はじめに
こんにちは!
僕は研究を行いながら、長期インターンでデータサイエンティストとして働く大学院生です!
学部時代から長期インターンを始め、現在まで4社経験してきました。
この経験から、プログラミングの学習を始めたばかりの人や、長期インターンを行う勇気が出ない人に、学習サポートやデータ分析の実績作り支援などを行わせてもらっています!
僕自身、プログラミングの習得や長期インターン探しに苦労したので、その経験をお伝えすることで、より多くの人が挫折せずデータサイエンティストになるまで成長して欲しいです!
以下でサポートを行なっているのでご興味ある方はご連絡ください!学生・社会人問わず専攻も問わずサポートいたします!
X(Twitter)
今回はwebサイトから自動的にデータを収集する技術であるWebスクレイピングについて解説します。本記事では、Pythonを使ったWebスクレイピングの基本から応用までを学びます。
Webスクレイピングとは
Webスクレイピングは、ウェブサイトから情報を自動で取得するテクニックです。このプロセスでは、プログラム(スクリプト)を使ってウェブページにアクセスし、必要なデータを抽出・保存します。人がウェブブラウザを使って情報を手動で検索・コピーするのとは異なり、Webスクレイピングはこのプロセスを自動化し、大量のデータを迅速に収集できます。
従って、データサイエンティストとして新たなデータを取得したい時などにとても有効な技術です。有用なデータは分散しており、手動で集めるには時間がかかりすぎます。Webスクレイピングを使えば、関連する情報を自動で収集し、分析のためのデータベースを素早く構築できます。
Webスクレイピングの基本プロセス
- ターゲットのWebページを特定する:収集したいデータが含まれるWebサイトを見つける
- リクエスト送信:Webスクレイピングようのプログラムからウェブサーバーにリクエストを送り、ページのHTMLコンテンツを取得する
- データの抽出:取得したHTMLから、必要な情報(テキスト、画像、リンクetc)を抽出する。このステップでは、HTMLの構造を解析し、特定のタグや属性に基づいてデータを識別する
-
データの保存:抽出したデータをデータベースやcsvファイルに保存する
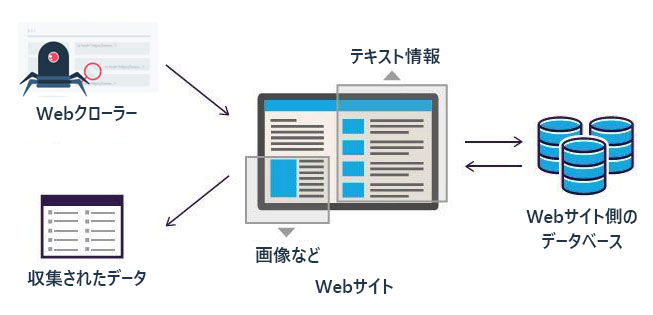
※引用元:https://www.octoparse.jp/blog/web-scraping
開発環境の準備
Pythonのインストールに加えてrequests, beautifulsoup4, seleniumライブラリをセットアップする。
Requests
PythonでウェブサーバーにHTTPリクエストを送信するためのライブラリ。ウェブページのHTMLを取得します。
BeautifulSoup
HTMLとXMLファイルからデータを抽出するためのPythonライブラリ。取得したページから必要な情報を解析・抽出します。噛み砕いて説明すると、requestsで取得してきたHTMLから、自身が欲しいデータ(テキストや画像)のみに加工し、抽出するライブラリである。
Selenium
ブラウザを自動操作するツール。JavaScriptで動的にコンテンツが生成されるページや、ユーザー操作が必要なページのスクレイピングに適しています。
例えば、スクロールしないと追加のデータが表示されない場合や、続きのデータを見たい場合、ボタンを押下し別のページに遷移する必要がある場合などに有効である。

ライブラリのインストール方法
pipを利用して3つのライブラリはインストールできる。
pip install requests beautifulsoup4 selenium
Requestsを使った基本的なスクレイピング
Requestsは、PythonでHTTPリクエストを簡単に扱うことができるライブラリです。Webスクレイピングにおいては、特定のウェブページからHTMLコンテンツを取得するために使われます。このセクションでは、Requestsを使用して実際のウェブページのデータをスクレイピングする基本的な方法を説明し、具体的なコード例を示します。
Requestsの基本的な使用方法
Requestsを使ってウェブページからデータを取得するプロセスは非常にシンプルです。まず、目的のページのURLにリクエストを送信し、レスポンスとしてHTMLコンテンツを受け取ります。このHTMLコンテンツから必要なデータを抽出するためには、後工程でBeautifulSoupのようなパーサーを使用することが一般的ですが、ここではまずRequestsの使用に焦点を当てます。
実際のWebページをスクレイピングする例
以下のコード例では、実際のウェブサイトから情報を取得し、その内容を表示する方法を説明します。この例では、Pythonの公式ウェブサイトから最新のニュースを取得しています。
import requests
# Python公式ニュースページのURL
url = 'https://www.python.org/blogs/'
# Requestsを使用してURLからデータを取得
response = requests.get(url)
# 正常にページが取得できたか確認
if response.status_code == 200:
print('OK')
else:
print('Failed to retrieve the webpage')
このコードは、まずrequests.getを使ってPythonのブログページからHTMLを取得します。次に、response.states_codeを確かめることで、正確にページ取得できたかを確認します。
BeautifulSoupによるHTML解析
BeautifulSoupは、HTMLやXMLファイルからデータを抽出するためのPythonライブラリです。ウェブページのマークアップから情報を読み取り、解析する際に非常に役立ちます。このセクションでは、BeautifulSoupを使用してHTMLを解析し、特定のデータを抽出する方法について詳しく説明します。
BeautifulSoupの基本的な使用例
BeautifulSoupを使用するには、まずBeautifulSoupオブジェクトを作成します。これには、解析したいHTMLコンテンツと、使用するパーサーを指定します。一般的にはhtml.parserが使用されますが、他にもlxmlやhtml5libなどのパーサーが利用可能です。
続いて特定のタグを検索します。find()やfind_all()メソッドを使用して、HTML内の特定のタグを簡単に検索できます。
他にも、特定の属性を持つタグを検索することもできます。例えば、class属性がnews-itemの全ての<a>タグを検索するようにコードを書いてみます。
先ほどのRequestsの説明に利用したコードを上書きしていきます。
import requests
from bs4 import BeautifulSoup as bs
# Python公式ニュースページのURL
url = 'https://www.python.org/blogs/'
# Requestsを使用してURLからデータを取得
response = requests.get(url)
# 正常にページが取得できたか確認
if response.status_code == 200:
print('OK')
# BeautifulSoupオブジェクトの作成
soup = bs(response.text, 'html.parser')
# すべての<a>タグを検索
links = soup.find_all('a')
# 各リンクのテキストとURL(href属性)を表示
for link in links:
print(link.text, link['href'])
# class属性がnews-itemの<a>タグを検索
news_items = soup.find_all('a', class_='news-item')
for item in news_items:
print(item.text, item['href'])
else:
print('Failed to retrieve the webpage')
BeautifulSoupによるHTML解析は、Webスクレイピングの基礎となるスキルです。このライブラリを使いこなせるようになると、インターネット上のあらゆる情報を自在に収集・解析することが可能になります。
Seleniumの活用
Seleniumは、ウェブブラウザの自動化を可能にするツールで、テスト自動化のために広く使われていますが、動的なコンテンツを含むウェブサイトからデータをスクレイピングする際にも非常に有用です。JavaScriptによって動的に生成されるコンテンツや、ユーザーのアクション(クリックやスクロールなど)を必要とするページの情報を取得する場合、Seleniumを使用すると良いでしょう。
動的なコンテンツとはSeleniumのライブラリ説明でも解説した通り、ボタンを押してページ遷移が必要だったり、スクロールすることで追加のデータを閲覧できる仕組みになっていたりするWebページを指す。
Seleniumの基本的な使用例
Seleniumを使用するには、まずSelenium WebDriverをセットアップする必要があります。WebDriverは、実際にブラウザを制御するためのもので、ChromeやFirefoxなど、様々なブラウザ用に提供されています。以下の例では、Google Chromeを使用します。
以下の例では、Wikipediaのメインページから「今日のできごと」のセクションをスクレイピングしてみましょう。このセクションは静的なコンテンツなので、BeautifulSoupでも取得可能ですが、Seleniumの使用例として利用します。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
# Selenium WebDriverのセットアップ
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service)
try:
# Wikipediaのメインページにアクセス
driver.get('https://en.wikipedia.org/wiki/Main_Page')
# 「今日のできごと」セクションの取得
# このIDはページによって異なる場合があるため、適宜調整が必要
events = driver.find_element(By.ID, 'mp-otd')
# セクションのテキストを表示
print(events.text)
finally:
# ブラウザを閉じる
driver.quit()
このコードは、Wikipediaのメインページにアクセスし、「今日のできごと」セクションのテキスト内容を取得してコンソールに出力します。webdriver_managerを使用することで、ChromeDriverのバージョン管理とセットアップを自動化しています。
このようにSeleniumを活用することで、JavaScriptが多用された動的なウェブページからも効率的にデータを取得することが可能になります。
他にもボタンを押下するメソッドや画面をスクロールするメソッド、XPathというものを指定して、取得したい部分のデータを取得するなどの方法もありますので、より深く学習したい場合は調べてみてください。
実践的なスクレイピング+分析例
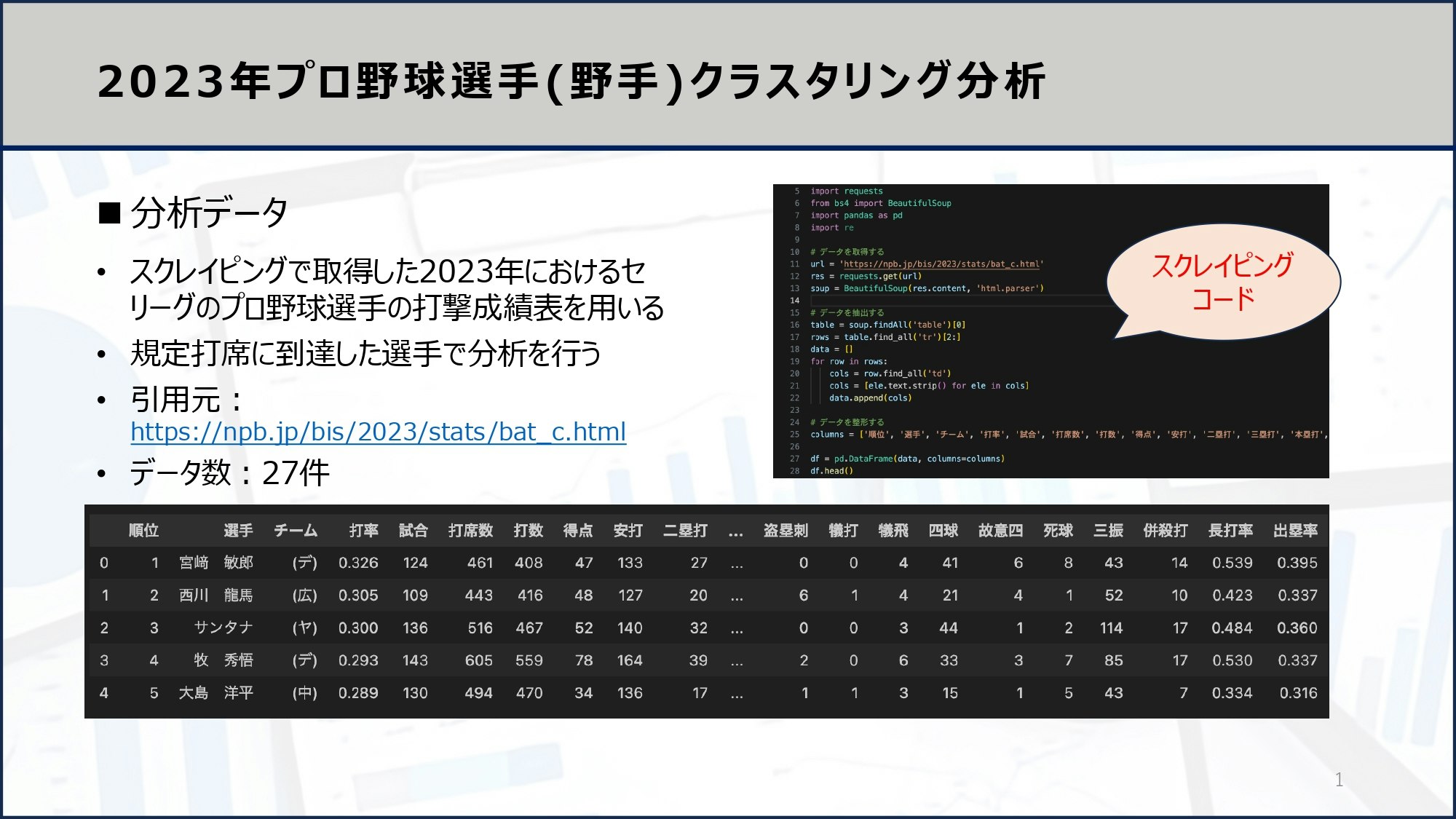
実際にWebページからデータを収集し、分析してみましょう。例えば、プロ野球選手の成績をスクレイピングにより取得し、KMeansクラスタリング分析を行うコードを以下に示します。
まずは、スクレイピングコードです。
# 次のリンクから野球の成績データをスクレイピングする
# https://npb.jp/bis/2023/stats/bat_c.html
# 野球の成績データをスクレイピングして、CSVファイルに保存する
import requests
from bs4 import BeautifulSoup
import pandas as pd
import re
# データを取得する
url = 'https://npb.jp/bis/2023/stats/bat_c.html'
res = requests.get(url)
soup = BeautifulSoup(res.content, 'html.parser')
# データを抽出する
table = soup.findAll('table')[0]
rows = table.find_all('tr')[2:]
data = []
for row in rows:
cols = row.find_all('td')
cols = [ele.text.strip() for ele in cols]
data.append(cols)
# データを整形する
columns = ['順位', '選手', 'チーム', '打率', '試合', '打席数', '打数', '得点', '安打', '二塁打', '三塁打', '本塁打', '塁打', '打点', '盗塁', '盗塁刺', '犠打', '犠飛', '四球', '故意四', '死球', '三振', '併殺打', '長打率', '出塁率']
df = pd.DataFrame(data, columns=columns)
df.to_csv('baseball.csv', index=False)
df.head()
続いてこの取得したデータを使ってKMeansクラスタリング分析を行います。
scikit-learnにあるKMeansにより分析を行います。
#k-meansクラスタリングによって、baseball.csvのデータをクラスタリングする
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
from sklearn.cluster import KMeans
#データの読み込み
data = pd.read_csv("baseball.csv")
#データの整形
data = data.dropna()
removed_data = data.drop(["順位", "選手", "チーム"], axis=1)
# K-meansクラスタリングを行う
kmeans = KMeans(n_clusters=3, random_state=0)
kmeans.fit(removed_data)
# クラスタリングの結果を元のデータに追加する
data["クラスタ"] = kmeans.labels_
data.head()
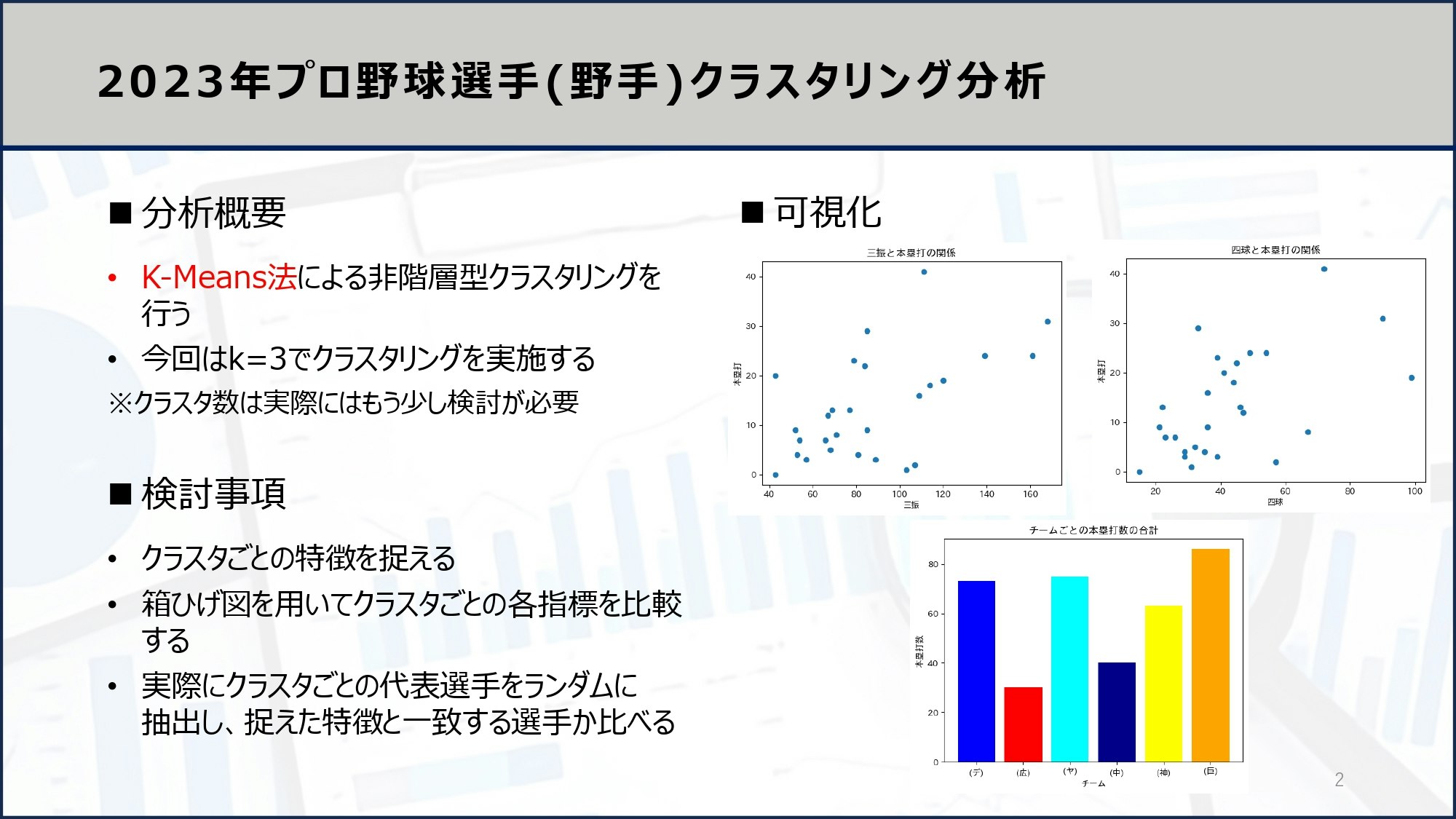

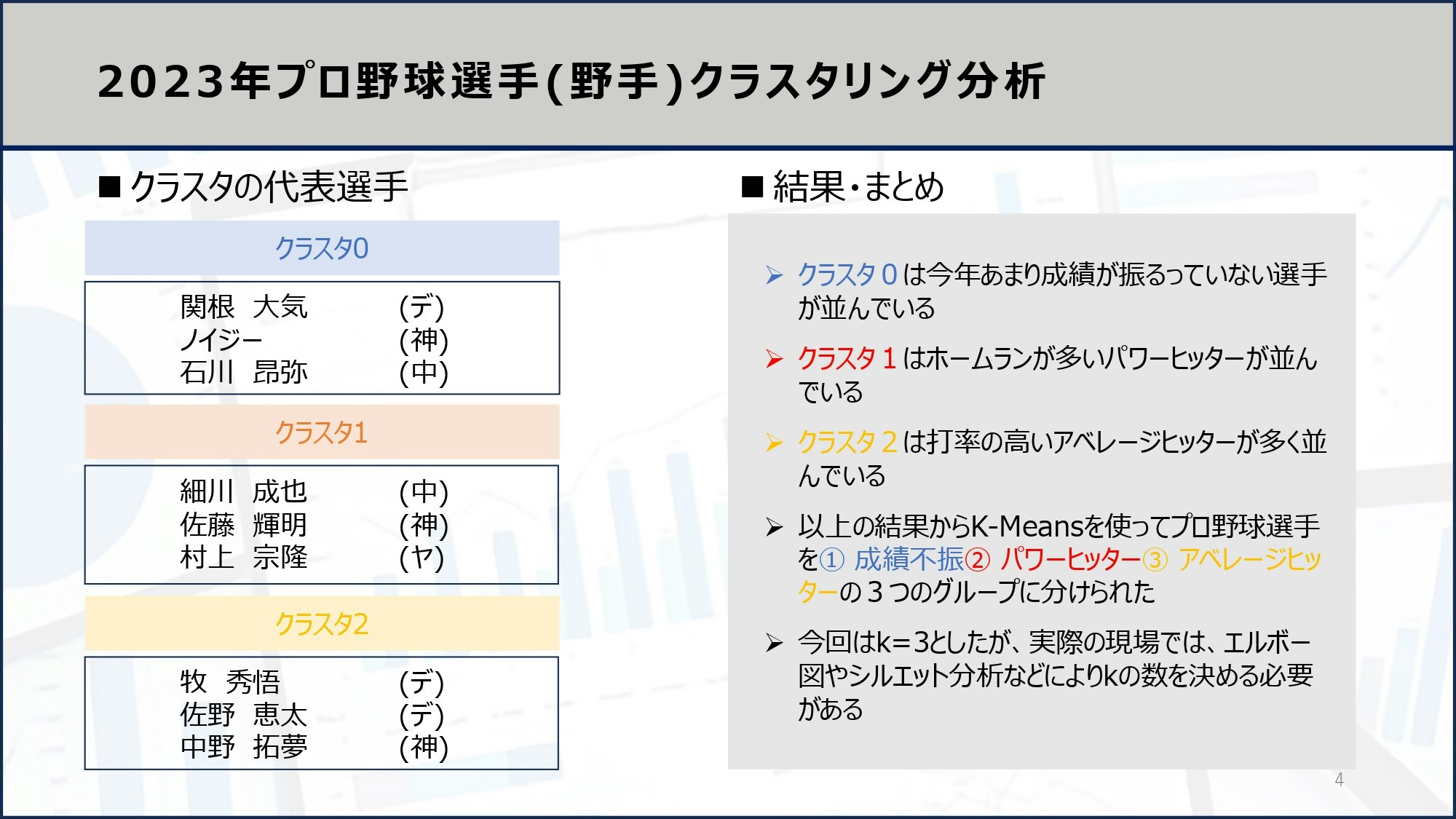
以上がKMeansクラスタリングをスクレイピングデータに適用した分析例です。スクレイピング技術を習得すると、あなたの独自の分析をしやすくなり、実践的な分析経験を積むことができるようになるので、ぜひ習得してみてください。
さいごに
最後まで読んでいただきありがとうございました!
少しでもデータサイエンティストを目指す方の一助となればと思います。
もし僕の活動にもご興味を持っていただけたら、X(Twitter)もフォローしていただけると嬉しいです!
X(Twitter)
参考文献
- ウェブスクレイピングとは
https://www.octoparse.jp/blog/web-scraping - python + selenium入門
https://qiita.com/studio_haneya/items/00ef4ad32b85163f95f1 - 図解!PythonのRequestsを徹底解説!
https://ai-inter1.com/python-requests/ - 図解!Python BeautifulSoupの使い方を徹底解説!
https://ai-inter1.com/beautifulsoup_1/