Pythonでシステムリソース可視化ツールを作成しよう
新しく研究室に入ってくれた学部4年生のOJT研修のため、実際にpythonを使ってみる演習を行いました。
せっかくなので、qiitaでも公開してみようと思います。
はじめに
本実習では、Pythonを用いてVMのシステムリソース(CPU、メモリ、ディスク)の使用状況を定期的に取得し、グラフとして可視化することを目的としています。
近年、研究活動や実務においてもサーバや仮想環境を自ら管理・運用する機会が増えており、システムリソースの監視は安定した環境維持に欠かせない技術の一つです。これを手動で継続的に行うのは現実的でないため、自動化されたスクリプトによるモニタリングが広く活用されています。
本実習では、Proxmox上で構築したUbuntu仮想マシンを用い、以下の4つの力を養うことを目指します:
- Pythonによる実用的なスクリプト作成能力👨💻
- Linux環境での自動処理(cron)設定技術🕑
- 取得データの構造的保存(CSV)と可視化(グラフ化)手法 📊
- pythonコマンドを用いてWebサーバを立ち上げブラウザからアクセス🌎
なぜPython?
Pythonはシンプルな文法と豊富なライブラリにより、初心者から専門家まで幅広く支持されているプログラミング言語です。特に今回のようなデータ収集・処理・可視化を一貫して行う作業において、Pythonは非常に適しています。
また、psutil や matplotlib, pandas などのライブラリを利用することで、少ないコード量で高機能な処理が実現可能となり、システム管理やデータ分析の入り口としても学習効果の高いテーマです。
本実習を通して、Pythonを用いた「現場で使えるスクリプト作成」の経験を積み、今後の研究活動やインフラ運用に役立ててください。
Python環境のセットアップ手順
このドキュメントでは、Ubuntuサーバ上でPython3およびpip3のインストールを確認・実行し、その後に必要なライブラリ(psutil, pandas, matplotlib)をインストールする方法を説明します。
① Python3 がインストールされているか確認
python3コマンドとは、pythonスクリプトの実行や対話型シェルの利用ができるコマンドです。
まず、Python3がインストール済みか確認します:
python3 --version
出力例:
Python 3.10.12
バージョンが出力されれば、既にインストール済みなので以下のコマンドは実行不要です!
▶ Python3がインストールされていない場合
以下のコマンドでインストールします:
sudo apt update
sudo apt install python3
② pip3 がインストールされているか確認
pip3コマンドとは、Python 3 用のパッケージ管理ツール「pip」を起動するコマンドで、インターネット上のライブラリ(モジュール)を自分のPCに簡単にインストール・更新・削除できるツールです。
次に、pip3(Pythonパッケージ管理ツール)があるか確認します:
pip3 --version
出力例:
pip 23.2.1 from /usr/lib/python3/dist-packages/pip (python 3.10)
バージョンが出力されれば、既にインストール済みなので以下のコマンドは実行不要です!
▶ pip3がインストールされていない場合
次のコマンドでインストールします:
sudo apt install python3-pip
③ 必要なライブラリをインストール
以下のライブラリをインストールします:
-
psutil: システムリソース情報の取得 -
pandas: データ操作用ライブラリ -
matplotlib: グラフ描画ライブラリ
pip3 install --user psutil pandas matplotlib --break-system-packages
💡 Ubuntu 22.04以降では、
--break-system-packagesオプションを追加することでpipの制限を回避できます。{.is-info}
④ インストールの確認
以下のようにPython3を起動して、ライブラリが正しくインポートできるか確認します:
python3
Python対話モードが起動したら、次を入力:
import psutil
import pandas as pd
import matplotlib.pyplot as plt
exit()
対話モードで実行した際の様子は以下のようになります。
taro@TABLET:~/semi_python$ python3
Python 3.12.3 (main, Feb 4 2025, 14:48:35) [GCC 13.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import psutil
>>> import pandas as pd
>>> import matplotlib.pyplot as plt
>>> exit()
taro@TABLET:~/semi_python$
準備完了 !!
これでPythonと必要なライブラリのインストールが完了し、サーバ上でのスクリプト実行準備が整いました。
データ取得スクリプトの作成
サンプルコードをgithubからダウンロードしましょう。
今回はホームディレクトリにクローンし、フォルダの中にlog_writer.py、plot_graph.pyの2つのファイルがあることを確認してください。
cd ~
git clone https://github.com/taro470/semi_python.git
cd semi_python/
ls
次にlog_writer.pyをエディタで開き、プログラムを書いてみましょう。(10分)
psutilライブラリの使い方
CPU使用率(%)の取得
cpu = psutil.cpu_percent(interval=1)
print(f"CPU使用率: {cpu}%")
interval は秒数。1秒間の平均を取得します。
メモリ使用率(%)の取得
memory = psutil.virtual_memory().percent
print(f"メモリ使用率: {memory}%")
ディスク使用率(%)の取得
disk = psutil.disk_usage('/').percent
print(f"ディスク使用率: {disk}%")
os.path.isfile関数の使い方
使用例:ログファイルがあるか確認
log_path = "system_log.csv"
if os.path.isfile(log_path):
print("ログファイルが見つかりました。")
else:
print("ログファイルはまだ存在しません。新規作成します。")
このように、ファイルが存在するかどうかで処理を分けるのに便利です。
注意点
- パスがディレクトリの場合は
Falseを返します。 - パスが存在しないファイルでも
Falseを返します。
関連関数(発展)
| 関数名 | 説明 |
|---|---|
os.path.exists(path) |
ファイルまたはディレクトリの存在を確認 |
os.path.isdir(path) |
ディレクトリかどうかを確認 |
os.path.getsize(path) |
ファイルサイズを取得 |
csv.writerの使い方
csv.writer とは?
Python標準ライブラリの csv モジュールに含まれる writer クラスは、CSV形式のファイルにデータを書き込むためのツールです。
使用例
import csv
with open("example.csv", mode="w", newline="") as file:
writer = csv.writer(file)
writer.writerow(["名前", "年齢", "国"])
writer.writerow(["田中", 25, "日本"])
writer.writerow(["Smith", 30, "USA"])
-
mode="w" は書き込みモード(上書き)、mode="a" は追加書き込み
-
newline="" を指定することで、空行が入る問題を防止
-
writerow() で1行ずつリスト形式で書き込む
nano log_writer.py
import psutil # リソースの情報を取得するためのライブラリ
import datetime # 現在時刻取得に使用するライブラリ
import csv # csvファイルのデータを読み書きするためのライブラリ
import os # ファイル操作に関するライブラリ
# データを格納するcsvファイル(system_log.csv)のパスを定義
CSV_FILE = "/home/[①自分のユーザ名]/semi_python/system_log.csv"
# 使用しているリソースのデータを取得しcsvファイルに記述する関数を定義
[②] collect_data():
now = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S") # 現在時刻の取得
cpu = psutil.cpu_percent(interval=1) # CPU使用率の取得
mem = psutil.virtual_memory().percent # メモリ使用率の取得
disk = psutil.disk_usage('/').percent # ディスク使用率の取得
# csvファイルが存在すれば1,そうでなければ0
file_exists = os.path.isfile([③])
# csvファイルを開いてデータの書き込み
with open([④], mode='a', newline='') as f:
writer = csv.writer(f)
if not file_exists: # パスにファイルが無かった場合、最初にヘッダ追加
writer.writerow(["datetime", "cpu", "memory", "disk"])
writer.writerow([⑤■■,■■,■■,■■])
# ファイルが直接実行された場合にのみ、collect_data関数を実行
if __name__ == "__main__":
[⑥関数の実行]
plot_graph.pyは現在時刻、CPU使用率、メモリ使用率、ディスク使用率
①~⑥の空欄に入るコードを考えてみましょう。
ヒント
- 自分のユーザ名を入力しよう
- 関数を定義するときは、"def 関数名(引数) :"
- csvファイルのパスを表す変数を入力しよう
- open(パス,モード,改行コードの制御)の形式になってます
- 現在時刻、cpu使用率、メモリ使用率、ディスク利用率の値が入った変数名をそれぞれ入力しよう
- 関数名(引数) で関数の呼び出し
実際にスクリプトを実行してみて、csvファイルにデータが追加されたことを確認。
python3 log_writer.py
cat system_log.csv
以下のように出力されればOK
taro@TABLET:~/semi_python$ cat system_log.csv
datetime,cpu,memory,disk
2025-05-22 12:00:55,0.0,17.5,0.3
スクリプトの自動処理設定(cronの使い方)
このドキュメントでは、Ubuntuサーバ上でPythonスクリプトを定期的に自動実行するための cron の設定方法について説明します。
cronとは?
cron はLinuxやUNIX系OSで使用されるジョブスケジューラで、特定の時刻や間隔でコマンドやスクリプトを自動的に実行するための仕組みです。
例えば、1分ごと、毎時、毎日など柔軟なスケジューリングが可能です。
① cronの構文
cronのスケジュール構文は以下のようになっています:
* * * * * 実行するコマンド
││││ │
││││ └── 曜日(0=日〜6=土)
│││└──── 月(1〜12)
││└────── 日(1〜31)
│└──────── 時(0〜23)
└────────── 分(0〜59)
例1:* * * * * は「毎分」を意味します。
例2:12 11 05,10,15 * * は「毎月5日、10日、15日の11時12分」を意味します。
例3:12 11 05-15 1 * は「毎年1月の5日から15日までの11時12分」を意味します。
② crontab の編集
自分のユーザーのcronジョブを編集するには以下のコマンドを使用します:
crontab -e
初回実行時はエディタの選択が求められる場合があります。nano を選ぶと簡単です。
③ Pythonスクリプトを定期実行する設定
例として、/home/ユーザ名/semi_python/log_writer.py を1分ごとに実行するには以下を追加します:
* * * * * /usr/bin/python3 /home/ユーザ名/semi_python/log_writer.py
/usr/bin/python3の部分は次のコマンドで確認できます:which python3
④ 定期実行されてるか確認
実際に定期実行がされているか確認してみましょう。
system_log.csvファイルをcatで開いてみて確認。
cat system_log.csv
まとめ
-
cronはLinuxでのスクリプト自動実行の基本ツールです。 -
crontab -eで簡単に設定可能。
グラフ出力スクリプトの作成
- csvファイルの構成
先程のlog_writer.pyにより作成されたcsvファイルのデータのフォーマットは以下のようになっていました。
taro@TABLET:~/semi_python$ cat system_log.csv
datetime,cpu,memory,disk
2025-05-28 07:06:37,0.0,17.3,0.3
2025-05-28 07:06:39,0.1,17.3,0.3
2025-05-28 07:06:41,0.1,17.3,0.3
taro@TABLET:~/semi_python$
- 出力するグラフ
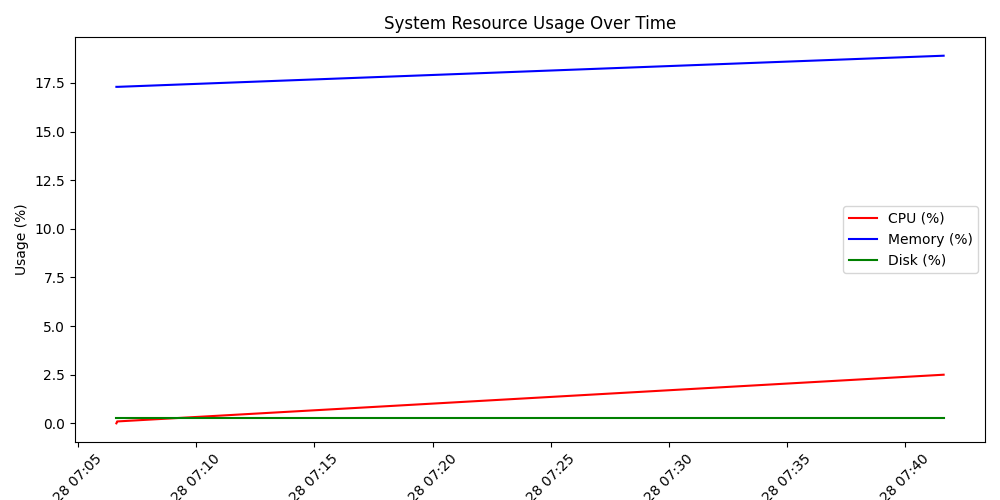
①スクリプトの作成
log_writer.pyをエディタで開き、取得したデータをグラフ化するプログラムを書いてみましょう。(10分)
[①] pandas as pd # ライブラリのインポート
[①] matplotlib.pyplot as plt # ライブラリのインポート
[①] matplotlib.dates as mdates # ライブラリのインポート
CSV_FILE = "/home/[②ユーザ名]/semi_python/system_log.csv"
IMG_FILE = "/home/[②ユーザ名]/semi_python/system_graph.png"
# グラフをプロットする関数の定義
def plot_graph():
df = pd.read_csv(CSV_FILE)
df["datetime"] = pd.to_datetime(df["datetime"])
plt.figure(figsize=(10, 5))
plt.plot(df["datetime"], df[③], label="CPU (%)", color="red")
plt.plot(df["datetime"], df[④], label="Memory (%)", color="blue")
plt.plot(df["datetime"], df[⑤], label="Disk (%)", color="green")
plt.xlabel("Time")
plt.ylabel("Usage (%)")
plt.title("System Resource Usage Over Time")
plt.legend()
plt.tight_layout()
plt.xticks(rotation=45)
plt.savefig(IMG_FILE)
plt.close()
# x軸を秒を除いたフォーマットに設定
plt.gca().xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d %H:%M'))
if __name__ == "__main__":
# 関数の実行
[⑥]
実際にスクリプトを実行してみて、出力された画像が追加されたことを確認。
python3 log_writer.py
ls
②スクリプトの定期実行
log_writer.pyと同様に、1分ごとに定期実行されるようにcronを設定しましょう。
crontab -e
以下のスクリプトをcronに追加。
* * * * * /usr/bin/python3 /home/ユーザ名/semi_python/plot_graph.py
ブラウザで画像を表示
これまでの作業で、1分ごとにシステムリソース使用率を取得しグラフを出力するシステムを構築できました。
しかし、今のところ出力されたファイルを確認するにはVMにアクセスしないといけません。
そこで、pythonの簡単なコマンドを用いてWebサーバを立てることによりブラウザからアクセスできるようになります。
手順
-
対象の画像ファイルがあるディレクトリへ移動する
cd /home/ユーザ名/semi_python
-
Pythonで簡易Webサーバを起動する
以下のコマンドを実行:
python3 -m http.server 8000このコマンドで、ポート8000番でWebサーバが起動する。
-
ブラウザを開いて、以下のURLにアクセスする
http://{VMのIPアドレス}:8000/ファイル一覧が表示されるので、画像ファイルをクリックすると表示される。
【補足】ポート番号は任意に変更可能(例:8080や3000など){.is-info}
【セキュリティ上の注意】
- この方法は開発・確認用に適しており、本番公開には向いていません。
- 外部からアクセス可能にする場合は、ファイアウォールの設定やアクセス制御が必要です。