はじめに
BEENOS株式会社の田邉です。
AIXという部署で全社のAI活用の推進とプロダクトへのAI導入を推進しています。
最近は、LLMOps(精度監視)などに特に興味があります。
本記事では、本番運用においてセルフホスティングしたDifyで、月間70万リクエストを捌くまでに直面した技術的課題とその解決策を共有します。Difyの導入を検討されている企業や、すでに運用中で大規模トラフィックに課題を感じている方の参考になれば幸いです。
Dify導入の背景と環境
BEENOSの越境EC事業では、特定の定型作業が大量かつ繰り返し発生しており、従来のシステムでの自動化が難しい領域でした。
この業務は複数のステップで成り立っていたため、ワークフロー形式で実装できるDifyを採用しました。また、セキュリティやバージョン管理の観点から、セルフホスティング環境での本番導入を決断しました。
構成
- 環境: AWS LightSail(ステージング環境と本番環境の2つを構築)
-
スペック:
- 32 GB メモリ
- 8 vCPU
- 640 GB SSD ディスク
- 7 TB データ転送
- 月額 164ドル
無事にセルフホスティング環境を構築し、本番運用を開始しました。しかし、実際の業務トラフィックが流れ始めると、想定していなかった様々な問題に直面することになります。
月間70万リクエスト運用における様々な技術的課題
運用開始当初は月数万リクエスト程度でした。この頃はワークフローの開発も修正も早く、Difyの生産性の高さを実感していました。
しかし、運用開始から約1年後月間数十万リクエストに到達した頃から、様々な問題が顕在化し始めました。突然500エラーが返ってきたり、タイムアウトが頻発したりするようになりました。
原因を特定するため、私たちはGrafanaによる監視体制を構築しました。そこで見えてきたのは、CPU・メモリ・ディスク容量という3つの課題でした。
CPU問題
最初に直面したのがCPUのボトルネックでした。
本番運用しているワークフローは1回の実行に約15秒かかり、ピーク時には1分あたり27リクエストほどが流入していて、タイムアウトが頻発していました。
Grafanaのメトリクスを確認すると、CPU使用率が30%付近で頭打ちになっていることに気づきました。
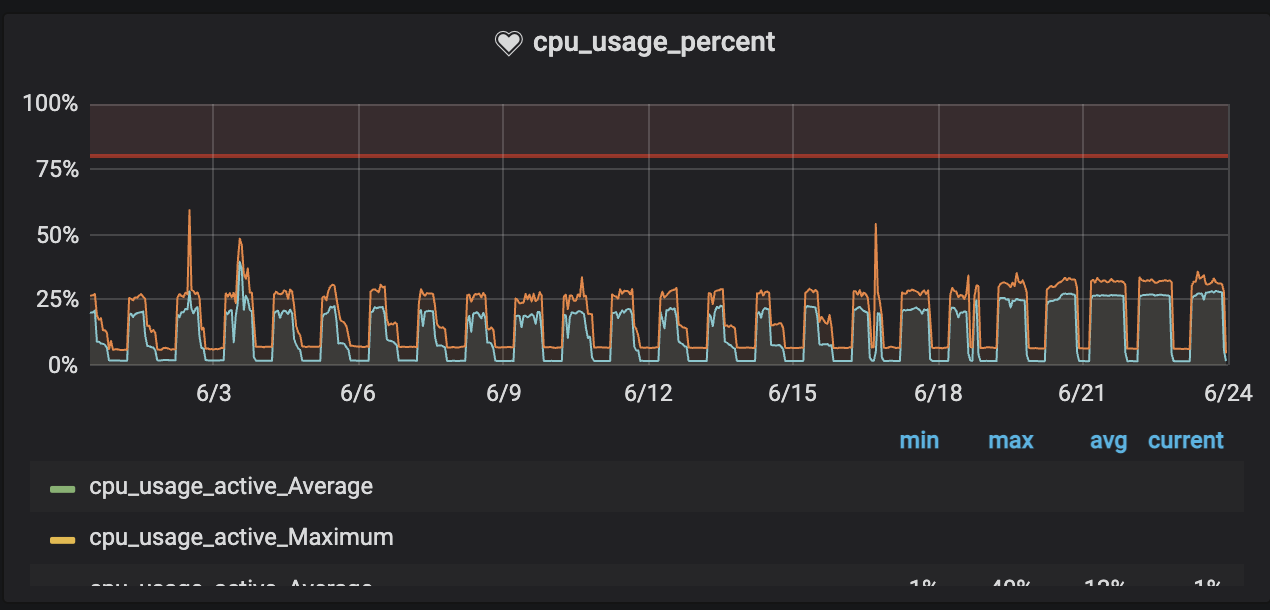
「CPUに余裕があるのに、なぜリクエストを捌けないのか?」
調査を進めると、原因はGunicornのワーカー数にありました。Difyのデフォルト設定では、SERVER_WORKER_AMOUNT=1になっています。デフォルトの設定では1つのワーカーでしかリクエストを処理できていなかったのです。
Difyの.env.exampleには以下のようなコメントがあります:
# The number of API server workers, i.e., the number of workers.
# Formula: number of cpu cores x 2 + 1 for sync, 1 for Gevent
# Reference: https://docs.gunicorn.org/en/stable/design.html#how-many-workers
このコメントによると、ワーカー数の推奨値は CPUコア数 × 2 + 1 とされています。8 vCPUの場合、計算上は17ワーカーが最適値ですが、余裕を持ってSERVER_WORKER_AMOUNT=12に設定しました。
この変更により、CPU使用率は70%まで使えるようになり、リクエストを安定して捌けるようになりました。
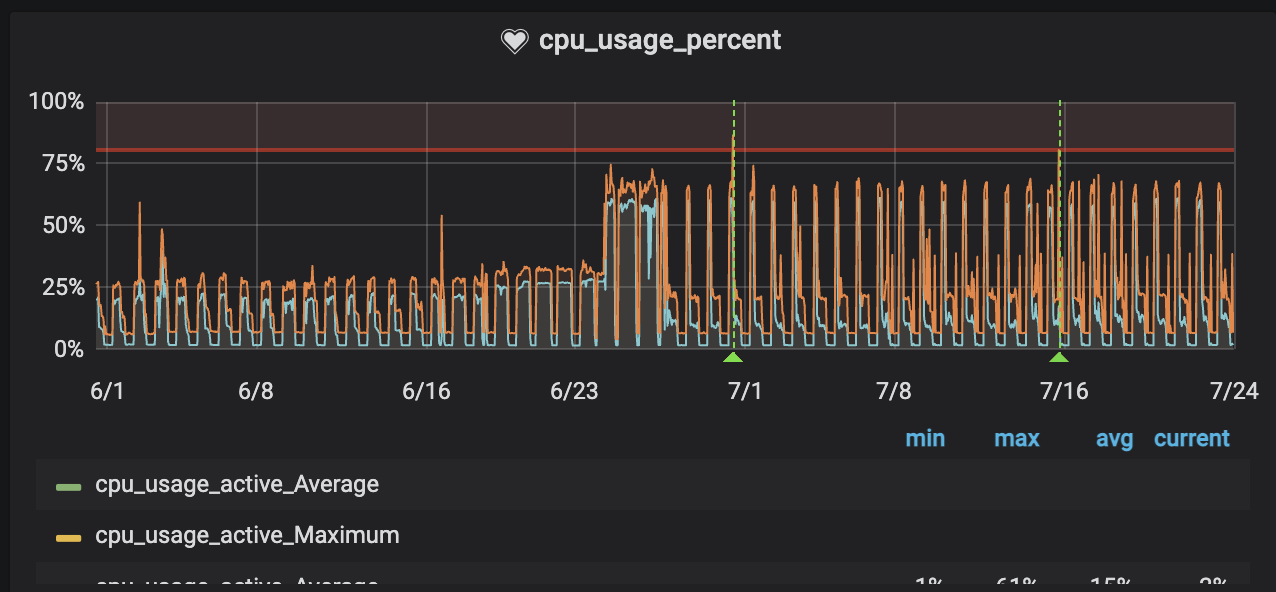
DBへのアクセス数の問題
Gunicornのワーカー数を増やしたことで、CPUのボトルネックは解消しましたが、今度はデータベースへの接続数が不足して下記のエラーが起きるようになりました。
(psycopg2.OperationalError) FATAL: sorry, too many clients already
(Background on this error at: https://sqlalche.me/e/20/e3q8)
DifyはPostgreSQLをデータベースとして使用していますが、デフォルト設定のPOSTGRES_MAX_CONNECTIONS=100では接続数が足りなかったのでPOSTGRES_MAX_CONNECTIONS=2048に上げたところエラーが解消しました。
メモリ問題
CPUの問題を解決した後、次に立ちはだかったのがメモリの問題でした。
Grafanaで監視していると、メモリ使用率が時間経過とともに徐々に上昇し、最終的にはシステムが不安定になることがありました。Dockerコンテナを再起動すると使用率は元に戻ります。典型的なメモリリークのパターンです。
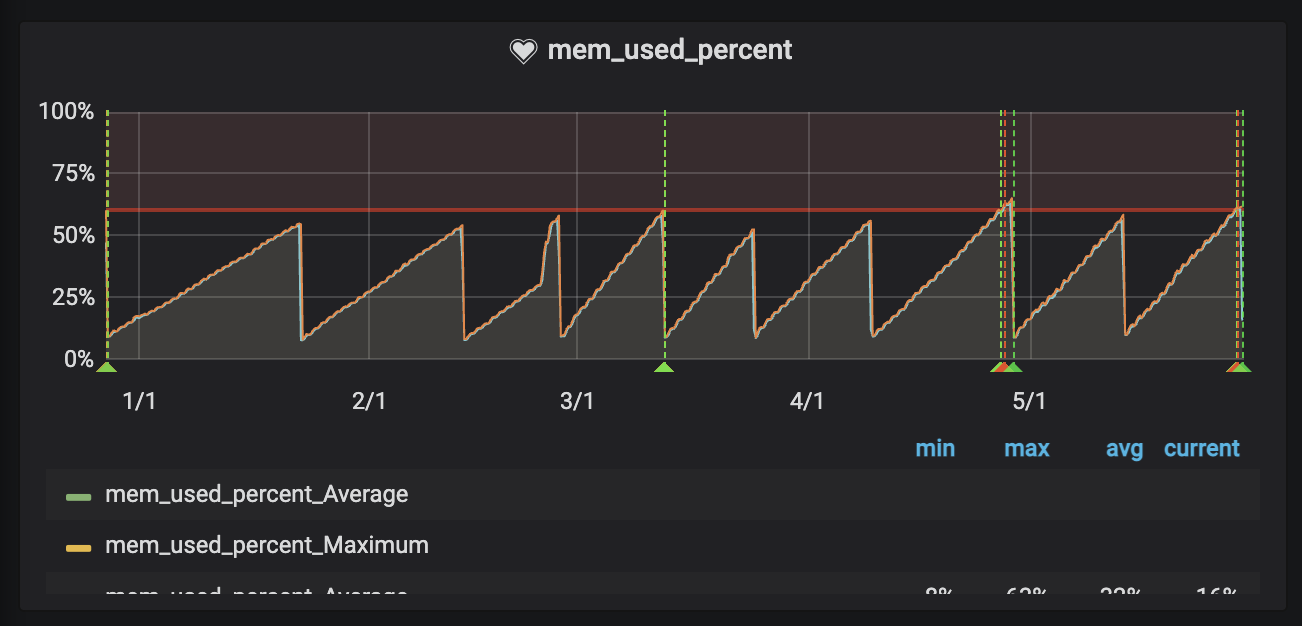
根本原因を特定するため、まずGunicornのMAX_REQUEST設定を試してみました。これはワーカープロセスが一定回数リクエストを処理したら自動的に再起動する設定ですが、効果は得られませんでした。
現在も根本的な原因は特定できていません。理想的な解決策ではないことは承知の上で、毎日20:00(業務終了後)にDockerコンテナを再起動するShellスクリプトをCronで実行するという運用でカバーしています。
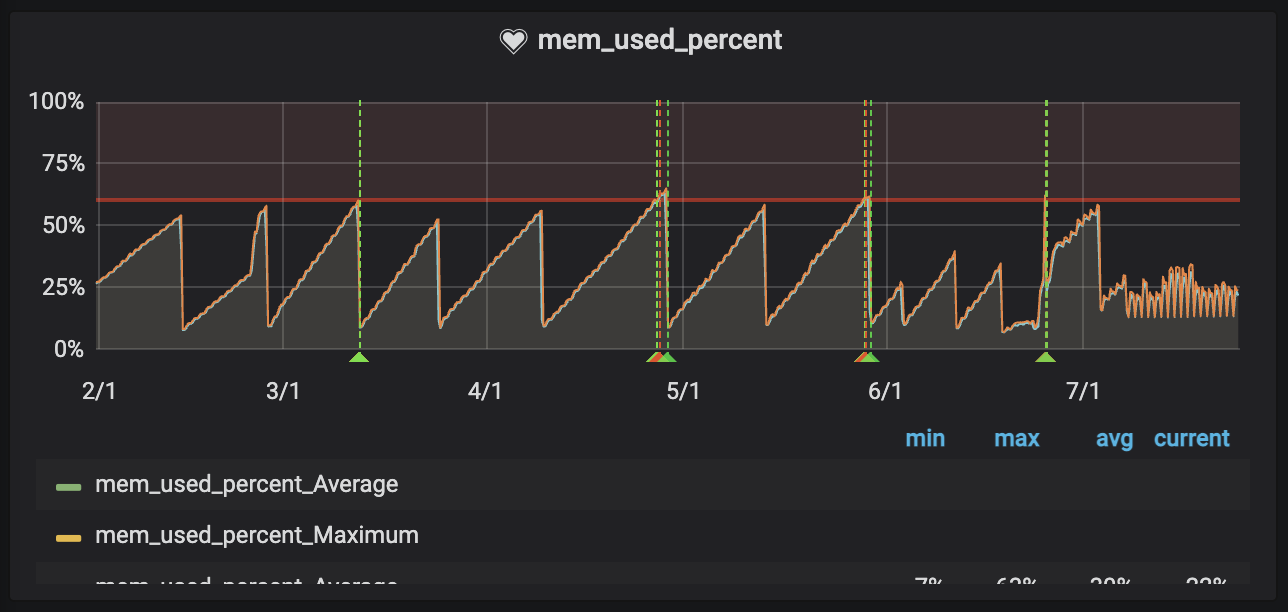
もし同じような問題に直面された方で、より根本的な解決策をご存知の方がいらっしゃいましたら、ぜひご教示いただけると幸いです。
ディスク容量問題
CPU、メモリと問題を乗り越えてきましたが、最後に待ち構えていたのがディスク容量の問題でした。
Grafanaでディスク使用率を監視していると、日に日に着実に上昇していることに気づきました。このペースでいけば、いずれ100%に到達し、システムが完全に停止してしまう可能性がありました。
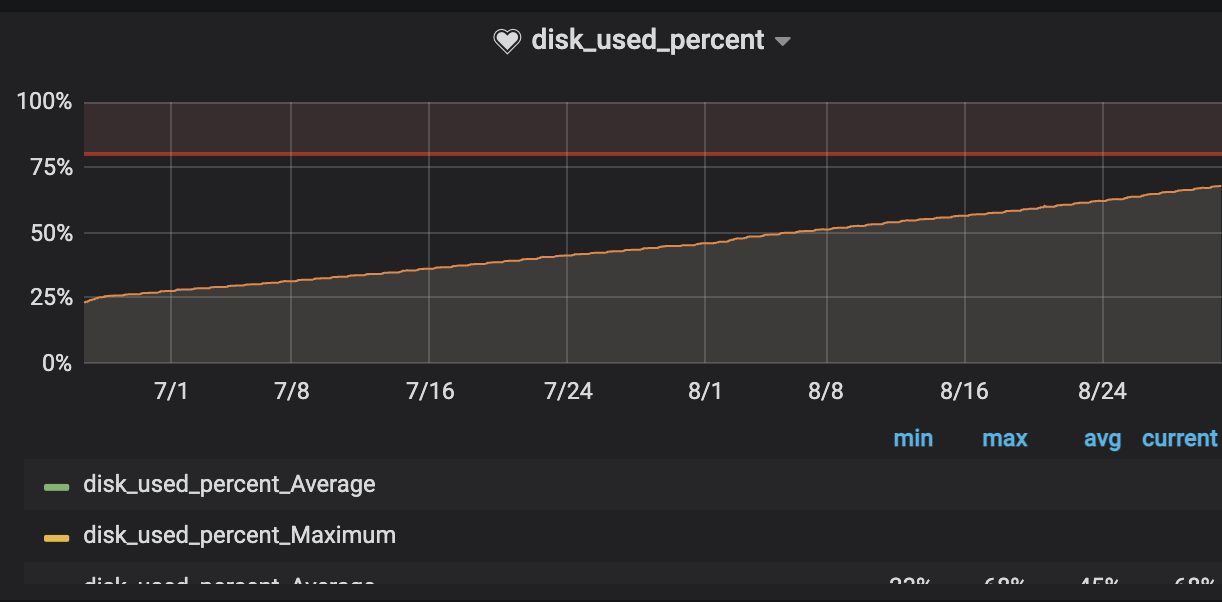
急いで原因を調査したところ、特定のテーブルが膨大な容量を消費していることが判明しました。
| テーブル名 | レコード数 | 容量 |
|---|---|---|
| workflow_node_executions | 49,091,020 | 162 GB |
| workflow_runs | 1,525,500 | 119 GB |
| workflow_app_logs | 1,527,666 | 376 MB |
| upload_files | 793,257 | 312 MB |
| embeddings | 1,415 | 40 MB |
| workflow_node_execution_offload | 45,652 | 10 MB |
特に容量を圧迫していたのは、以下の2つのテーブルでした:
workflow_runsworkflow_node_executions
中でも最も問題だったのが workflow_node_executions テーブルです。このテーブルは、ワークフローの各ノードの実行ごとにレコードが生成されます。私たちのワークフローは約60ステップで構成されているため、単純計算で1ヶ月に4,200万レコードが増加していく計算になります。
なぜこれほど容量が増えるのか
Difyではノードの実行ごとのログを見れる機能があるため、各ノードのinputとoutputがTEXT型のカラムにそのまま保存される設計になっています。
例えば、以下のようなデータがノード間で受け渡されると、これがそのままDBに保存されます:
{
"title": "\u30a8\u30a2\u30ea\u30fc\u30b3\u30c3\u30c8\u30f3...",
"description": "\u30a8\u30a2\u30ea\u30fc\u30b3\u30c3\u30c8\u30f3...",
...
}
※日本語はUnicodeエスケープシーケンス(\u30a8のような形式)でエンコードされて保存されるため、データサイズがさらに膨らみます。
ディスク使用率が急激に増えた原因は、ワークフロー内で容量の大きいマスターデータを扱っていたことでした。約5,000行にも及ぶマスターデータをコードノードで定義してoutputし、他のノードでinputとして受け渡していました。このマスターデータがノード実行ごとにDBに保存されるため、ディスク容量が爆発的に増加していました。
現状の対応
この問題に対して、私たちは2つのアプローチで対応しています。
1. 古いログの定期削除
まず、過去のログデータを定期的に削除するShellスクリプトをCronで実行しています。1ヶ月分のログを残して、それ以前のデータは毎日削除する運用です。
幸いなことに、Difyのレスポンスログは社内システム側でも保存しているため、Dify側のログが消えてもクリティカルな問題にはなりません。あくまでDify上でのデバッグ用のログと割り切っています。
2. ワークフローの設計を見直す
-
コードノード内で完結させる: 大容量のマスターデータを定義する必要がある場合、コードノード内で定義してそのノード内で処理を完結させ、inputやoutputには渡さないようにする
-
データを分割する: どうしてもマスターデータをノード間で受け渡す必要がある場合は、マスターデータを分割し、条件分岐を使って実際に読み込むデータを物理的に少なくする
これらの対応により、現在は安定した運用ができています。ただし、Difyの仕様上ノード実行ログが全て保存されるのは変わらないため、大規模運用では常にディスク容量に気を配る必要があります。
まとめ
以上が、Difyをセルフホスティングして月間70万リクエストを捌く中で、試行錯誤してきたリアルな運用の記録です。
CPU、メモリ、ディスク容量といった課題に応急処置的な対応を重ねてきており、今後も改善の余地は多く残されています。それでも、大規模な業務自動化を実現できた成果は、これらの苦労を上回る価値があると感じています。
Difyで大量のリクエストを捌く運用を検討されている方の参考になれば幸いです。また、より良い解決策をご存知の方がいらっしゃいましたら、ぜひコメント等でご教示いただけますと幸いです。
Wanted!
BEENOSグループでは一緒に働いて頂けるエンジニアを強く求めております!
少し気になった方は、社内の様子や大事にしていることなどをThe BEENOSにて発信しておりますので、是非ご覧ください。
とても気になった方はこちらでも求人を公開しておりますので、お気軽にご応募ください!
「自分に該当する職種がないな...?」と思った方は オープンポジション としてご応募頂けると大変嬉しく思います ![]()
世界で戦えるサービスを創っていきたい方、是非是非ご連絡ください!よろしくお願い致します!!
