以前、Google画像検索からキーワードに沿った画像を大量に集める方法の紹介とWebサービスを作成したのでその紹介をしました。
((2018年12月31日)現在、Webサービスは閉じています。リニューアルしたものを作成中です。完成したら記事を更新したいと思います)
元々は機械学習やディープラーニングを行うにあたり、大量のデータが必要で手軽に集められる方法がないかと思い、画像クローラーを作成しました。
今回、おそらく画像データの収集先としてGoogle画像検索以外のサービスとして、最有力であると思われるInstagramから画像の収集を試みて、できそうだったので、その方法をご紹介します。
注: Instagramはサイトの更新が頻繁に行われているため、今後、ここで紹介した方法が使えなくなることがありますので、ご注意ください。
Instagramの正規の方法で画像を集める
Instagramには公式のAPIが存在します。開発者向けInstagramプラットフォームAPI | Facebook for Developers
このAPIを使用すれば、公式に大量の画像を集めることができます。(今回、こちらのやり方は省略)
しかし、このAPIにはいくつかの大きな欠点があります。
今回、大量の画像を集めることが目的ですので、API使用の審査をパスすることは残念ながら難しいと思われます。。。
Instagramから非公式の方法で画像を集める
正規の方法では大量の画像を集めるためには敷居が高すぎて現実的ではないので
調査したところ、公式のAPIの情報を使わない方法でデータを収集できそうであるのがわかったので、紹介します。
Instagramにログインしないで人の画像を見る
Instagramにログインしなくても、Instagramにある画像を表示することは割とできます。例えば以下のURLを見ることができます。
#ラブライブハッシュタグ - Instagram • 写真と動画
Instagramではキーワードの検索はなく、ハッシュタグでの検索となります。上記のように、
https://www.instagram.com/explore/tags/[ハッシュタグ名]/
で、タグでの画像検索を行うことができ、ログインしなくても画像を見ることができるというのがわかりました。
(画像の公開設定を変更したら見れなくなるので、Instagramを利用している方で見られたくない場合は公開設定を変更してください)
Instagramを解析する
ログインしないでブラウザで表示することができた。ということは解析すれば、Instagramからデータが取れそう、ということなので、解析してみます。
ファーストビュー解析
とりあえず、いつもどおり(?)、Chromeの開発者モードの画面を開いて通信の処理を確認します。
まずは、とりあえず、なんかそれらしい画像のURLがファーストビューのHTMLの中にないか調べるためにURLをコピーします。
そして、調べます。
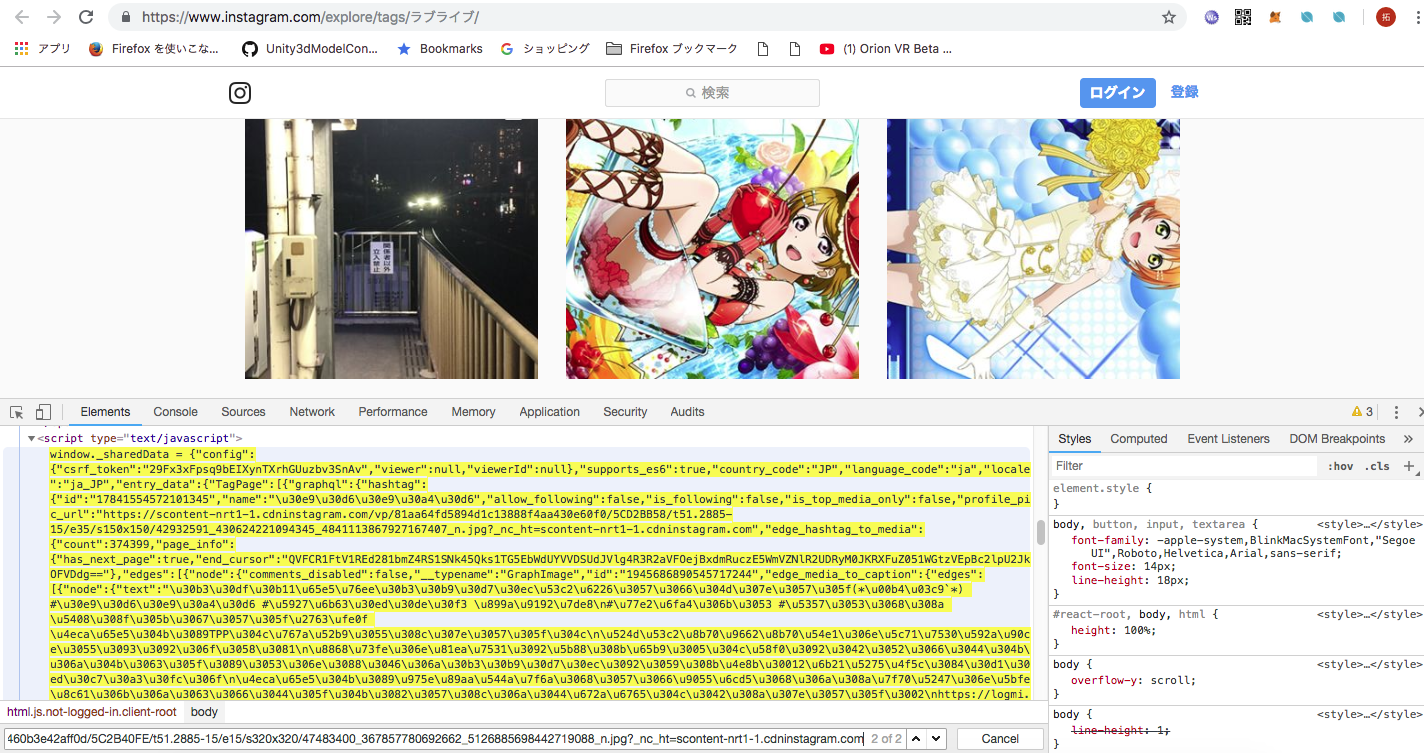
どうやらimgタグの中にあるURLの他にscriptタグの中にJSONらしき文字列があることが確認できます。
このJSONをプログラムを用いた場合でも正確に取得できるかやってみます。
現在作成中のものが ruby + rails + HTTPClient + Nokogiri を使って開発しているので、以下のように試してみます。
http = HTTPClient.new
response = http.get("https://www.instagram.com/explore/tags/%E3%83%A9%E3%83%96%E3%83%A9%E3%82%A4%E3%83%96/")
doc = Nokogiri::HTML.parse(response.body)
無事、HTMLをParseすることができました。次にJSONの部分を取得します。(割と雑に)
簡単にJSONである部分をくくりだして、JSON Parseできたものだけを抽出します。
jsons = doc.css("script").map do |d|
begin
JSON.parse(d.text.match(/{.*}/).to_s)
rescue JSON::ParserError => e
nil
end
end
jsons.select!{|j| j.present? }
jsonsの中になんかそれらしいものを無事Parseして取得できました。
{"config"=>{"csrf_token"=>"...", "viewer"=>nil, "viewerId"=>nil}, "supports_es6"=>false, "country_code"=>"JP", "language_code"=>"en", "locale"=>"en_US", "entry_data"=>{"TagPage"=>[{"graphql"=>{"hashtag"=>{"id"=>"17841554572101345", "name"=>"ラブライブ", "allow_following"=>false, "is_following"=>false, "is_top_media_only"=>false, "profile_pic_url"=>"https://scontent-nrt1-1.cdninstagram.com/vp/81aa64fd5894d1c13888f4aa430e60f0/5CD2BB58/t51.2885-15/e35/s150x150/42932591_430624221094345_4841113867927167407_n.jpg?_nc_ht=scontent-nrt1-1.cdninstagram.com", "edge_hashtag_to_media"=>{"count"=>374422, "page_info"=>{"has_next_page"=>true, "end_cursor"=>"QVFEc0prV3RIejd0NXd5ZVdrU2h6WXM3SmxxUFo2eUZfNm1JVzN6aVpHRVJMZHkzSHFvMzRBa09MSFUxckUtSXBac3ZSUm9EWVhCamt5TmVFcFI3aFg4ZQ=="}, "edges"=>[{"node"=>{"comments_disabled"=>false, "__typename"=>"GraphSidecar", "id"=>"1945810490753927307", "edge_media_to_caption"=>{"edges"=>[{"node"=>{"text"=>"..."}}]}, "shortcode"=>"...", "edge_media_to_comment"=>{"count"=>1}, "taken_at_timestamp"=>000000000, "dimensions"=>{"height"=>1080, "width"=>1080}, "display_url"=>"https://image_url...", "edge_liked_by"=>{"count"=>4}, "edge_media_preview_like"=>{"count"=>4}, "owner"=>{"id"=>"..."}, "thumbnail_src"=>"https://image_url...", "thumbnail_resources"=>[{"src"=>"https://image_url...", "config_width"=>150, "config_height"=>150}, {"src"=>"https://image_url...", "config_width"=>240, "config_height"=>240}, {"src"=>"https://image_url...", "config_width"=>320, "config_height"=>320}, {"src"=>"https://image_url...", "config_width"=>480, "config_height"=>480}, {"src"=>"https://image_url...", "config_width"=>640, "config_height"=>640}], "is_video"=>false, "accessibility_caption"=>"text"}}]}, "edge_hashtag_to_content_advisory"=>{"count"=>0, "edges"=>[]}}}}]}, "gatekeepers"=>{"seo"=>true, "seoht"=>true, "phone_qp"=>true, "nt"=>true, "rp"=>true, "daid"=>true, "frx"=>true, "oba"=>true, "hpi"=>true}, "knobs"=>{"acct:ntb"=>0, "cb"=>0, "captcha"=>0, "fr"=>0}, "qe"=>{"fsu_count"=>{"g"=>"", "p"=>{}}, "iab"=>{"g"=>"control", "p"=>{"has_open_app_ios"=>"false"}}, "app_upsell"=>{"g"=>"", "p"=>{}}, "profile_header_name"=>{"g"=>"", "p"=>{}}, "bc3l"=>{"g"=>"", "p"=>{}}, "direct_conversation_reporting"=>{"g"=>"", "p"=>{}}, "frx_reporting"=>{"g"=>"", "p"=>{}}, "general_reporting"=>{"g"=>"", "p"=>{}}, "reporting"=>{"g"=>"", "p"=>{}}, "acc_recovery_link"=>{"g"=>"", "p"=>{}}, "notif"=>{"g"=>"", "p"=>{}}, "mobile_stories_doodling"=>{"g"=>"", "p"=>{}}, "show_copy_link"=>{"g"=>"", "p"=>{}}, "p_edit"=>{"g"=>"", "p"=>{}}, "404_as_react"=>{"g"=>"", "p"=>{}}, "acc_recovery"=>{"g"=>"test_with_recaptcha", "p"=>{"has_recaptcha_removed"=>"true"}}, "collections"=>{"g"=>"", "p"=>{}}, "comment_ta"=>{"g"=>"", "p"=>{}}, "su"=>{"g"=>"", "p"=>{}}, "ebd_ul"=>{"g"=>"", "p"=>{}}, "ebdsim_li"=>{"g"=>"", "p"=>{}}, "ebdsim_lo"=>{"g"=>"", "p"=>{}}, "empty_feed"=>{"g"=>"", "p"=>{}}, "appsell"=>{"g"=>"", "p"=>{}}, "heart_tab"=>{"g"=>"", "p"=>{}}, "follow_button"=>{"g"=>"", "p"=>{}}, "log_cont"=>{"g"=>"control_intent_d", "p"=>{"has_contextual_d"=>"false"}}, "msisdn"=>{"g"=>"", "p"=>{}}, "onetaplogin"=>{"g"=>"", "p"=>{}}, "profile_tabs"=>{"g"=>"", "p"=>{}}, "em_sig"=>{"g"=>"control_no_dialog", "p"=>{"has_signup_email_suggestion"=>"false", "has_multi_step_email_suggestion"=>"false"}}, "multireg_iter"=>{"g"=>"test_back_removed_11_30", "p"=>{"has_back_removed"=>"true"}}, "reg_vp"=>{"g"=>"", "p"=>{}}, "report_media"=>{"g"=>"", "p"=>{}}, "report_profile"=>{"g"=>"", "p"=>{}}, "sidecar_swipe"=>{"g"=>"", "p"=>{}}, "su_universe"=>{"g"=>"", "p"=>{}}, "stale"=>{"g"=>"", "p"=>{}}, "tp_pblshr"=>{"g"=>"", "p"=>{}}, "video"=>{"g"=>"", "p"=>{}}, "felix"=>{"g"=>"", "p"=>{}}, "felix_clear_fb_cookie"=>{"g"=>"", "p"=>{}}, "felix_creation_duration_limits"=>{"g"=>"", "p"=>{}}, "felix_creation_enabled"=>{"g"=>"", "p"=>{}}, "felix_creation_fb_crossposting"=>{"g"=>"", "p"=>{}}, "felix_creation_fb_crossposting_v2"=>{"g"=>"", "p"=>{}}, "felix_creation_validation"=>{"g"=>"", "p"=>{}}, "felix_creation_video_upload"=>{"g"=>"", "p"=>{}}, "felix_early_onboarding"=>{"g"=>"", "p"=>{}}, "unfollow_confirm"=>{"g"=>"", "p"=>{}}, "profile_enhance_li"=>{"g"=>"", "p"=>{}}, "profile_enhance_lo"=>{"g"=>"", "p"=>{}}, "comment_enhance"=>{"g"=>"", "p"=>{}}, "mweb_topical_explore"=>{"g"=>"", "p"=>{}}, "follow_all_fb"=>{"g"=>"", "p"=>{}}, "lite_direct_upsell"=>{"g"=>"", "p"=>{}}, "web_loggedout_noop"=>{"g"=>"", "p"=>{}}, "a2hs_heuristic_uc"=>{"g"=>"", "p"=>{}}, "a2hs_heuristic_non_uc"=>{"g"=>"", "p"=>{}}, "web_hashtag"=>{"g"=>"", "p"=>{}}, "web_hashtag_logged_out"=>{"g"=>"", "p"=>{}}, "header_scroll"=>{"g"=>"", "p"=>{}}, "rout"=>{"g"=>"", "p"=>{}}, "web_lo_follow"=>{"g"=>"", "p"=>{}}, "web_share"=>{"g"=>"", "p"=>{}}, "lite_rating"=>{"g"=>"", "p"=>{}}, "web_embeds_share"=>{"g"=>"", "p"=>{}}, "web_share_lo"=>{"g"=>"", "p"=>{}}, "web_embeds_logged_out"=>{"g"=>"control_comment_count", "p"=>{"show_comment_count"=>"false"}}, "web_datasaver_mode"=>{"g"=>"", "p"=>{}}, "lite_datasaver_mode"=>{"g"=>"", "p"=>{}}, "lite_video_upload"=>{"g"=>"", "p"=>{}}, "ig_aat"=>{"g"=>"", "p"=>{}}, "post_options"=>{"g"=>"", "p"=>{}}, "igtv_public_viewing"=>{"g"=>"", "p"=>{}}, "caching"=>{"g"=>"", "p"=>{}}, "nux"=>{"g"=>"", "p"=>{}}, "hpi"=>{"g"=>"", "p"=>{}}, "iglmsr"=>{"g"=>"multi_reg_with_prefill", "p"=>{"has_multi_step_registration"=>"true", "has_prefill"=>"true"}}, "igwsvl"=>{"g"=>"", "p"=>{}}, "iglcp"=>{"g"=>"has_prefill", "p"=>{"has_login_prefill"=>"false"}}, "lite_story_video_upload"=>{"g"=>"", "p"=>{}}, "iglscioi"=>{"g"=>"", "p"=>{}}, "ws2"=>{"g"=>"", "p"=>{}}}, "hostname"=>"www.instagram.com", "deployment_stage"=>"c2", "platform"=>"web", "rhx_gis"=>"...........", "nonce"=>"........", "mid_pct"=>33.49735, "server_checks"=>{}, "zero_data"=>{}, "rollout_hash"=>"......", "bundle_variant"=>"metro", "probably_has_app"=>false}
(※ 量が多いので省略しました。またあまり公開するのはよろしくないため、雑に修正しています。)
このJSONの中に画像らしきURLも含まれていたので、このJSONを解析したら、画像の保存先のURLも取得することができそうです。
ここで、取得したJSONの中に
{"id":194581049075392730}
とあります。(約194京)
一般的にこのidの値は連番であることが多いのですが、そうであると、少なくとも194京もの画像がInstagramにはあると推測できます。(他に調べた限りだと、1000京近い値もありました。)
InstagramのIDの生成方式はsnowflake方式というものを使っているようなので実際にはそんなにはなさそうです。
Sharding & IDs at Instagram
ただ、ハッシュタグによっては数千万件(億も?)の投稿があることは確認できたので、Instagramには画像データ自体は莫大にあることが推測できます。
ページング解析
次にページをめくっていったときのデータの取得方法の解析を行います。
以下のようにページをめくっていきます。

最後の方に何やら怪しいリクエストが飛びました。リクエストの中身を見てみます。
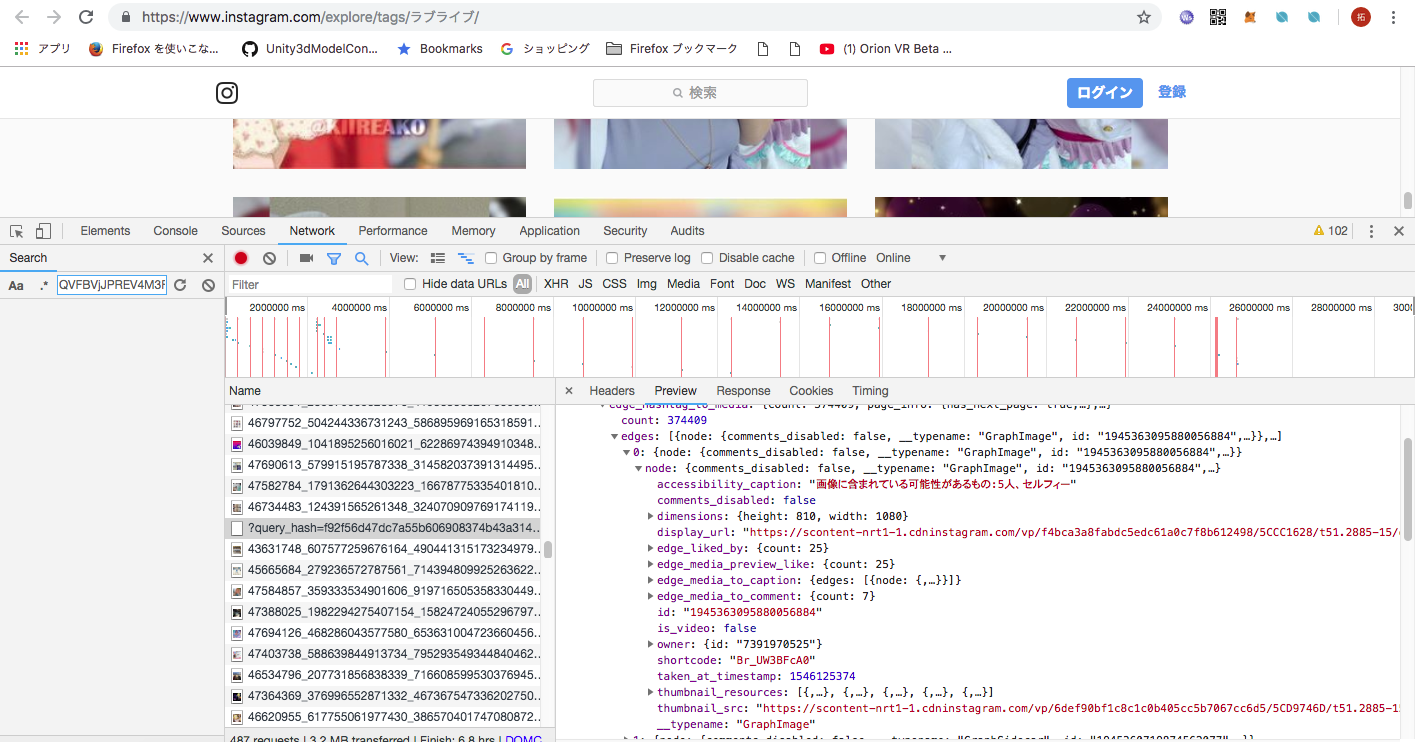
画像らしきもののデータを取得しているリクエストとそのレスポンスであるJSONを確認することができました。
次にリクエストとして送っている情報を見てみます。
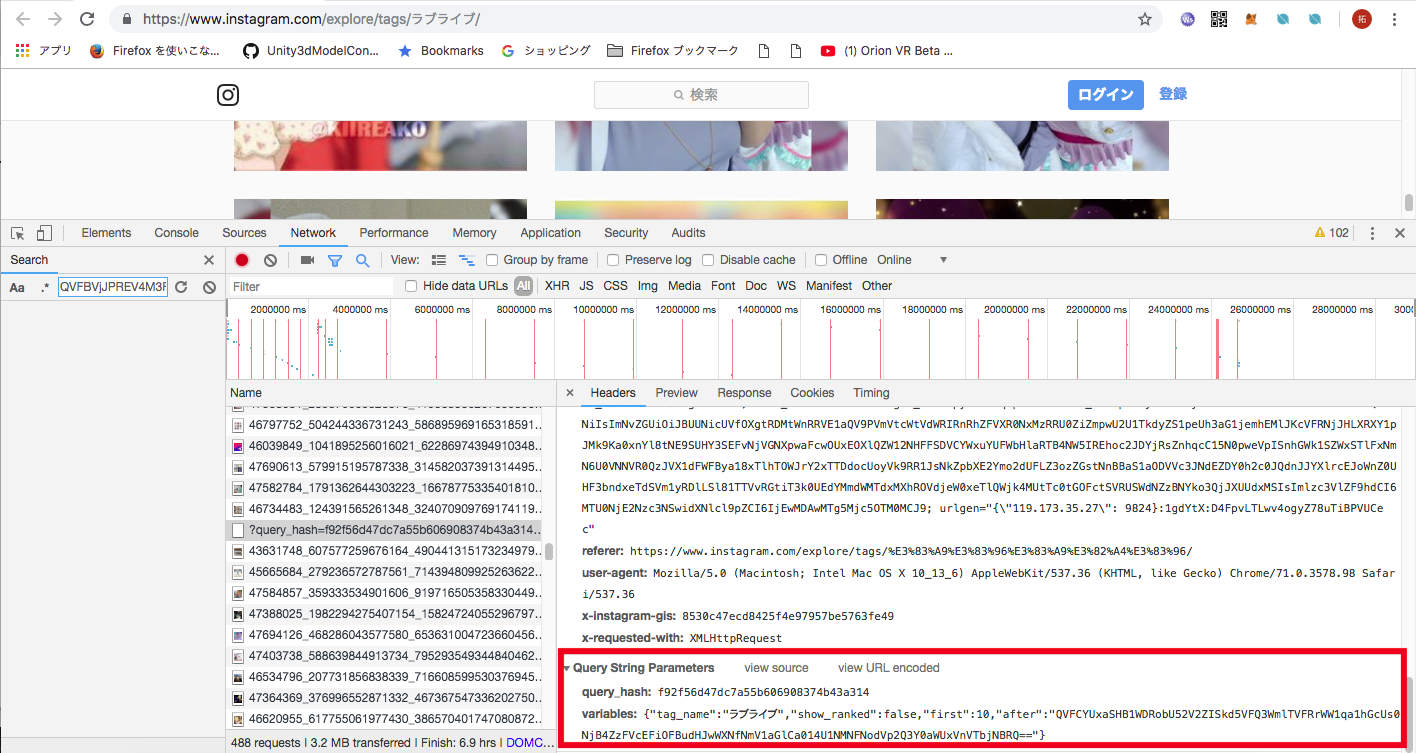
送っているクエリパラメータを確認することができました。
URLにすると以下のような感じです。
Request URL: https://www.instagram.com/graphql/query/?query_hash=f92f56d47dc7a55b606908374b43a314&variables=%7B%22tag_name%22%3A%22%E3%83%A9%E3%83%96%E3%83%A9%E3%82%A4%E3%83%96%22%2C%22show_ranked%22%3Afalse%2C%22first%22%3A12%2C%22after%22%3A%22QVFBVjJPREV4M3FjbDNnSWZTbHl3NWlBODFxYk1JYVppQ2lZWmlMSFdNOUI5SDJ1bXpGVlZqSURPMjZRcHl1alNWOU11R3lHdjlSczhTR29fM2RVVGZyYQ%3D%3D%22%7D
ここで送っているクエリパラメータの意味が何となくわかると思います。
ここで、 query_hash の値と after 以降の値に謎のあたいがあります。これらの値について更に調査解析してみました。
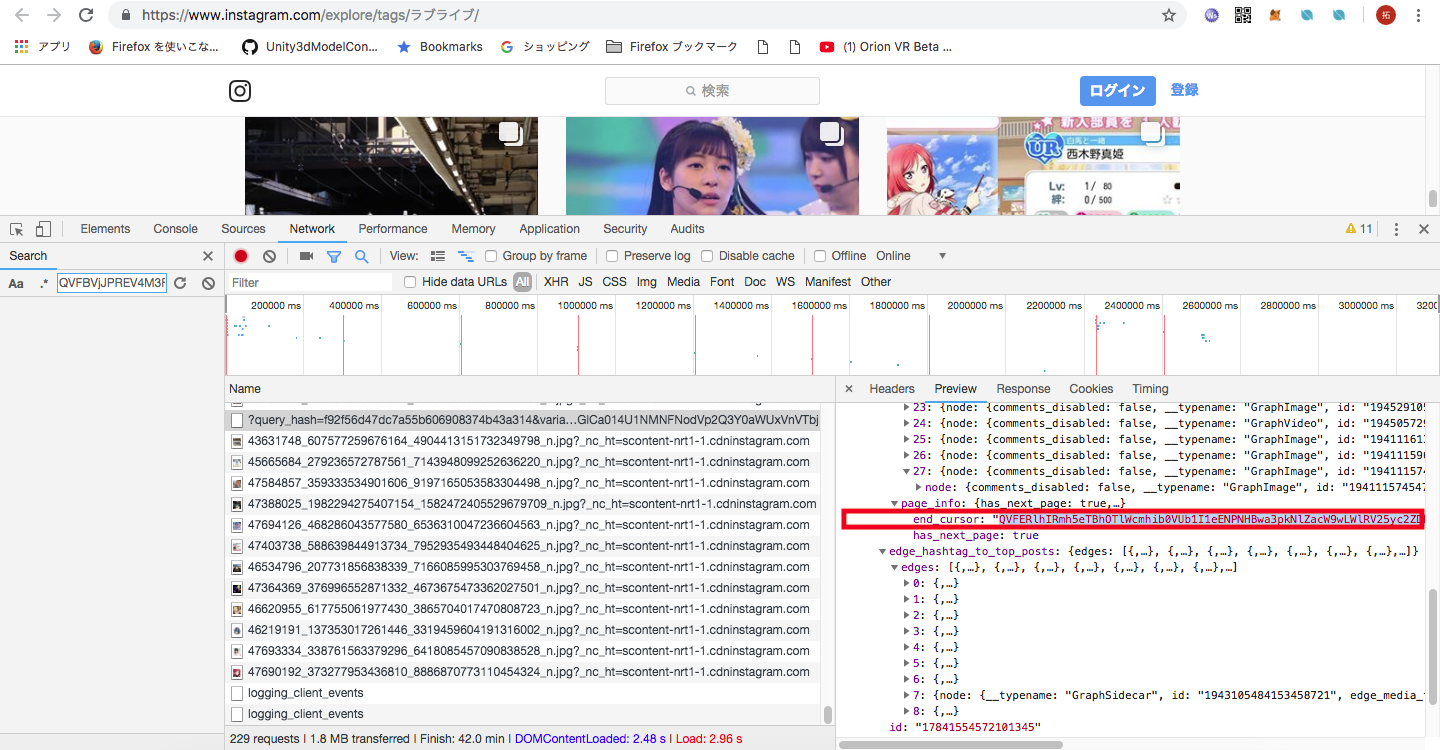
先ほどのリクエストのレスポンスの中に何やら、 after 以降に使われていそうな値がみつかりました。この、前のページで取得した end_cursor の値を用いて次のページの画像の情報取得できます。
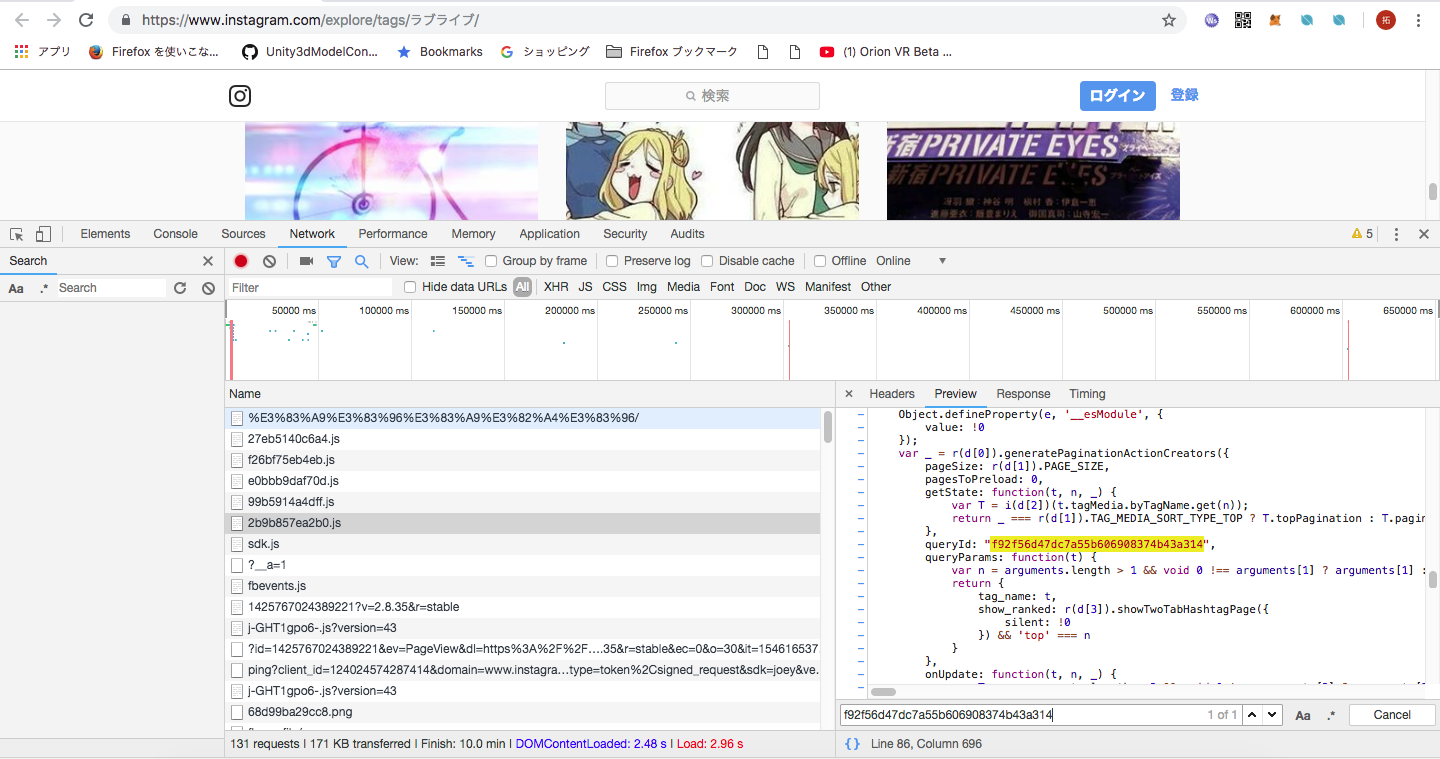
query_hash の値を調べた結果、最初に読み込んだjsファイルの中にそれらしいものがありました。jsファイルも解析して、この値を特定する必要がありそうです。
以上で取得した query_hashと after の値と必要な値を設定した上で、自動的に画像を取得する処理を書けば、Instagramからいくらでも画像データを取得することができそうです。
1/5更新
上記の値の他にfirstの値を正確な値を算出し、またHeaderに user-agent と x-instagram-gis の値を加えてリクエストを送らないと値が取得できないことがわかりました。
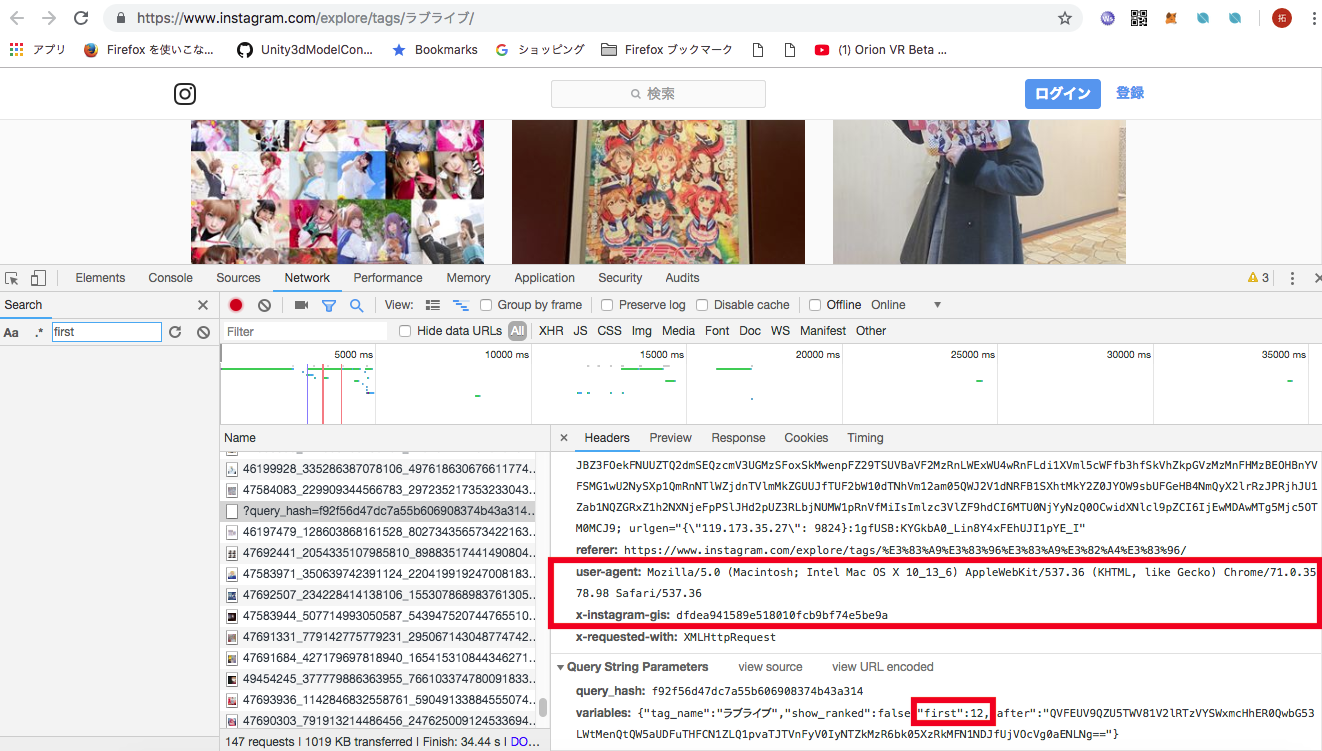
user-agent はどんなブラウザで見ているかという情報なので、試してみているブラウザの値を入力することで解決できます。その他の値は事前に読み込んだjsのなかで処理が行われている家庭で生成されているので、処理を追っていき、今後、特定してみようと思います。
(実際の作成した処理はWebサービス公開時に更新します)
Instagramのスクレイピングを調査してみてわかったこと
- データが莫大に有る
- Google画像検索ではヒットしない画像が多く取れる
- データを取得するのは割と大変
1.Instagramは世界最大の画像データが存在するサイトであると思われます。
3.についてはもう少し踏み込んだ実装ができたら、更新しようかなと思います。
最後に
ということで、公開まではしばしお持ちください。
ちなみに、一応、プロジェクト自体はこちらにあります。
https://github.com/TakuKobayashi/ResourceCrawler