観光や展示の文脈で、記念品や小物を3Dモデルとして扱うケースを考えると、モデル生成そのものより先に、ファイル管理が問題になります。
1個だけなら適当な名前でも困りません。しかし、展示品、地域小物、AR用素材、ブログ用検証モデルが増えてくると、どの画像から作ったのか、何に使ってよいのか、どの形式で出力したのかが分からなくなります。
最初に決めたい命名規則
Hi3D などで画像から3Dモデルを作る前に、入力画像、生成モデル、確認用スクリーンショットの名前をそろえておくと後で楽です。
tourism_item_001_input.jpg
tourism_item_001_model.glb
tourism_item_001_model.stl
tourism_item_001_preview_front.png
tourism_item_001_preview_back.png
tourism_item_001_meta.json
メタデータに残す項目
| 項目 | 目的 |
|---|---|
| id | 画像、モデル、スクリーンショットを紐づける |
| source_image | 元画像のファイル名を残す |
| object_type | souvenir、prop、exhibitなどを分類する |
| usage | blog、AR、prototype、printなど用途を分ける |
| rights_note | 自分で撮影、許諾済み、要確認などを記録する |
| exports | GLB、OBJ、STLなど出力形式を残す |
JSON manifestの例
{
"id": "tourism_item_001",
"title": "small ceramic souvenir house",
"source_image": "tourism_item_001_input.jpg",
"object_type": "souvenir",
"usage": ["blog", "prototype"],
"rights_note": "self-shot original object, no logo",
"generated_with": "image-to-3d workflow",
"exports": {
"glb": "tourism_item_001_model.glb",
"stl": "tourism_item_001_model.stl"
},
"review": {
"scale_checked": false,
"texture_checked": true,
"print_ready": false
}
}
CSVで一覧化する
import json
from pathlib import Path
import pandas as pd
rows = []
for path in Path("models").glob("*_meta.json"):
data = json.loads(path.read_text(encoding="utf-8"))
rows.append({
"id": data["id"],
"title": data["title"],
"object_type": data["object_type"],
"usage": ",".join(data["usage"]),
"rights_note": data["rights_note"],
"glb": data["exports"].get("glb", ""),
"stl": data["exports"].get("stl", ""),
"texture_checked": data["review"]["texture_checked"],
"print_ready": data["review"]["print_ready"],
})
df = pd.DataFrame(rows)
df.to_csv("model_catalog.csv", index=False, encoding="utf-8-sig")
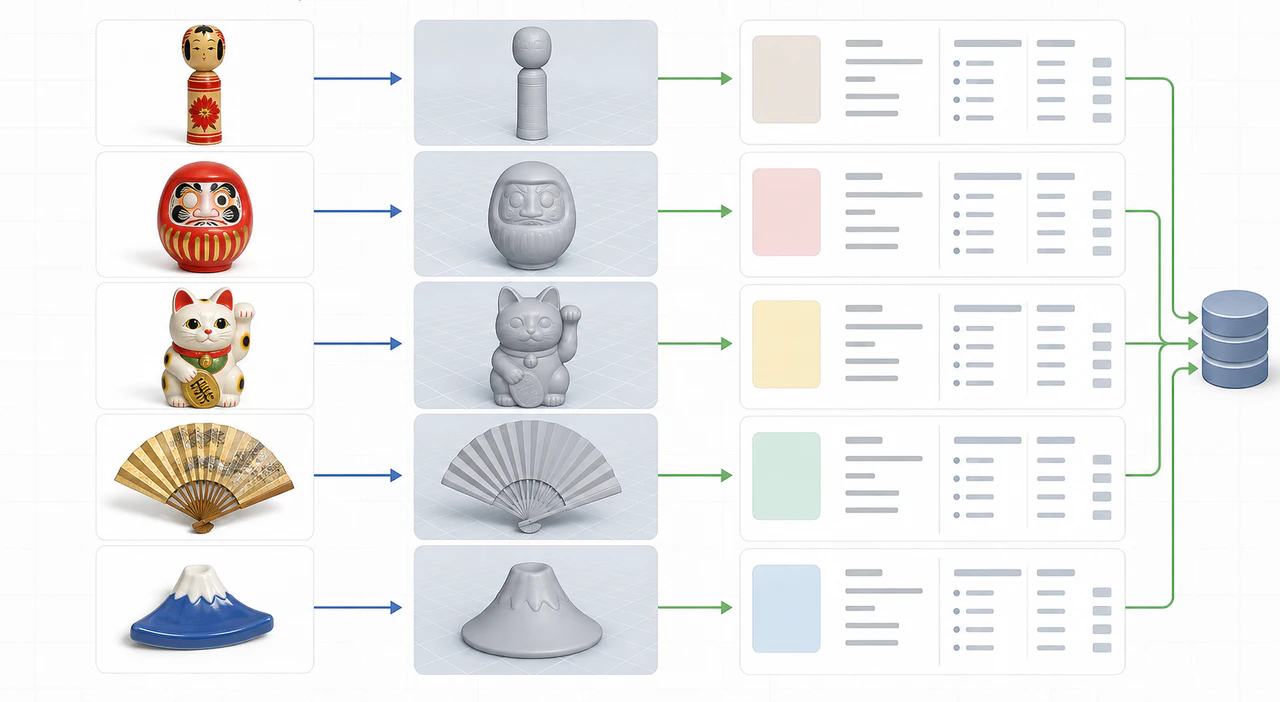
3Dモデル生成AI で素材を作ると、出力そのものに注目しがちです。ただ、後で使える資産にするには、名前とメタデータを残すことも同じくらい重要です。
まとめ
観光や展示向けの3D小物は、単発の実験で終わらせるなら管理は不要です。しかし、数が増えるなら、生成前に命名規則とメタデータを決めておくと後工程がかなり楽になります。