過渡期では、ひどい状態になっているExcelからデータを拾い上げることがあります。
案件ごとに個別対応する部分は大きいですが、あってもいいんじゃない、と思った部分を関数化してみました。
対象となるデータ
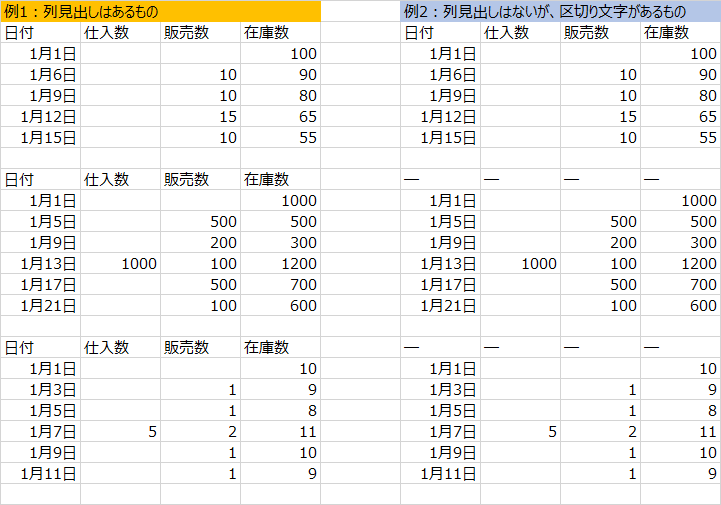
この量ならコピペでどうにでもなりますが、こうしたデータが何個も、各ファイル、各シート、あるいはシート内の複数列に散らばっているので、Power Queryで解決しようか、という発想が出てきます。
データの特徴としては、
- 各データの種類を示すヘッダがない。(列見出しはあっても、別データとして区別する手掛かりにならない)
- 各データの行数には規則性がない。
というものです。
日付も、1/1始まりで統一されているわけではなく、依拠できないと考えてください。
テストデータ
例によって、詳細エディタに貼ると、データになります。
例1
テスト1
let
ソース = Table.FromRows(Json.Document(Binary.Decompress(Binary.FromText("i45WejZ96ZPdM5R0lJ7snvq0demzqRuA7BebVj5dvAnCfjpnxdNdq0HsWJ1oJSMDIwN9A0MgUjCwMgAhoJK80pwcBGUIFENRaoap1BDEtkRTZ4lDnQWqOkMjLOpMgYSZKao6UxzmmULUoboamQLJ0iRc0DyMxYGmYI4pukosQWME5hijqTQ0RlIJthESIUDSCF2pOS7rzdFUGmHxFMRQM6hK+oclqkpjLA4EpTCC4Q1SZYGqCjlYQMnKCKTMkHBSxXSWIbZwgzgrFgA=", BinaryEncoding.Base64), Compression.Deflate)), let _t = ((type text) meta [Serialized.Text = true]) in type table [Column1 = _t, Column2 = _t, Column3 = _t, Column4 = _t])
in
ソース
例2
テスト2
let
ソース = Table.FromRows(Json.Document(Binary.Decompress(Binary.FromText("i45WejZ96ZPdM5R0lJ7snvq0demzqRuA7BebVj5dvAnCfjpnxdNdq0HsWJ1oJSMDIwN9A0MgUjCwMgAhoJK80pwcBGUIFENRaoap1BDEtkRTZ4lDnQWqOkMjLOpMgYSZKao6UxzmmULUoboamQLJPmqYCuSik8QHAZrfsLjFFMwxRVeJJRSMwBxjNJWGxkgqwTZCwh5IGqErNcdlvTmaSiMsnoIYagZVSdNgQ1VpjMUtoHRDMGhBqixQVSGHACixGIGUGRJOgJjOMsQWRBBnxQIA", BinaryEncoding.Base64), Compression.Deflate)), let _t = ((type text) meta [Serialized.Text = true]) in type table [Column1 = _t, 列1 = _t, 列2 = _t, 列3 = _t]),
#"Promoted Headers" = Table.PromoteHeaders(ソース, [PromoteAllScalars=true]),
#"Changed Type" = Table.TransformColumnTypes(#"Promoted Headers",{{"日付", type text}, {"仕入数", type text}, {"販売数", type text}, {"在庫数", type text}})
in
#"Changed Type"
コード
関数化してます。qiitaだと読みづらいので、詳細エディタに貼って、インテリセンスONで読んでもらった方がいいと思います。
fx_テーブルを行番で分割
(Source as table, //加工対象のデータ。
Positions as list, //加工対象を区切る行番号のリスト。最後の位置も指定する。
IncludeDelimiter as logical //区切る行番号をデータに含めるかどうかの指定。
)=>
let
//2分割なら、Positionsの中身は最初、中、最後の3つなので、1を引く。
NumberOfTable = List.Count(Positions)-1,
//のちに開始位置を調整するための数値を設定。
adjustment=if IncludeDelimiter then 1 else 0,
ListOfTable=List.Generate(
//初項:最終的には破棄する。
()=>[id=0,start=null,tbl=null],
//制約条件:idが丁度テーブルの生成数に当たる。
each [id]<=NumberOfTable,
//リストの作成。
each [
//いわゆるインクリメント
id=[id]+1,
//一番最初の位置は飛ばさないので、調整を排除する。
start=Positions{[id]}+(if [id]=0 then 0 else adjustment),
tbl=Table.Range(Source,
start,
//行数を計算。最後の場合、行数が1足らなくなるので補充する。idは現在位置の方を取る。
Positions{id}-start+(if id= NumberOfTable then 1 else 0)
)
],
each [tbl]
),
//初項の破棄。
SkipFirstRow=List.Skip(ListOfTable,1)
in
SkipFirstRow
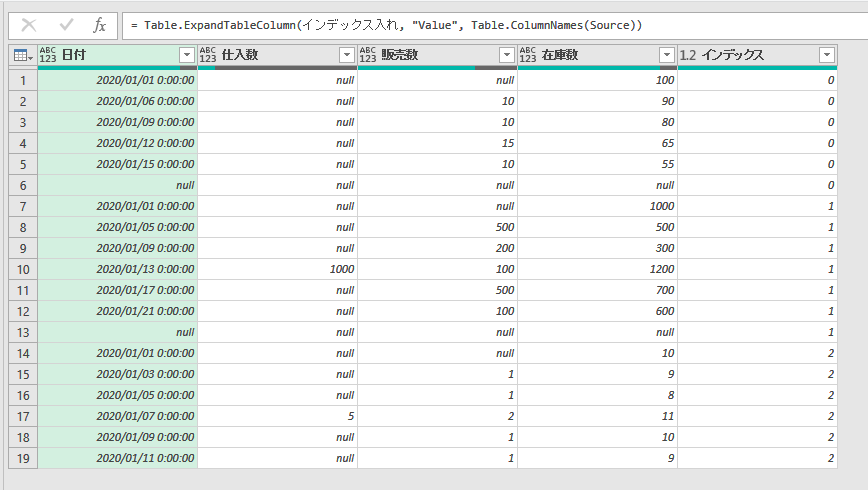
利用例(例1)
内容確認の意味で、各テーブルにインデックスを振ったテーブルにしてみます。
※実際には、このようにテーブルを展開することなく、分割したまま各テーブルにまた処理を施していきます。
利用例のコード
先にコードを示します。
テスト1での利用例
let
Source = テスト1,
行番の用意 = List.PositionOf(Source[Column1],"日付",Occurrence.All) &{Table.RowCount(Source)-1},
テーブル分割 = fx_テーブルを行番で分割(Source,行番の用意,false),
テーブル化 = Table.FromValue(テーブル分割),
インデックス入れ = Table.AddIndexColumn(テーブル化, "インデックス", 0, 1),
テーブル列の展開 = Table.ExpandTableColumn(インデックス入れ, "Value", Table.ColumnNames(Source))
in
テーブル列の展開
プレビュー画像など
行番の様子
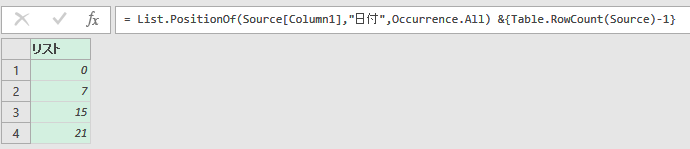
この関数の利用上大事なのは、「行番リストは自分で用意する」ことです。
行番リストの取り方はケースごとに異なるので、関数の方に含めづらかったからです。
PQ既定の関数を駆使して、用意します。
行番は0始まりで数えるので、データ件数から1引いています。
分割後
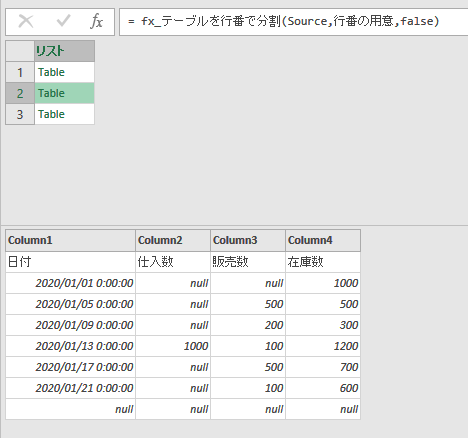
完成
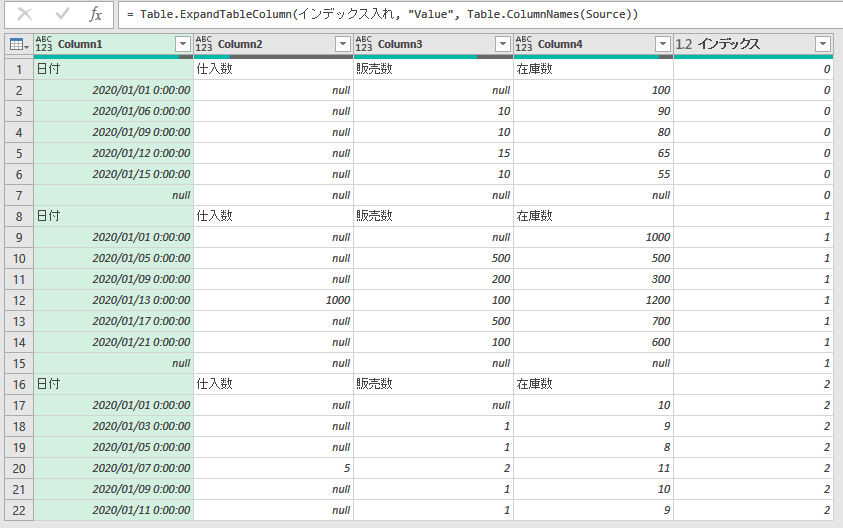
利用例(例2)
こちらも同じく、インデックスを振って展開してみてます。
例1と違うのは、
- 区切り文字を除いて分割するので、関数の第二引数をfalseにしていること。
- 分割するテーブルの1個目には区切り文字がないので、行番リストに0を足していること。
です。
let
Source = テスト2,
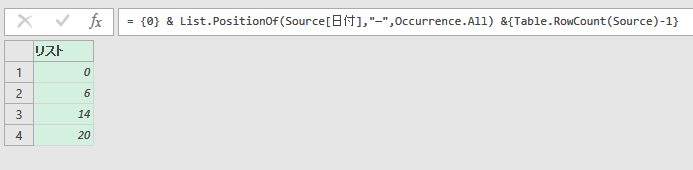
行番の用意 = {0} & List.PositionOf(Source[日付],"―",Occurrence.All) &{Table.RowCount(Source)-1},
テーブル分割 = fx_テーブルを行番で分割(Source,行番の用意,true),
テーブル化 = Table.FromValue(テーブル分割),
インデックス入れ = Table.AddIndexColumn(テーブル化, "インデックス", 0, 1),
テーブル列の展開 = Table.ExpandTableColumn(インデックス入れ, "Value", Table.ColumnNames(Source))
in
テーブル列の展開
行番リスト
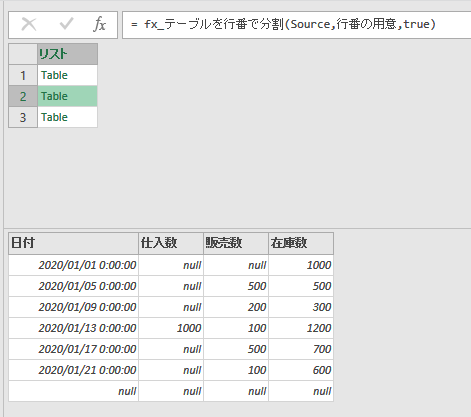
分割後の様子
完成の様子