はじめに
Github、使っていますか?
私のチームはエンプラプロジェクトですが、Githubを使用しています。もちろんIssueでタスク管理しています。
「IssueをExcelで管理したいんだけどできない!?」
と、プロジェクトマネージャーから言われたので、今回実装しました。
いつの時代もExcelは頼りになりますよね。(ちょい皮肉)
ただ、JSON→CSV→Excel化するのでは時代の逆戻りを後押ししてしまうので、"Google BigQuery" で解析できるようにしました。
イメージ
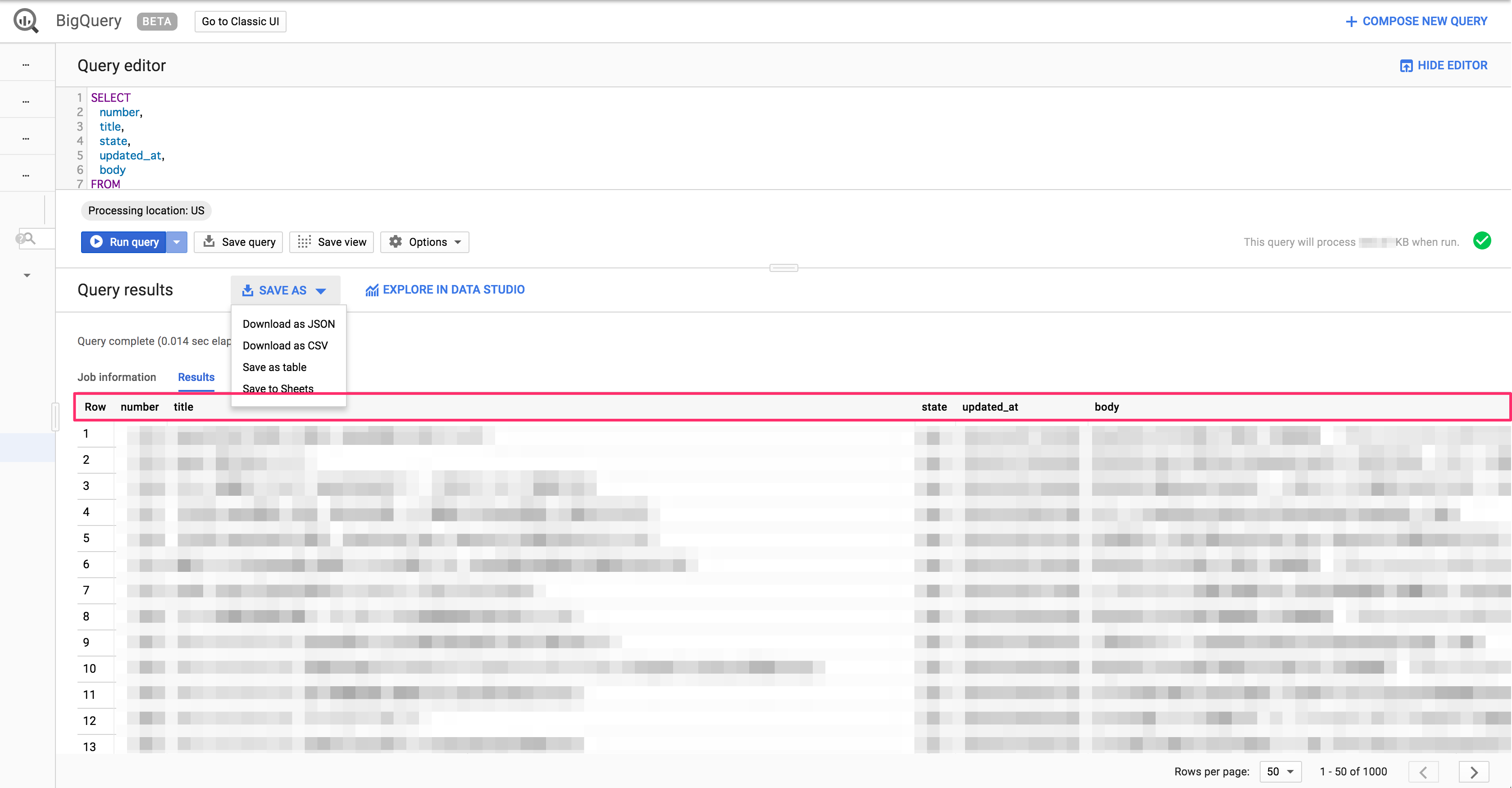
やること
- Github APIを用いて、Issue一覧をJSONでExport
- ExportしたJSONをBigQueryに取り込む
- あとは必要な情報だけクエリを書いて抽出して、"Datastudio" でも "スプレッドシート" でも "Excel" 好きに扱えます。
- Excel上でではなく、クエリで分析できるのは嬉しいですね!
1. Github APIを用いて、Issue一覧をJSONでExport
1.1 Github APIのTOKEN発行
まずは、Github APIを使用するために以下のcurlでTOKENを発行します
curl -u 'GITHUB_USERNAME' -d '{"scopes":["repo"],"note":"issue_export"}' https://api.github.com/authorizations
解説
-
GITHUB_USERNAME: 自分のアカウント名を設定してください
$curl -u 'GITHUB_USERNAME' -d '{"scopes":["repo"],"note":"issue_export"}' https://api.github.com/authorizations
Enter host password for user 'GITHUB_USERNAME':
{
"app": {
"name": "Help example (API)",
"url": "http://developer.github.com/v3/oauth/#oauth-authorizations-api"
},
"scopes": [
"repo"
],
"created_at": "20xx-xx-xxTxx:xx:Z",
"note_url": null,
"note": "issue_export",
"token": "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
"updated_at": "20xx-xx-xxTxx:xx:Z",
"id": xxxxxx,
"url": "https://api.github.com/authorizations/xxxxxx"
}
1.2 Issue取得のAPIをコール
以下のスクリプト(get_issues.sh)を実行すれば、issues.jsonに対象のRepogitoryのIssueが、"issues.json"に、NEWLINE_DELIMITED_JSON (1行ずつ) の形式で出力されます。
get_issues.sh
# !/bin/bash
REPO="hoge-organization/fuga-reponame"
TOKEN="xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
ISSUES_LIST="./issues.json"
NUM_OF_PAGES="30"
# Initialize issue list file
if [ -f ${ISSUES_LIST} ]; then
rm ${ISSUES_LIST}
else
touch ${ISSUES_LIST}
fi
# Get Issue list
for i in `seq 1 ${NUM_OF_PAGES}`
do
echo "${i}"
curl -H "Authorization: token ${TOKEN}" https://api.github.com/repos/${REPO}/issues\?state\=all\&page\=${i}\&per_page\=100\&sort\=created \
| jq -c '.[]' >> ${ISSUES_LIST}
done
解説
-
TOKENには上記操作で取得した値を設定してください -
今回は
state=allで指定していますが、closedやopenでも指定可能です。 公式マニュアル -
NUM_OF_PAGESは自RepogitoryのIssues数に合わせて適当な数値を設定してください。 (大きく設定しても問題ないです)- Github APIでは、取得件数がpage毎に
100という制限があるため、pageを分けて実行する必要があります
- Github APIでは、取得件数がpage毎に
-
curlの出力をパイプで
jq -c '.[]'に渡して、NEWLINE_DELIMITED_JSON に変更しています- BigQueryに読み込ませるため
$ ./get_issues.sh
1
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 405k 100 405k 0 0 198k 0 0:00:02 0:00:02 --:--:-- 198k
2
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 405k 100 405k 0 0 195k 0 0:00:02 0:00:02 --:--:-- 195k
3
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 500k 100 500k 0 0 249k 0 0:00:02 0:00:02 --:--:-- 249k
(..)
# curl コマンドが繰り返されます
2. ExportしたJSONをBigQueryに取り込む
2.1 BigQueryのSCHEMA定義
- BigQueryにIssue一覧のJSONを読み込むために、事前にSCHEMAを定義します
- ※ BigQuery読み込み時ののAUTODETECT機能を使用しても良いのですが、私が取り込んだ際はIssueの数が大きくなると取り込みでERRORがでてしまったため、明示的に作成しています。(特異な構造のデータがあったのか、原因は不明)
- ※ Issueの情報全ては定義していないため、他に必要な情報があれば以下の定義に追加する必要があります
bq mk --schema ./schema_github_issue.json github_analysis.table_issues
解説
- --schema option で SCHEMAを定義したJSONファイルを指定しています(後述ファイル)
- github_analysis : Dataset で、 table_issues : Table です。ここは好きに変えてOKです
$ bq mk --schema ./schema_github_issue.json github_analysis.table_issues
Table 'xxxxxxxxxxxx:github_analysis.test_table_issues' successfully created.
- 以下をコピペして使用してください
schema_github_issue.json
[
{
"name": "url",
"type": "STRING"
},
{
"name": "repository_url",
"type": "STRING"
},
{
"name": "labels_url",
"type": "STRING"
},
{
"name": "comments_url",
"type": "STRING"
},
{
"name": "events_url",
"type": "STRING"
},
{
"name": "html_url",
"type": "STRING"
},
{
"name": "id",
"type": "INTEGER"
},
{
"name": "node_id",
"type": "STRING"
},
{
"name": "number",
"type": "INTEGER"
},
{
"name": "title",
"type": "STRING"
},
{
"name": "user",
"type": "RECORD",
"fields": [
{
"name": "login",
"type": "STRING"
},
{
"name": "id",
"type": "INTEGER"
},
{
"name": "node_id",
"type": "STRING"
},
{
"name": "avatar_url",
"type": "STRING"
},
{
"name": "gravatar_id",
"type": "STRING"
},
{
"name": "url",
"type": "STRING"
},
{
"name": "html_url",
"type": "STRING"
},
{
"name": "followers_url",
"type": "STRING"
},
{
"name": "following_url",
"type": "STRING"
},
{
"name": "gists_url",
"type": "STRING"
},
{
"name": "starred_url",
"type": "STRING"
},
{
"name": "subscriptions_url",
"type": "STRING"
},
{
"name": "organizations_url",
"type": "STRING"
},
{
"name": "repos_url",
"type": "STRING"
},
{
"name": "events_url",
"type": "STRING"
},
{
"name": "received_events_url",
"type": "STRING"
},
{
"name": "type",
"type": "STRING"
},
{
"name": "site_admin",
"type": "BOOLEAN"
}
]
},
{
"name": "labels",
"type": "RECORD",
"mode": "repeated",
"fields": [
{
"name": "id",
"type": "INTEGER"
},
{
"name": "node_id",
"type": "STRING"
},
{
"name": "url",
"type": "STRING"
},
{
"name": "name",
"type": "STRING"
},
{
"name": "color",
"type": "STRING"
},
{
"name": "default",
"type": "BOOLEAN"
}
]
},
{
"name": "state",
"type": "STRING"
},
{
"name": "locked",
"type": "BOOLEAN"
},
{
"name": "assignee",
"type": "record",
"fields": [
{
"name": "login",
"type": "STRING"
},
{
"name": "id",
"type": "INTEGER"
},
{
"name": "node_id",
"type": "STRING"
},
{
"name": "avatar_url",
"type": "STRING"
},
{
"name": "gravatar_id",
"type": "STRING"
},
{
"name": "url",
"type": "STRING"
},
{
"name": "html_url",
"type": "STRING"
},
{
"name": "followers_url",
"type": "STRING"
},
{
"name": "following_url",
"type": "STRING"
},
{
"name": "gists_url",
"type": "STRING"
},
{
"name": "starred_url",
"type": "STRING"
},
{
"name": "subscriptions_url",
"type": "STRING"
},
{
"name": "organizations_url",
"type": "STRING"
},
{
"name": "repos_url",
"type": "STRING"
},
{
"name": "events_url",
"type": "STRING"
},
{
"name": "received_events_url",
"type": "STRING"
},
{
"name": "type",
"type": "STRING"
},
{
"name": "site_admin",
"type": "BOOLEAN"
}
]
},
{
"name": "assignees",
"type": "record",
"mode": "repeated",
"fields": [
{
"name": "login",
"type": "STRING"
},
{
"name": "id",
"type": "INTEGER"
},
{
"name": "node_id",
"type": "STRING"
},
{
"name": "avatar_url",
"type": "STRING"
},
{
"name": "gravatar_id",
"type": "STRING"
},
{
"name": "url",
"type": "STRING"
},
{
"name": "html_url",
"type": "STRING"
},
{
"name": "followers_url",
"type": "STRING"
},
{
"name": "following_url",
"type": "STRING"
},
{
"name": "gists_url",
"type": "STRING"
},
{
"name": "starred_url",
"type": "STRING"
},
{
"name": "subscriptions_url",
"type": "STRING"
},
{
"name": "organizations_url",
"type": "STRING"
},
{
"name": "repos_url",
"type": "STRING"
},
{
"name": "events_url",
"type": "STRING"
},
{
"name": "received_events_url",
"type": "STRING"
},
{
"name": "type",
"type": "STRING"
},
{
"name": "site_admin",
"type": "BOOLEAN"
}
]
},
{
"name": "milestone",
"type": "RECORD",
"fields": [
{
"name": "url",
"type": "STRING"
},
{
"name": "html_url",
"type": "STRING"
},
{
"name": "labels_url",
"type": "STRING"
},
{
"name": "id",
"type": "INTEGER"
},
{
"name": "node_id",
"type": "STRING"
},
{
"name": "number",
"type": "INTEGER"
},
{
"name": "title",
"type": "STRING"
},
{
"name": "description",
"type": "STRING"
},
{
"name": "creator",
"type": "RECORD",
"fields": [
{
"name": "login",
"type": "STRING"
},
{
"name": "id",
"type": "INTEGER"
},
{
"name": "node_id",
"type": "STRING"
},
{
"name": "avatar_url",
"type": "STRING"
},
{
"name": "gravatar_id",
"type": "STRING"
},
{
"name": "url",
"type": "STRING"
},
{
"name": "html_url",
"type": "STRING"
},
{
"name": "followers_url",
"type": "STRING"
},
{
"name": "following_url",
"type": "STRING"
},
{
"name": "gists_url",
"type": "STRING"
},
{
"name": "starred_url",
"type": "STRING"
},
{
"name": "subscriptions_url",
"type": "STRING"
},
{
"name": "organizations_url",
"type": "STRING"
},
{
"name": "repos_url",
"type": "STRING"
},
{
"name": "events_url",
"type": "STRING"
},
{
"name": "received_events_url",
"type": "STRING"
},
{
"name": "type",
"type": "STRING"
},
{
"name": "site_admin",
"type": "BOOLEAN"
}
]
},
{
"name": "open_issues",
"type": "INTEGER"
},
{
"name": "closed_issues",
"type": "INTEGER"
},
{
"name": "state",
"type": "STRING"
},
{
"name": "created_at",
"type": "STRING"
},
{
"name": "updated_at",
"type": "STRING"
},
{
"name": "due_on",
"type": "STRING"
},
{
"name": "closed_at",
"type": "STRING"
}
]
},
{
"name": "comments",
"type": "INTEGER"
},
{
"name": "created_at",
"type": "STRING"
},
{
"name": "updated_at",
"type": "STRING"
},
{
"name": "closed_at",
"type": "STRING"
},
{
"name": "author_association",
"type": "STRING"
},
{
"name": "body",
"type": "STRING"
}
]
- 注意: 以下はRecord形式です (ちゃんと定義すればBigQueryでよしなに取り込んでくれます)
- user
- labels
- milestone
- assignee
- assignees
2.2 BigQueryへのLoad
以下のコマンドで、先程出力したissues.jsonをloadします
bq load --replace --ignore_unknown_values --max_bad_records=10 --source_format=NEWLINE_DELIMITED_JSON github_analysis.table_issues ./issues.json
解説
-
--replace: Issueの状態が更新されたら毎回洗い替えしないとなので、--replaceoptionを使用しています -
--ignore-unknown_valuses&--max_bad_records=10: たまに変な値が入ってきてしまうので無視する optionです。 bad_recordは適宜変更してください -
--source_format: 読み取るファイル形式を指定しています。今回用意したのは NEWLINE_DELIMITED_JSON です -
github_analysis.table_issues: load先のtableです -
./issues.json: Issue一覧のファイルです
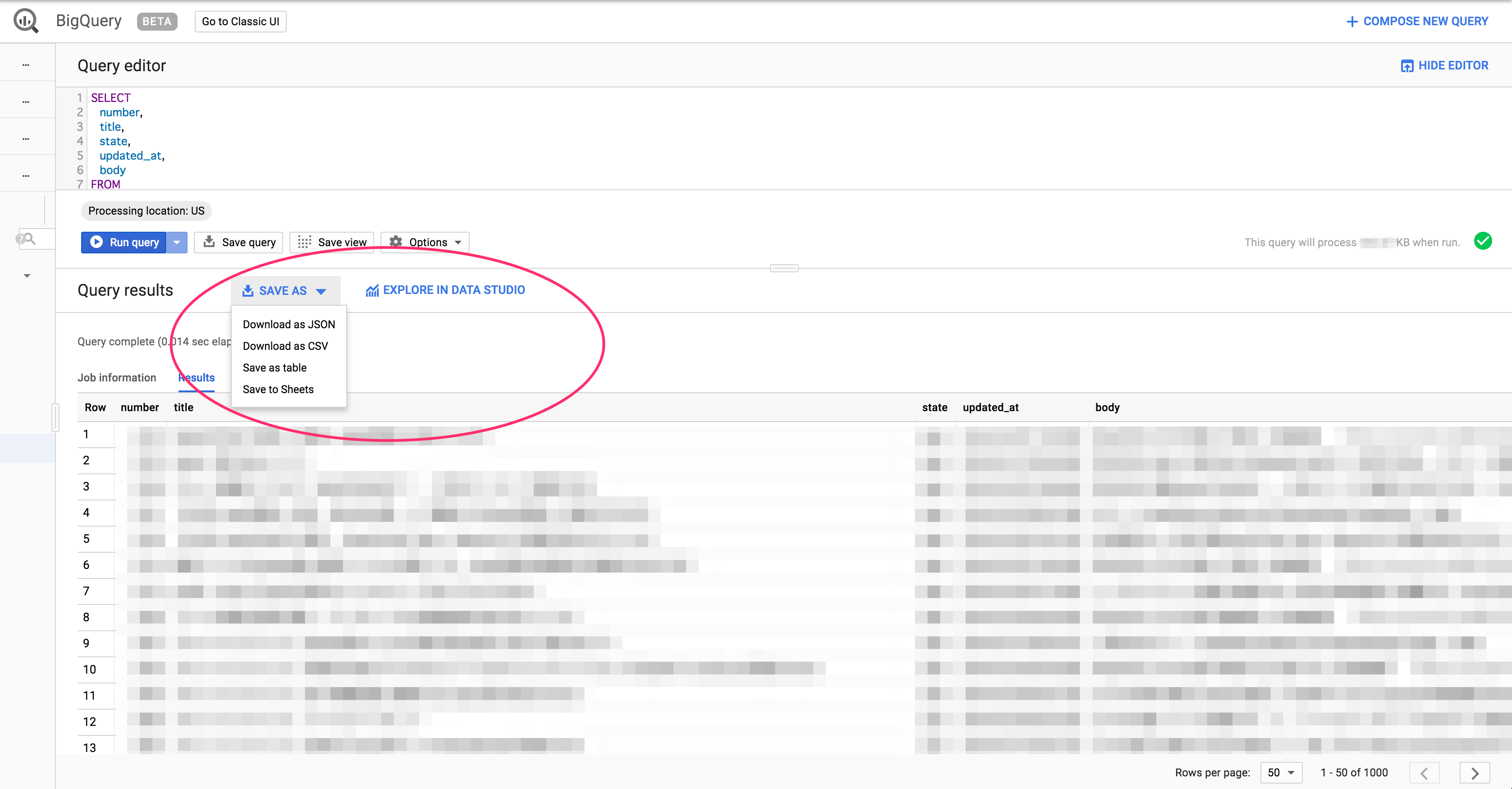
3. あとは必要な情報だけクエリを書いて抽出して、"Datastudio" でも "スプレッドシート" でも "Excel" 好きに扱えます。
赤枠部分の、"好きな形にExport" OR "EXPLORE IN DATASTUDIO" で自由にデータを扱ってください。
さいごに
- これをスクリプトにして、定期実行すれば、最新のIssue状況がBigQueryに反映されるようになります
- BigQueryは "View" の定義もできるので、 Datastdioでダッシュボードを作成すれば、準リアルタイムで開発状況がわかるプロジェクトマネージャーが喜ぶツールに変身です!