要旨
- いつの間にかollamaはマルチGPU対応していたらしい
- 2本目のPCIeスロットが3.0かつ4レーンという低性能、更に560W電源でもTDP165WのRTX4060tix2を支えて安定稼働できた1
HW構成
RTX4060tiを2枚買ってきて、既存の古い自作PCにぶっ差す。
RTX4060tiはメモリバス幅や価格でやいのやいの言われているが、VRAM容量最優先かつCUDA可能なNVIDIAグラボ、という条件では唯一の選択肢であろうと思う。
(VRAM容量特化のグラボ出してくれ〜〜〜頼む〜〜〜)
(あとROCmとOpenVINOも頑張ってくれ〜〜〜)
■核心部分
- マザボ:ASRock B550M Pro4
- PCIe 4.0 x16スロット (16 レーン幅)
- PCIe 3.0 x16スロット(4 レーン幅)
- 電源:560W(FD-PSU-IONP-560P-BK)
- GPU:RTX 4060ti 16GB x2
- 1枚目:Palit NE6406T019T1-1061J(ドスパラ3連ファンモデル)
- 2枚目:GV-N406TWF2OC-16GD(GIGABYTE製2連ファンモデル)2
■その他
- メモリ:DDR4 8GBx4
- CPU:Ryzen 5 3600
LLM環境
- コンテナ版Open WebUI(ollamaバンドル+GPUサポートありバージョン)をそのまま導入
https://github.com/open-webui/open-webui
Installing Open WebUI with Bundled Ollama Support
With GPU Support: Utilize GPU resources by running the following command:
docker run -d -p 3000:8080 --gpus=all -v ollama:/root/.ollama -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:ollama
あとは単純にOpen WebUIで任意のLLMをpullして動かすだけ。サイズが大きいモデルはollama側で自動的にRTX4060tiのVRAMを適当にまとめて使ってくれる。すごい。
マルチGPUでの分散処理ってvLLMかllama.cppでしかできなかったと聞いてたんだけど…
(ググったらollamaは内部でllama.cppを動かしているようなので、まあそういうことなのか。ありがたい限りである)
参考:VRAM消費状況・推論速度
以下の通り、9B程度までのLLMであればVRAM16GBで足りる。
いずれも4bit量子化したモデルを使用。
GPUの0番(上の方)がPCIe3.0(x4)のスロットであり、1番(下の方)がPCIe4.0(x16)となっている。どちらにモデルをロードするかはollamaが自動的に決めるが、番号順で決めているのか、基本的には0番の方から使われることが多い。
14bのモデルは一見するとギリギリ16GBで足りそうな雰囲気を出しているが、実際は1枚構成だとLLM以外の画面描画系の処理要素が入ってくるためモデルを載せ切れず、一部がCPUとメインメモリにオフロードされてtoken/secはガタ落ちする。
推論速度の体感上の目安としては以下のような印象。
30token/sec以上:神の領域
20token/sec:高速。人間の目では追いきれない速度
10token/sec:中速。文章としては高速に出るが、コード生成のように一括でほしいテキストの用途としては待ち時間が生じる
- gemma2:9b
VRAM消費:約10GB
推論速度:約38token/sec
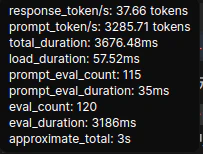
評価:さすがに1GPU上に乗っていれば、いかに4060tiのメモリバス幅が狭いとて、かなりの速度がでている。
- qwen2.5-coder:14b
VRAM消費:約15GB
推論速度:約27token/sec
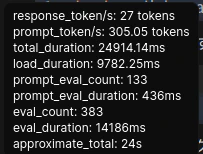
評価:メモリはカツカツだが、まだそれなりの速度で動く。
- gemma2:27b
VRAM消費:約20GB
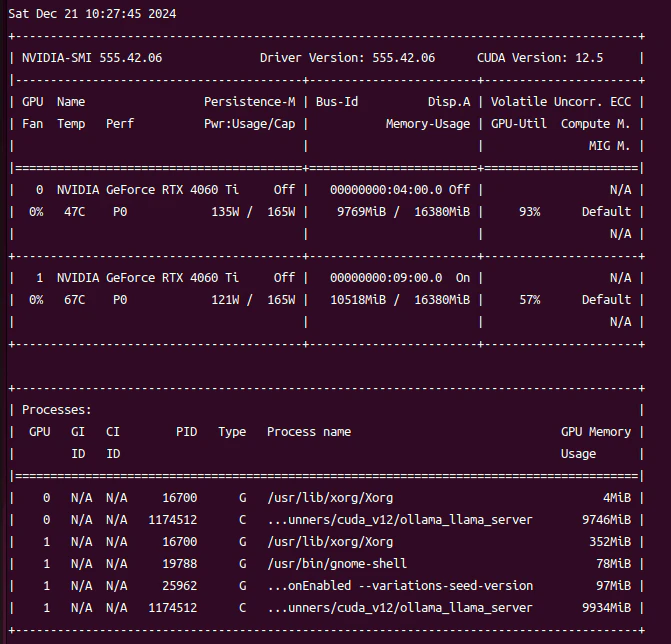
推論速度:約15token/sec
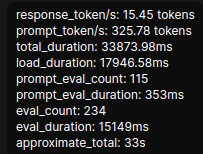
評価:ギリギリ実用圏内、といった中速。数十行程度のスクリプトなら問題にならないが、100行超の物を出そうとすると明確な待ち時間が発生する。でも個人のPC上で27bが動くこと自体がすごい。
- qwen2.5:32b
VRAM消費:約26GB

推論速度:約13token/sec
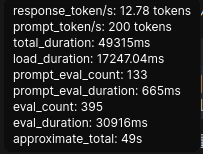
評価:実用範囲の下限ギリギリ、といった印象。ただ、30bクラスのモデルの品質での生成テキストを個人のPC上で(かつRTX3090だの4090だのという気の狂った価格のGPUを使わずに)入手できる、ということにはやはり価値がある。
中古で9~10万くらいの3090の出物を入手できたら案外24Gでも32bモデルが動いたりしてトータルコスト安いかもって?信用できる中古品ならそうかもね…
その他
以下の記事によるとGPU間の通信速度自体は送受信それぞれ50MiB/s程度あれば十分、とのことだったので、今回PCIe4.0(x16)と3.0(x4)という低スペックでの2枚差しに踏み切った。
https://note.com/aisatoshi/n/nb637bd484454
ただ、やはり単体GPU上で動いている分には20~40token/secの速度が出るのに対し、マルチGPU状態になると10~20token/secへと明確な速度の低下が発生している。
覚悟の上ではあったのでそれは構わないのだが、
- マザーボードを買い替えてPCIeの帯域が向上すれば推論速度が向上するのか
- 禁断のRTX4060ti 3枚差しにしてさらなる大規模モデルを載せても10~20token/secの速度は維持できるのか
といった部分は気になる。
気になるが、お金がないので記事はここで終わらざるをえない。
もしやるとしたら以下のように芋づる式の交換が発生し、1台丸々の新規構築案件になってしまうであろう。つらい。
・より高出力な電源への交換
・x16サイズのPCIeが3つあるマザボへの交換(できれば4.0の8レーンスロットが2つ、くらいはできてほしい)
・恐らくそのマザボのソケットはAM4じゃないのでCPUの交換
・恐らく電源とGPUの物理的な干渉が予想されるためケースの交換