Node.js環境にてHTML文字列をHTMLにパースしたいと考えた時、どのライブラリにすべきか迷います…
ただ、メリットデメリットを並べても面白くないので「こんな前提で選択するならこれが良いと思う!」
という技術選定するつもりで記事を書いてみたいと思います!
どのようなライブラリを導入するのでも同じような思考方法で選べると思うので参考にいただけると大変嬉しく思います。
前提条件
今回は以下の条件にマッチするライブラリを選定してみたいと思います。
- パースした文字列から特定の要素を抜き出したい
- CSSレンダリングやJavaScript処理(イベントハンドリング)はできなくてもよい
- HTMLタグに付与されている属性を取得したい
- 大量な文字列を解析することを想定してパフォーマンスに優れたものがよい
- 依存関係はできるだけ少ないものを選びたい
- npmで提供されていること
今回比較するライブラリ
この記事比較するライブラリは以下の5つです。
- cheerio
- jsdom
- parse5
- fast-html-parser
- node-html-parser
特に人気でよく使われていそうな5つのライブラリを選択にしました。
結論
node-html-parserを利用する。
理由
- 要素の取得に
querySelectorAllやsetAttributeを利用でき初学者でも扱いやすい - 軽量で依存関係も少なく、パフォーマンスも良さそう
人気のparser5は依存関係がない独立のライブラリかつ、JavaScriptで実装されているのは非常に良いのですが独自のAPIがつらいのではないかと考えました。
ダウンロード数が伸びているので大丈夫かと思っていますが、更新が止まっているのが気になりました…。
ただ、node-html-parserの懸念点として、複雑なDOM構造は難しい場合があることはネックになるかもしれません…。
どのように考えて今回の結論にいたったのかを移行の文章で後述します。
よろしければ参考にしてください!
それぞれのライブラリの特徴
cheerio
- 使いやすいAPI、jQueryライク
- HTMLの解析以外にDOM操作、属性の取得や設定、ノードの挿入・削除ができる
- 長らく利用されているのでドキュメントやサポートが充足している
- パフォーマンスオーバヘッドが発生する可能性あり
- CSSのレンダリング、DOMの表示はできない
- JavaScriptの実行がサポートされていない
- Node.js環境を対象として設計されている
jsdom
- ブラウザで利用できるメソッドやプロパティが使用可能
- イベントハンドリングやスタイル操作もできる
- ブラウザと変わらないDOM環境を用意するためメモリの消費が多く、他のライブラリに比べて速度が遅い
- 依存関係もそこそこ。セットアップやや重め
parse5
- HTML5準拠。高度で正確なHTML解析がうり
- 高速で大規模なHTMLデータの解析に適している
- ブラウザ標準とは異なるDOMAPIを提供しているので多少の学習が必要
- DOM操作やイベントハンドリングなどはできない
fast-html-parser
- 軽量で高速。パフォーマンスが優れている
- 依存関係も少なくセットアップが容易
- スタイル操作や高度なDOM操作はサポートされていない
- 比較的新しく、コミュニティーサポートやドキュメントが少ない
node-html-parser
- 初学者でも扱いやすいシンプルなAPI
- 軽量で依存関係も少なく、パフォーマンスも良好
- イベントハンドリングやJavaScriptの実行はできない
- 複雑なHTML構造に対して対処が難しい場合もある
npmパッケージのダウンロード数などを時系列で比較
npmtrendsでパッケージのダウンロード数などを確認してみます。
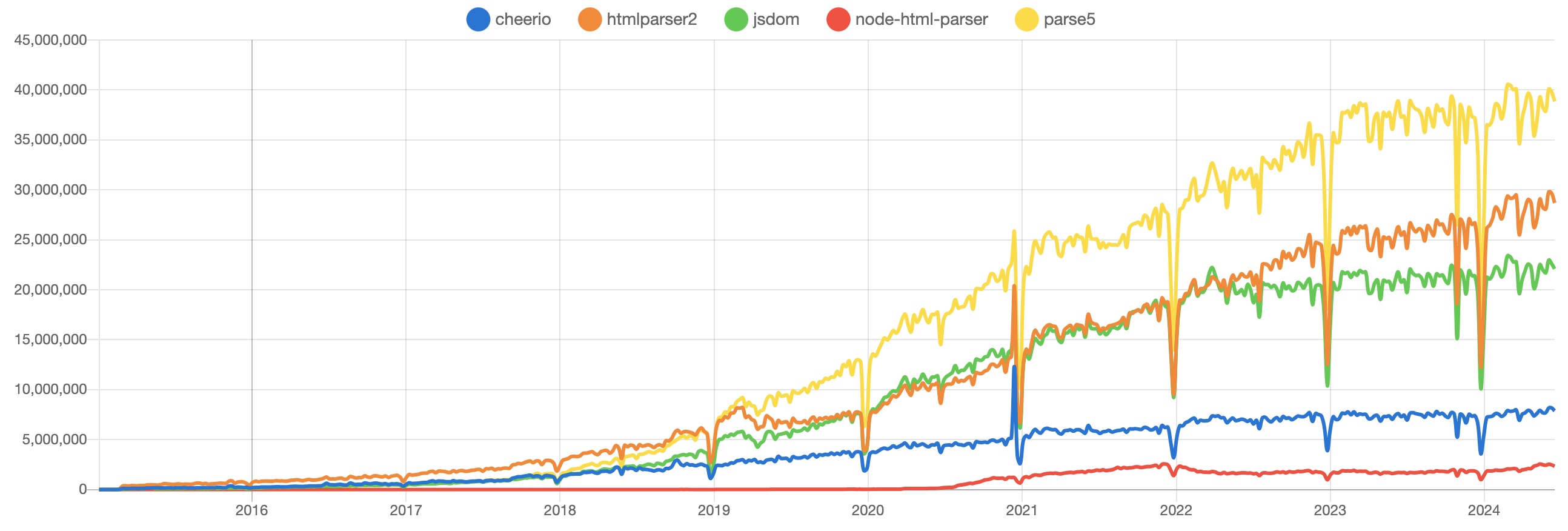
ダウンロード数
全期間で確認すると「Parse5」が一番ダウンロードされているようです。
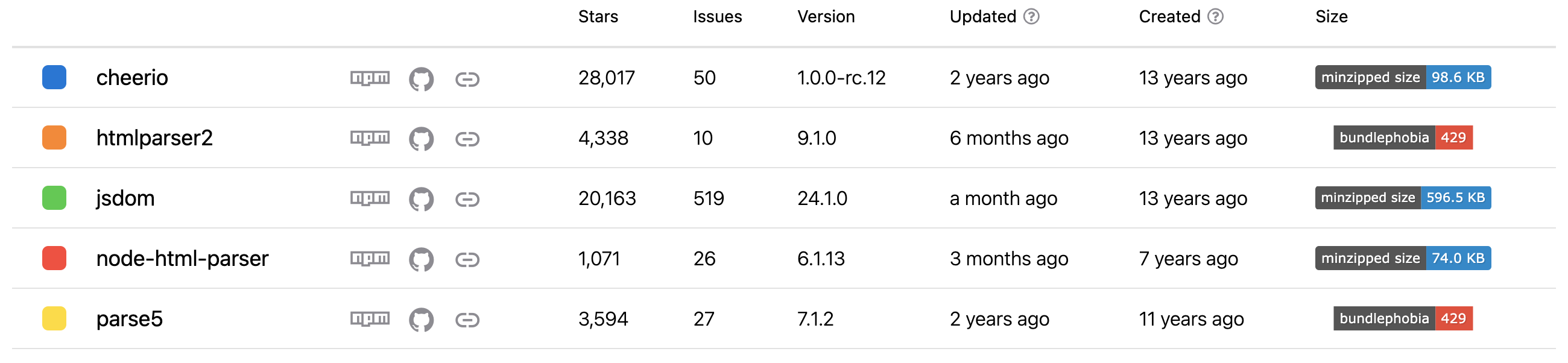
スターの数
スター数の一番はcheerioですが、更新は2年前で止まっているようです。
どのライブラリを選ぶと良いか?
ドキュメントの充足しているか?
人気が高いものや昔から利用されているものは、ドキュメントが充足していると考えられます。
また、調べれば実装例も豊富に存在することが考えられるので様々な要件に対応しやすい環境であると考えます。
どれくらいの期間利用するのか?
技術選定においてどれくらいの期間利用するのかは重要だと思います。
長い年月利用することを見込むのであればライブラリの更新頻度は重要なファクターだと言えます。
人気のライブラリだとしても更新が年単位で止まっているのは注意が必要です…。
ライブラリが内部で他のライブラリに依存している場合、他ライブラリの破壊的変更によって現在の処理が動作しなくなる可能性もあります。
今後3〜5年先を見越しての技術選定ならライブラリの更新頻度は高い方が良いと考えています。
2年前で更新が止まっているのにもかかわらず現在でも利用されている事実から「安定している」と捉えることも可能です。
短期間の一時的な利用であれば問題ないと判断するのも良いかもしれません。
保守性は高いか?
- ライブラリが他のライブラリに依存していないか
- 編集コストや学習コストは高くないか
その後の運用や変化に対応していくにはどらだけ楽に運用できるか?や変化に対してライブラリの変更ができるように依存関係は少ないに越したことはありません!
現在のメンバーだけでなく、後になって参画するメンバーにとってより良い選択ができる状態を保つことができるようなライブラリを選べるとベストです!
パフォーマンスはどうか?
解析するデータ量によって判断できると思います。
例えば、HeadressCMSから取得できる記事のHTML文字列を解析する場合日本語だけで10000文字を超える長い記事が存在するもあるでしょう。
キャッシュを利用することで軽減できる部分もあると思いますが、大きいデータの解析を見込んでいるならそれを踏まえてライブラリを選ぶのが良さそうです!
解析処理を走らせる頻度が多いならそちらも判断の材料として加えると良いと考えます。
オーバーテクノロジーなライブラリを選択していないか?
大は小を兼ねる的な考えで、JavaScriptの操作はする予定がないのにできるライブラリを選んでしまうのはやめておこう。ということが言いたいです。
JavaScriptの操作ができる代わりに、パフォーマンスが低いなど必ず何かをトレードオフにしているはずなので十分に検討しましょう…
【まとめ】HTML文字列を解析するライブラリどれにする?
今回前提条件に挙げたのはすごくシンプルなものでした。
実際のプロジェクトはさらに複雑な要件がたくさん上がってくると思いますし、その中から関係者で取捨選択する必要があると思います。
技術選定は、導入後の運用、チームの状況、市場環境、期間様々な視点から総合的に判断する必要があり難しい選択です…。
未来を見通すことはできないので、できるだけ多くの情報を集めてください。
その上で、有識者から意見を募り決定できると現時点の最良の選択にできるのではと考えています!