対象
SSDとかYoloV2開発者.
DeepLearningで何ができるのか知りたい方.
1. YoloV3
現状最も強力な物体検出系AIです.
YoloV2の改良版で,Yolov2よりも層が深くResnetのようになっています.
その他さまざまな改良点がありますがおいおい.
YoloV3 Strong~ 以下ネットワーク構造
layer filters size input
0 conv 32 3 x 3 / 1 416 x 416 x 3
1 conv 64 3 x 3 / 2 416 x 416 x 32
2 conv 32 1 x 1 / 1 208 x 208 x 64
3 conv 64 3 x 3 / 1 208 x 208 x 32
4 res 1 208 x 208 x 64
5 conv 128 3 x 3 / 2 208 x 208 x 64
6 conv 64 1 x 1 / 1 104 x 104 x 128
7 conv 128 3 x 3 / 1 104 x 104 x 64
8 res 5 104 x 104 x 128
9 conv 64 1 x 1 / 1 104 x 104 x 128
10 conv 128 3 x 3 / 1 104 x 104 x 64
11 res 8 104 x 104 x 128
12 conv 256 3 x 3 / 2 104 x 104 x 128
13 conv 128 1 x 1 / 1 52 x 52 x 256
14 conv 256 3 x 3 / 1 52 x 52 x 128
15 res 12 52 x 52 x 256
16 conv 128 1 x 1 / 1 52 x 52 x 256
17 conv 256 3 x 3 / 1 52 x 52 x 128
18 res 15 52 x 52 x 256
19 conv 128 1 x 1 / 1 52 x 52 x 256
20 conv 256 3 x 3 / 1 52 x 52 x 128
21 res 18 52 x 52 x 256
22 conv 128 1 x 1 / 1 52 x 52 x 256
23 conv 256 3 x 3 / 1 52 x 52 x 128
24 res 21 52 x 52 x 256
25 conv 128 1 x 1 / 1 52 x 52 x 256
26 conv 256 3 x 3 / 1 52 x 52 x 128
27 res 24 52 x 52 x 256
28 conv 128 1 x 1 / 1 52 x 52 x 256
29 conv 256 3 x 3 / 1 52 x 52 x 128
30 res 27 52 x 52 x 256
31 conv 128 1 x 1 / 1 52 x 52 x 256
32 conv 256 3 x 3 / 1 52 x 52 x 128
33 res 30 52 x 52 x 256
34 conv 128 1 x 1 / 1 52 x 52 x 256
35 conv 256 3 x 3 / 1 52 x 52 x 128
36 res 33 52 x 52 x 256
37 conv 512 3 x 3 / 2 52 x 52 x 256
38 conv 256 1 x 1 / 1 26 x 26 x 512
39 conv 512 3 x 3 / 1 26 x 26 x 256
40 res 37 26 x 26 x 512
41 conv 256 1 x 1 / 1 26 x 26 x 512
42 conv 512 3 x 3 / 1 26 x 26 x 256
43 res 40 26 x 26 x 512
44 conv 256 1 x 1 / 1 26 x 26 x 512
45 conv 512 3 x 3 / 1 26 x 26 x 256
46 res 43 26 x 26 x 512
47 conv 256 1 x 1 / 1 26 x 26 x 512
48 conv 512 3 x 3 / 1 26 x 26 x 256
49 res 46 26 x 26 x 512
50 conv 256 1 x 1 / 1 26 x 26 x 512
51 conv 512 3 x 3 / 1 26 x 26 x 256
52 res 49 26 x 26 x 512
53 conv 256 1 x 1 / 1 26 x 26 x 512
54 conv 512 3 x 3 / 1 26 x 26 x 256
55 res 52 26 x 26 x 512
56 conv 256 1 x 1 / 1 26 x 26 x 512
57 conv 512 3 x 3 / 1 26 x 26 x 256
58 res 55 26 x 26 x 512
59 conv 256 1 x 1 / 1 26 x 26 x 512
60 conv 512 3 x 3 / 1 26 x 26 x 256
61 res 58 26 x 26 x 512
62 conv 1024 3 x 3 / 2 26 x 26 x 512
63 conv 512 1 x 1 / 1 13 x 13 x1024
64 conv 1024 3 x 3 / 1 13 x 13 x 512
65 res 62 13 x 13 x1024
66 conv 512 1 x 1 / 1 13 x 13 x1024
67 conv 1024 3 x 3 / 1 13 x 13 x 512
68 res 65 13 x 13 x1024
69 conv 512 1 x 1 / 1 13 x 13 x1024
70 conv 1024 3 x 3 / 1 13 x 13 x 512
71 res 68 13 x 13 x1024
72 conv 512 1 x 1 / 1 13 x 13 x1024
73 conv 1024 3 x 3 / 1 13 x 13 x 512
74 res 71 13 x 13 x1024
75 conv 512 1 x 1 / 1 13 x 13 x1024
76 conv 1024 3 x 3 / 1 13 x 13 x 512
77 conv 512 1 x 1 / 1 13 x 13 x1024
78 conv 1024 3 x 3 / 1 13 x 13 x 512
79 conv 512 1 x 1 / 1 13 x 13 x1024
80 conv 1024 3 x 3 / 1 13 x 13 x 512
81 conv 255 1 x 1 / 1 13 x 13 x1024
82 detection
83 route 79
84 conv 256 1 x 1 / 1 13 x 13 x 512
85 upsample 2x 13 x 13 x 256
86 route 85 61
87 conv 256 1 x 1 / 1 26 x 26 x 768
88 conv 512 3 x 3 / 1 26 x 26 x 256
89 conv 256 1 x 1 / 1 26 x 26 x 512
90 conv 512 3 x 3 / 1 26 x 26 x 256
91 conv 256 1 x 1 / 1 26 x 26 x 512
92 conv 512 3 x 3 / 1 26 x 26 x 256
93 conv 255 1 x 1 / 1 26 x 26 x 512
94 detection
95 route 91
96 conv 128 1 x 1 / 1 26 x 26 x 256
97 upsample 2x 26 x 26 x 128
98 route 97 36
99 conv 128 1 x 1 / 1 52 x 52 x 384
100 conv 256 3 x 3 / 1 52 x 52 x 128
101 conv 128 1 x 1 / 1 52 x 52 x 256
102 conv 256 3 x 3 / 1 52 x 52 x 128
103 conv 128 1 x 1 / 1 52 x 52 x 256
104 conv 256 3 x 3 / 1 52 x 52 x 128
105 conv 255 1 x 1 / 1 52 x 52 x 256
106 detection
2.改良点
・Softmax関数のを廃止
softmax関数の代わりにロジスティック回帰を用いて精度向上
・異なるスケールに対応
SSDの構造に似ていて,特徴マップと,それ以降の特徴マップをアップサンプリングしてマージすることによって意味のある特徴マップを作成する.
・勾配の消失に対する対策
ResNet構造を使用し,勾配の消失を防いでいる.
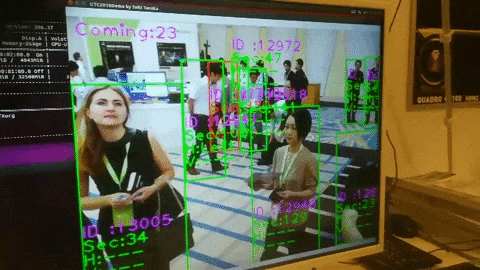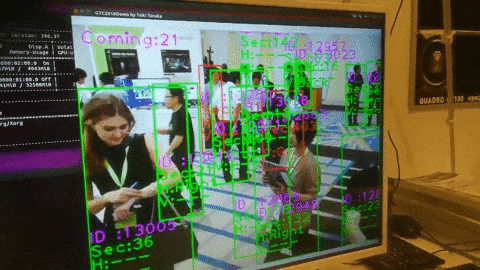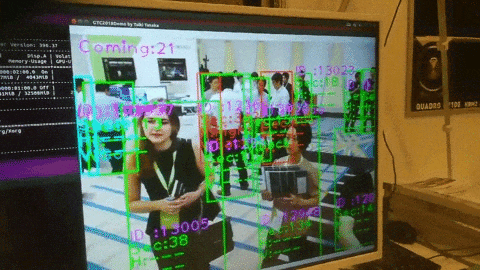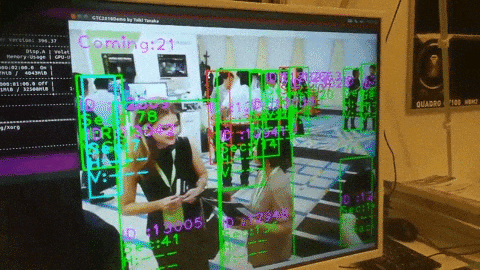
3.カメラ画像から検出する
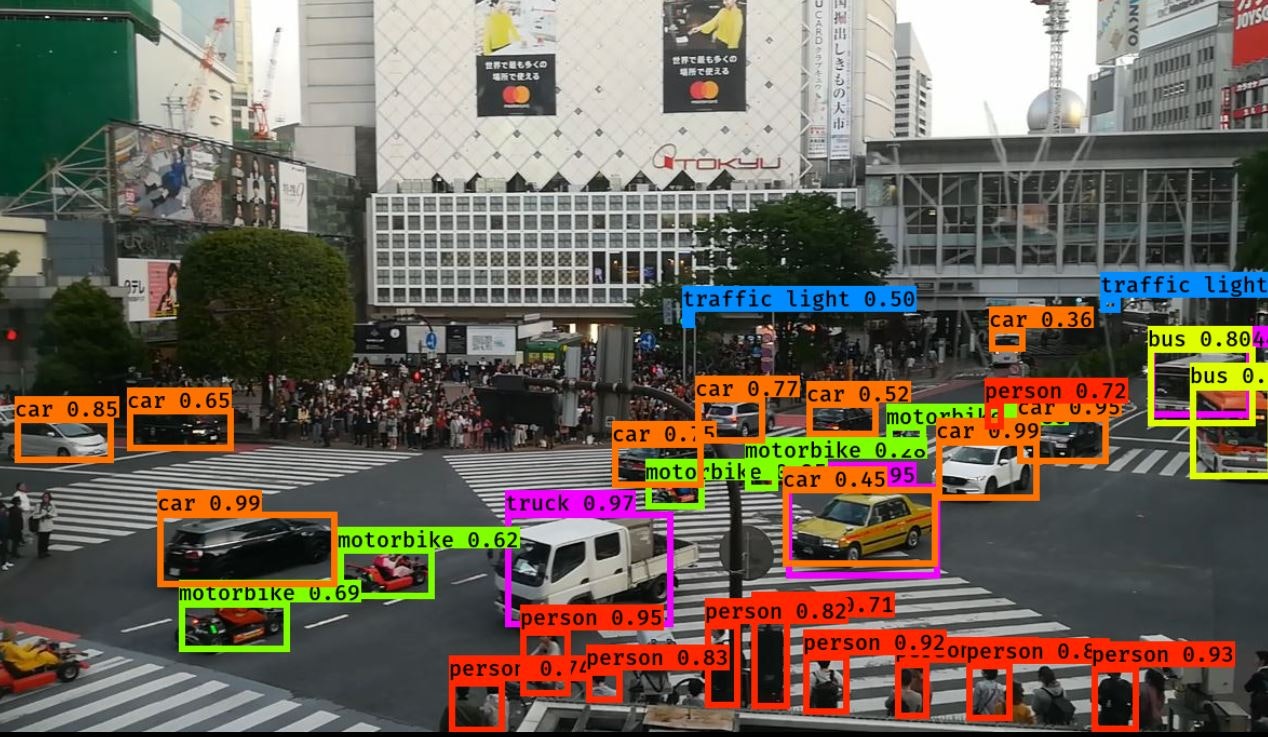
〇リオカートはモーターバイクか
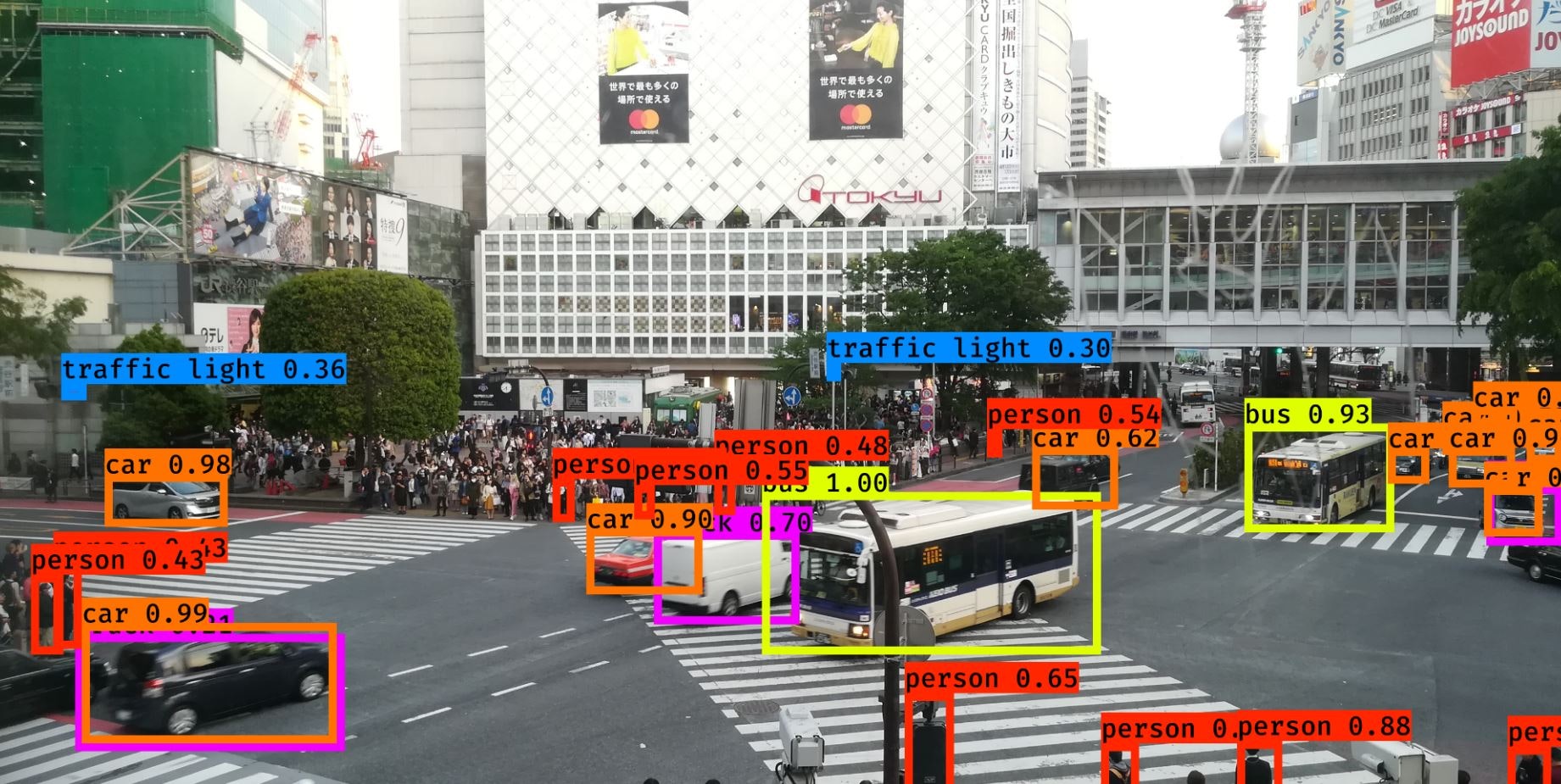
信号灯も検出できてる.
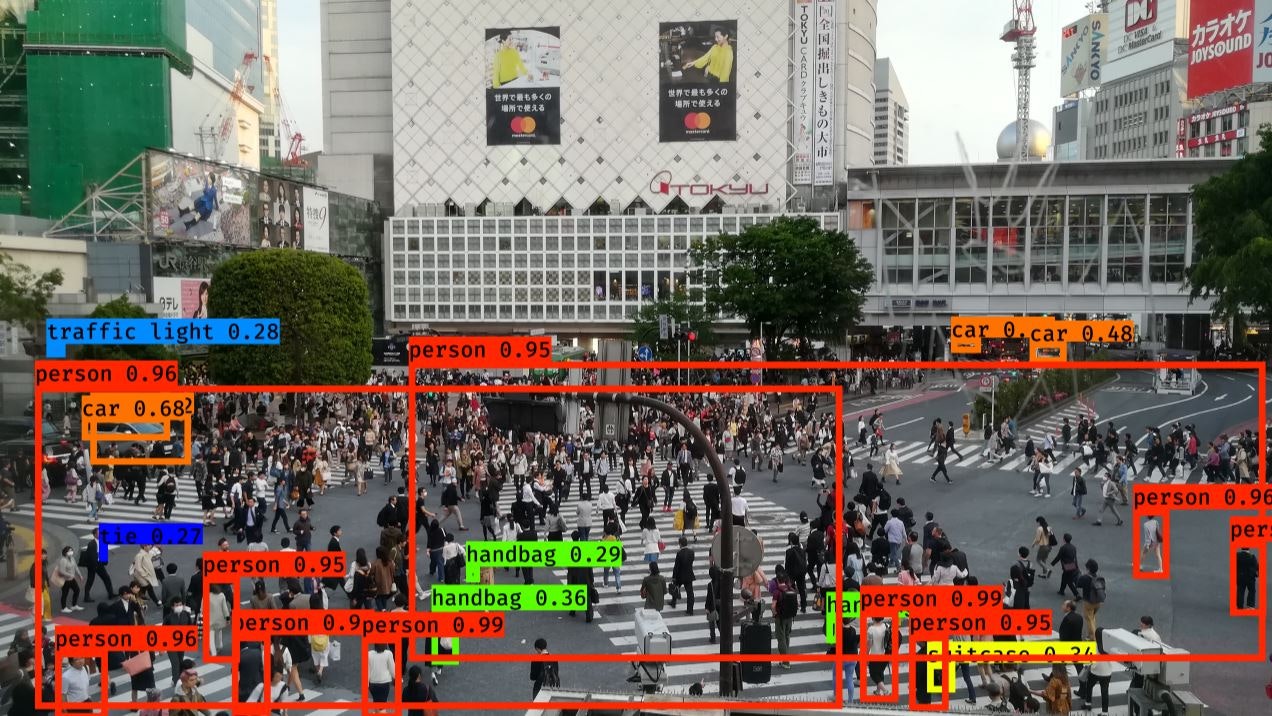
人が多すぎて一色単にされている.
動画から検出

320だと10fps
608だと5fpsくらいですね.(GTX1080×1)
3.終わりに
研究者の方⇒PullRequest大歓迎です!
*企業の方⇒お仕事待ってます!*
4.参考
https://pjreddie.com/darknet/yolo/
https://pjreddie.com/media/files/papers/YOLOv3.pdf
https://qiita.com/yampy/items/7a705acf4c6899bc11c7
5.GTC2018でデモブース出してきた
とある企業様からお仕事を頂きまして~