⚠️この記事はベータ分布っぽい乱数は生成することに成功していますが、おそらく完全には従っていません。
ネタ記事ですので、本当に乱数生成したい方はUDFをjavascriptで書くなどを検討ください。
ふとした興味でBigQueryで乱数を生成してみたくなる
ことってありますよね。
ベータ分布
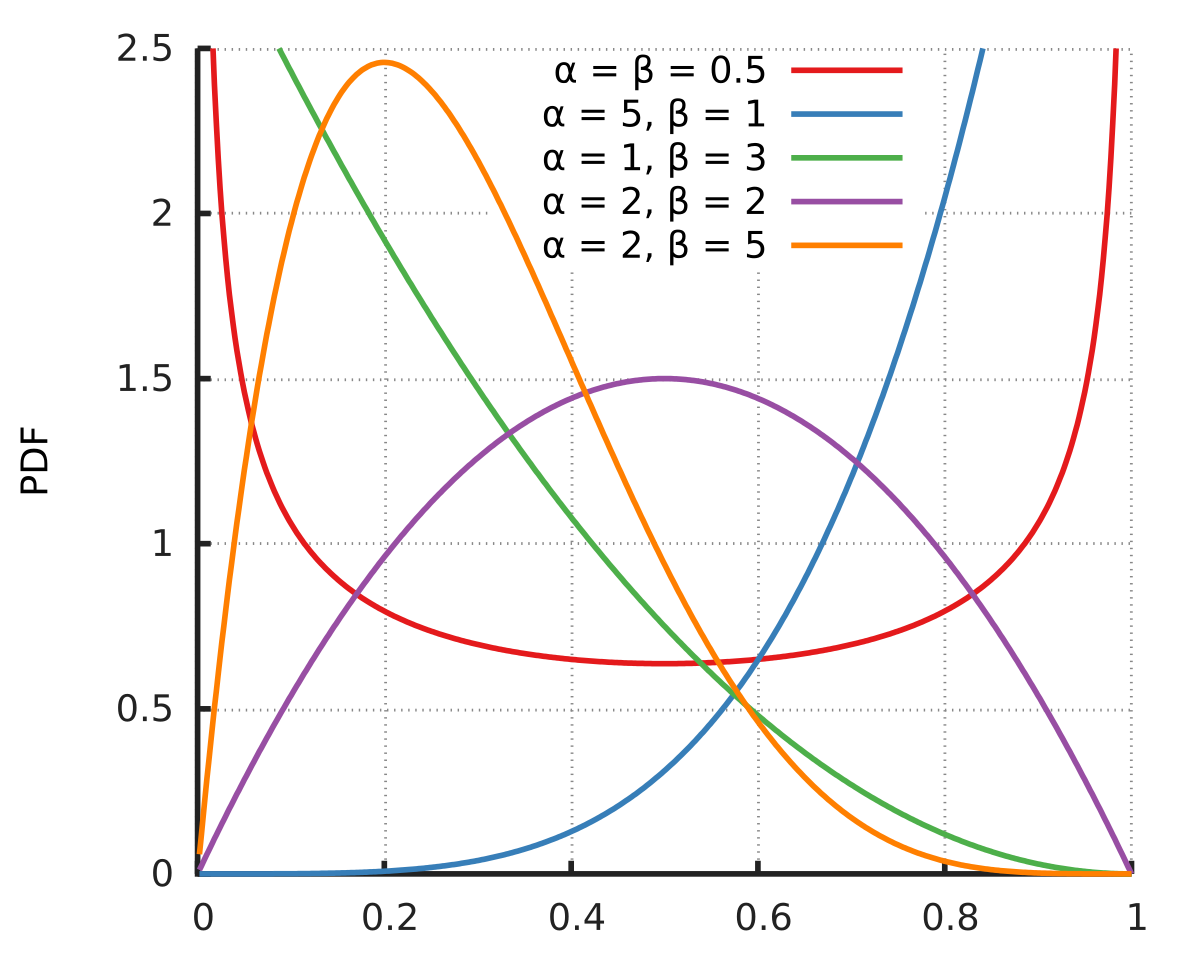
ベータ分布はこんな形をしているそうです。(wikiより)
$\alpha$, $\beta$ という二つのパラメータがありその値により形状が変化します。
これに従う乱数を生成してヒストグラムを表示すると、こんな形になってくれそうです。
乱数
BigQueryでは0~1の間の一様乱数しか生成できません。
しかし、大体の有名分布は一様乱数からそれに従う分布に変換する手法が存在するので今回はそれをBigQueryで実装します。
方針は、ユーザー定義関数を使って、ベータ分布の$\alpha$,$\beta$と生成する乱数の数を与えるとその数だけ乱数を配列で返す関数を作るようにしたいと思います。
アルゴリズムは以下の記事の基本アルゴリズムを参考に作らせてもらいました。
https://qiita.com/piyo7/items/36b19c6ea68baa2a69cd
実装したものがこちら
CREATE OR REPLACE FUNCTION math.generate_beta(a FLOAT64, b FLOAT64, n INT64) AS (
# ベータ分布に従う乱数を生成する
# https://qiita.com/piyo7/items/36b19c6ea68baa2a69cd
ARRAY(
WITH assert AS (
SELECT
IF(a > 0 AND b > 0, TRUE, ERROR('パラメータのa,bはいずれも正であることが必要です')) AS c1,
IF(n > 0, TRUE, ERROR('nは1以上です')) AS c2
)
, ab AS (
SELECT
a+b AS alpha,
IF(
math.min([a, b]) <= 1,
math.max([1/a, 1/b]),
SQRT((a+b-2)/(2*a*b-(a+b)))
) AS beta,
FROM assert
)
, abg AS (
SELECT alpha, beta,
a + (1 / beta) AS gamma
FROM ab
)
, u AS (
SELECT RAND() AS U1, RAND() AS U2
# 棄却される可能性があるので多めに作る
FROM UNNEST(GENERATE_ARRAY(0, CEIL(n * 1.5)))
)
, vw AS (
SELECT
U1, U2,
beta * LN(U1/(1-U1)) AS V,
a * EXP(beta * LN(U1/(1-U1))) AS W
FROM u, abg
)
, sampling AS (
SELECT
ROW_NUMBER() OVER () AS rank,
alpha * LN(a / (b+W)) + gamma * V - 1.3862944 < LN(U1*U1*U2) AS accept,
W / (b+W) AS X,
FROM vw, abg
)
SELECT X
FROM sampling
WHERE accept AND rank <= n
));
math.min, math.maxは与えた配列の最小値最大値を取り出す、ユーザー定義関数です。
適当に事前に作ってください。
今回のサンプリング(乱数生成)は棄却サンプリングと呼ばれるもので、生成した一様乱数と同数のサンプルが得られません。特定の条件を満たさなかったサンプルは棄却(捨てられる)されてしまいます。ですので、与えられた$n$より多めの一様乱数を生成して、余った分は捨てる戦略をとりました。1関数が再帰的に呼べるなら、必要数サンプルできるまでサンプリングし続けれるのですが、BigQueryはできなさそうなので諦めました。
というかベータ分布は棄却サンプリングしかないのかな?
表示
作ったベータ乱数生成関数からたくさん乱数を生成してヒストグラムを表示したいと思います。
配列をヒストグラムに直す関数を書きました。
CREATE OR REPLACE FUNCTION math.histogram(arr ANY TYPE, bin INT64) AS (
# 配列を値によりビンにわけ個数をカウントする
ARRAY(
WITH min_max AS (
SELECT
math.min(arr) AS x_min,
(math.max(arr) - math.min(arr)) / bin AS d,
)
, bin_range AS (
SELECT
i,
x_min + i * d AS range_left, -- それぞれのビンの範囲の左端
x_min + (i+1) * d AS range_right, -- それぞれのビンの範囲の右端
FROM UNNEST(GENERATE_ARRAY(0, bin-1)) AS i, min_max
)
, hist AS (
SELECT
i,
COUNTIF(i IS NOT NULL) AS n,
FROM UNNEST(arr) AS x, bin_range
WHERE TRUE
AND x >= range_left
AND IF(i=bin-1, x <= range_right, x < range_right)
GROUP BY i
)
SELECT AS STRUCT
range_left AS l,
range_right AS r,
IFNULL(n, 0) AS n,
FROM bin_range LEFT JOIN hist USING (i)
));
これを使って、スプレッドシートで表示してみましょう。
SELECT (l + r) / 2 AS x, n
FROM UNNEST(math.histogram(math.generate_beta(2, 5, 10000), 100))
コンソールでクエリを実行した後に、『データを探索』のボタンを押せばスプレッドシートで分析できます。
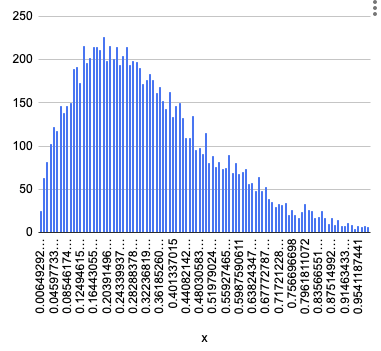
一応歪んだ山っぽくなりました。
$\alpha=2, \beta=5$なので、
こちらのオレンジ線と同じ感じになるはずですが、それっぽいようなそれっぽくないような。
アルゴリズムを変えるだけで色々な乱数を生成できるのでみなさんやってみましょう!
追記
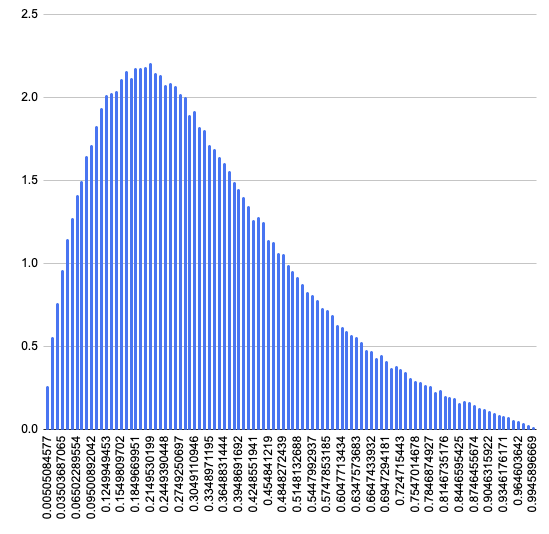
サンプル数を増やすと綺麗になりました。
しかし、正規化して比較してみると、似てるようで違う(最頻値の値が2.5付近より結構遠い、0.8以降の裾野が厚い)のでアルゴリズムの実装が間違っているかもしれません。
-
運が悪いとサンプル数が足りなくなります。 ↩