追記
2021/05/11: 公式でpivot, unpivot機能がつきました。🎉
https://cloud.google.com/bigquery/docs/reference/standard-sql/query-syntax#pivot_operator
pivotとunpivot
テーブルの縦長テーブルを横長テーブルにするのがpivot
横長テーブルを縦長テーブルにするのがunpivot
つまり、こういうこと。ちょっと例が悪かったかも
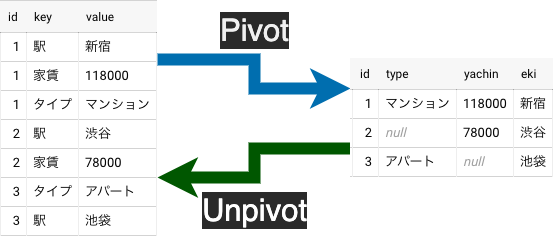
例えば、GoogleAnalyticsのcustomDimensionsなんかはkey/valueの配列だからこんな感じ
Pivot
pivotする際にBigQueryは動的にカラムを生成する術が今のところない(と思われる)のでkeyカラムの値ごとにSELECTする必要がありクエリが長くなりがち。
値ごとにANY_VALUEやMAXなんかの集計関数を使う必要がある。
CREATE TEMP TABLE bukken AS
SELECT *
FROM UNNEST([STRUCT<id INT64, key STRING, value STRING>
(1, '駅', '新宿'),
(1, '家賃', '118000'),
(1, 'タイプ', 'マンション'),
(2, '駅', '渋谷'),
(2, '家賃', '78000'),
(3, 'タイプ', 'アパート'),
(3, '駅', '池袋')]);
WITH ranked_key AS (
SELECT key, RANK() OVER (ORDER BY key) AS rank
FROM (SELECT DISTINCT key FROM bukken)
)
, wide_ranked AS (
SELECT
ANY_VALUE(IF(key="タイプ", rank, NULL)) AS type,
ANY_VALUE(IF(key="家賃", rank, NULL)) AS yachin,
ANY_VALUE(IF(key="駅", rank, NULL)) AS eki
FROM ranked_key
)
, long_array_agg AS (
SELECT id, ARRAY_AGG(STRUCT(value AS s) ORDER BY key) AS values
FROM bukken
RIGHT JOIN (
SELECT id, key
FROM ranked_key, (SELECT DISTINCT id FROM bukken)
ORDER BY id, rank
) USING (id, key)
GROUP BY id
)
, result AS (
SELECT id,
values[ORDINAL(type)].s AS type,
values[ORDINAL(yachin)].s AS yachin,
values[ORDINAL(eki)].s AS eki
FROM wide_ranked, long_array_agg
ORDER BY id
)
SELECT * FROM result;
こちらを参考に少し変えている。
単にANY_VALUE(IF(key='タイプ', value, NULL))とする方がクエリは短いが、上記の方法の方が早いとのこと(だが寧ろ遅くなった後述)
最初に思いつく方の簡単なpivotクエリ
WITH slow AS (
SELECT id,
ANY_VALUE(IF(key="タイプ", value, NULL)) AS type,
ANY_VALUE(IF(key="家賃", value, NULL)) AS yachin,
ANY_VALUE(IF(key="駅", value, NULL)) AS eki,
FROM bukken
GROUP BY id
)
SELECT * FROM slow;
速度比較
CREATE TABLE bukken AS
SELECT id, key, value
FROM UNNEST([STRUCT<key STRING, value STRING>
('駅', '新宿'),
('家賃', '118000'),
('タイプ', 'マンション')
])
CROSS JOIN UNNEST(GENERATE_ARRAY(1, 1000000)) AS id;
以上のカサ増ししたテーブルで時間を測ってみたところ
fastバージョンが24.1秒でslowバージョンが5.1秒と逆に遅くなってしまった。(?)
オリジナルのクエリを弄ってしまったのが問題なのかもしれない。
Unpivot
一方こちらは、いちいち値ごとにANY_VALUEとかMAXとかする必要がなく書けてしまう。
キモはレコードのSTRUCTオブジェクトをTO_JSON_STRINGを用いてカラム名を取り出すところにある。
参考にしたページ
unpivotの処理部分は先に関数として切り出しておく。
CREATE TEMP FUNCTION UNPIVOT(x ANY TYPE, col_regex STRING) AS ((
SELECT ARRAY_AGG(STRUCT(key, value))
FROM (
SELECT
REGEXP_EXTRACT(y, '^"([^"]+)') AS key,
REGEXP_EXTRACT(y, r':"?([^"]+)') AS value
FROM (
SELECT SPLIT(REPLACE(REPLACE(json, '{', ''), '}', ''), ',') AS items,
FROM (SELECT TO_JSON_STRING(x) AS json)
), UNNEST(items) AS y
)
WHERE REGEXP_CONTAINS(key, col_regex)
));
少しネストが深くて見辛いが順にみていく。
SELECT SPLIT(REPLACE(REPLACE(json, '{', ''), '}', ''), ',') AS items,
FROM (SELECT TO_JSON_STRING(x) AS json)
先ほどキモといった部分。xはpivotテーブルの1行がSTRUCTで入ってくる。
TO_JSON_STRING(x)で
{"id":1,"type":"マンション","yachin":118000,"eki":"新宿"}
とJOSN文字列に変換される。
基本的にはこれを頑張ってパースしていく。
JSON_EXTRACTという関数もあるがこれだとkey自体が取得できない。
とりあえず、SPLIT(REPLACE(REPLACE(json, '{', ''), '}', ''), ',')部分で{と}を削除して,で分割している。
items = ['"id":1', '"type":"マンション"', '"yachin":118000', '"eki":"新宿"']
という感じ。
REGEXP_EXTRACT(y, '^"([^"]+)') AS key,
REGEXP_EXTRACT(y, r':"?([^"]+)') AS value
の部分でkeyとvalueに分解している。(正規表現はあまり得意でなく自信がない)
そして、得られたkey/valueをARRAY_AGGでまとめるのだが、その前に
WHERE REGEXP_CONTAINS(key, col_regex)
で必要なkeyのみを取得するようにする。col_regexで該当するkeyのみを取得する。
使い方
WITH pivot AS (
SELECT *
FROM UNNEST([STRUCT<id INT64, type STRING, yachin INT64, eki STRING>
(1, 'マンション', 118000, '新宿'),
(2, NULL, 78000, '渋谷'),
(3, 'アパート', NULL, '池袋')])
)
SELECT
id,
CASE item.key
WHEN 'type' THEN 'タイプ'
WHEN 'yachin' THEN '家賃'
WHEN 'eki' THEN '駅'
END AS key,
item.value
FROM pivot AS x, UNNEST(UNPIVOT(x, r'[^(id)]+')) AS item
WHERE value != 'null';
pivotされたレコードを先ほどのUNPIVOT関数に渡しUNNESTするだけ。
今回はidを含む行以外を取得するような正規表現を渡している。
これで縦長のテーブルに変換できる。
感想
BigQueryではあんまりpivotとかunpivotとかやらないような気もするが、引き出しは多い方が良いためメモ。