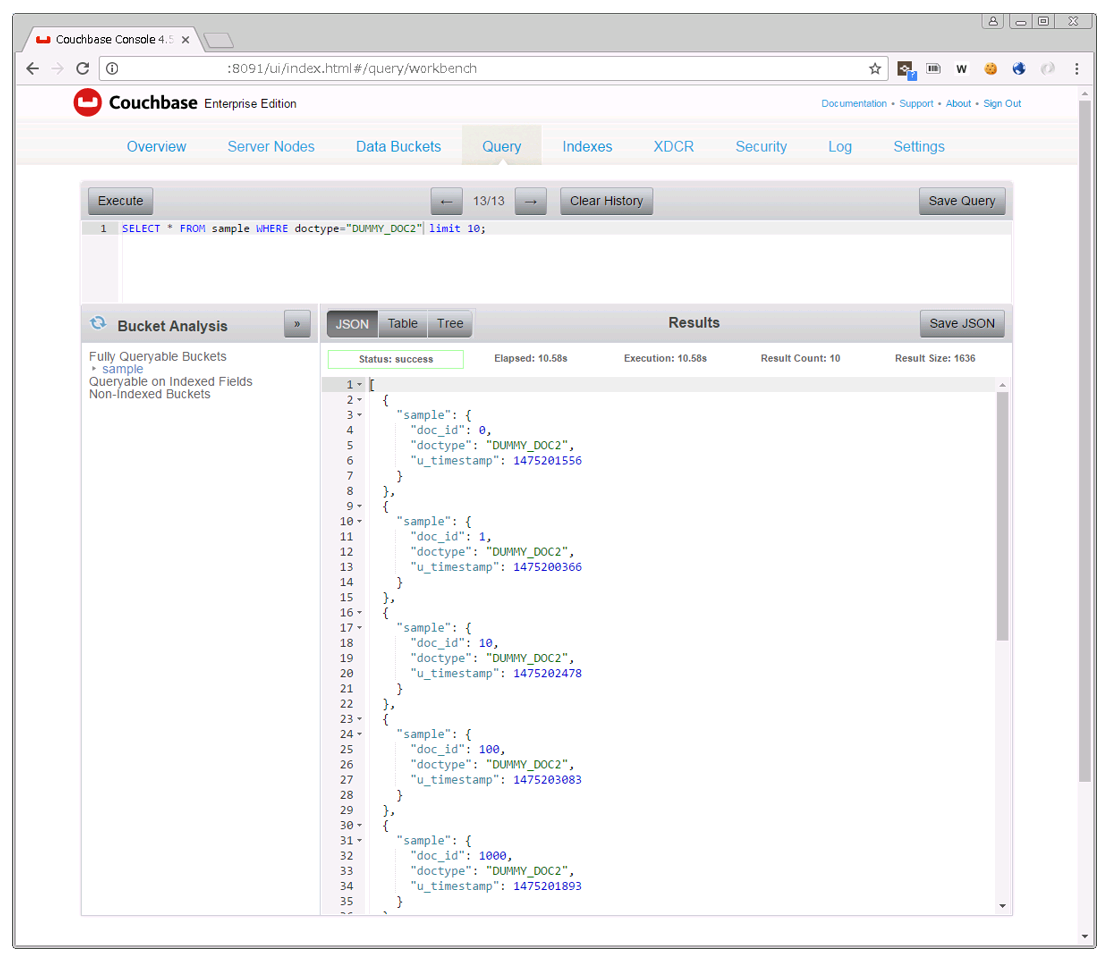
今度は結果の取得は出来たのですが、たった20万件のデータからの取得に10秒の時間がかかっています。これは、先ほど作成したPRIMARY INDEXだけではdoctypeに対するIndex検索が出来ないためです。以下のクエリでIndexを作成し、再実行します。
CREATE INDEX CREATE INDEX doctype_u_timestamp ON `sample`(doctype, u_timestamp);
22秒ほどでIndexが追加されました。
再度同じクエリを実行します。
SELECT * FROM sample WHERE doctype="DUMMY_DOC2" limit 10;
今度はIndexが適切に使われ、2.55msecで実行が完了しました。
また、複合Indexを張ったため、Viewを利用した時と同様に、u_timestampも指定した検索が可能です。こちらの場合も22msecでの実行が可能です。
SELECT * FROM sample WHERE doctype="DUMMY_DOC2" and u_timestamp > 1475200000 limit 10;
また、通常のSQLのようにExplainを利用するとIndexの使われ方もわかります。
indexの使われ方に少し癖があるのでExplainをしながらクエリチューニングをすすめて下さい。
EXPLAIN SELECT * FROM sample WHERE doctype="DUMMY_DOC2" and u_timestamp > 1475200000 limit 10;
[
{
"plan": {
"#operator": "Sequence",
"~children": [
{
"#operator": "Sequence",
"~children": [
{
"#operator": "IndexScan",
"index": "doctype_u_timestamp",
"index_id": "3496c3078e775047",
"keyspace": "sample",
"namespace": "default",
"spans": [
{
"Range": {
"High": [
"successor(\"DUMMY_DOC2\")"
],
"Inclusion": 0,
"Low": [
"\"DUMMY_DOC2\"",
"1475200000"
]
}
}
],
"using": "gsi"
},
{
"#operator": "Parallel",
"~child": {
"#operator": "Sequence",
"~children": [
{
"#operator": "Fetch",
"keyspace": "sample",
"namespace": "default"
},
{
"#operator": "Filter",
"condition": "(((`sample`.`doctype`) = \"DUMMY_DOC2\") and (1475200000 < (`sample`.`u_timestamp`)))"
},
{
"#operator": "InitialProject",
"result_terms": [
{
"expr": "self",
"star": true
}
]
},
{
"#operator": "FinalProject"
}
]
}
}
]
},
{
"#operator": "Limit",
"expr": "10"
}
]
},
"text": "SELECT * FROM sample WHERE doctype=\"DUMMY_DOC2\" and u_timestamp > 1475200000 limit 10;"
}
]
スクリプトを利用した検索の実施
勿論、Viewを利用したときと同様にスクリプトからの利用も可能です。
vi n1ql_example.php
<?php
define("BUCKET_NAME", "sample");
define("BUCKET_PASSWD", "password");
// Connect to Couchbase
$cluster = new CouchbaseCluster("localhost");
$bucket = $cluster->openBucket(BUCKET_NAME, BUCKET_PASSWD);
echo "Reversing by n1ql query\n";
$query = CouchbaseN1qlQuery::fromString('SELECT * FROM sample WHERE doctype="DUMMY_DOC2" and u_timestamp > 1475200000 limit 2');
$results = $bucket->query($query);
print_r($results);
?>
実行結果
$ php n1ql_example.php
Reversing by n1ql query
stdClass Object
(
[rows] => Array
(
[0] => stdClass Object
(
[sample] => stdClass Object
(
[doc_id] => 11212
[doctype] => DUMMY_DOC2
[u_timestamp] => 1475200001
)
)
[1] => stdClass Object
(
[sample] => stdClass Object
(
[doc_id] => 18597
[doctype] => DUMMY_DOC2
[u_timestamp] => 1475200001
)
)
)
[status] => success
[metrics] => Array
(
[elapsedTime] => 72.375525ms
[executionTime] => 72.308689ms
[resultCount] => 2
[resultSize] => 330
)
)
select * としただけでは、ドキュメントの主キーは取得できないことに注意して下さい。
ドキュメントの主キーを取得したい場合は、
SELECT meta().id, * FROM sample
とする必要があります。
また、この場合もsample部分の階層が一つずれてしまいます。MySQL等と同じように結果の取得をしたい場合には
SELECT meta().id, sample.* FROM sample
として下さい。
その他、N1QLではJOINを使ったクエリの実行や、更新クエリを用いて複数のドキュメントを一度に変更することも可能です。
N1QLにはかなりの癖がありますが、Couchbaseでは下記のチュートリアルサイトを準備しています。こちらのサイトから、実際にN1QLのクエリを発行しながらN1QLで何が出来るのかの体験などもしていただきたいと思います。
N1QLを利用する際に注意すること
一方でN1QLはまだ発展途上の機能である部分もあるため、特にデータ量が多い環境での利用には充分な検証が必要です。
- Indexが作成されていない検索は非常に遅く、タイムアウトすることが多い
- Indexを追加すると追加されたIndexの数に応じて物理メモリを大量に要求する
- Indexの更新が非同期であり、取得した結果が最新のドキュメント内容とは一致しないことがある
- Index更新タイミングの制御が難しい
- (当然ながら)トランザクション操作を利用できない
最後に
足早にCouchbaseの紹介をしましたが、導入に関しては非常に簡単で比較的気軽に試すことが出来る製品です。
今回はPHPのサンプルを紹介いたしましたが、各種言語用のSDKが揃っており、Couchbase ならではの機能View機能の利用、N1QLを利用したクエリの実行が可能です。
まずは試して頂いた上で製品としての強力さを体験して頂きたいと思います。