対象
Faster-RCNN,SSD,Yoloなど物体検出手法についてある程度把握している方.
VGG16,VGG19,Resnetなどを組み込むときの参考が欲しい方.
自作のニューラルネットを作成している方.
1.FeatureFusedSSDとは
限られた解像度の中で小さい物体を検出するというタスクは非常に難しいことで,速度を犠牲にして精度を上げてきたが,FSSDでは大きく速度を落とさず小さい物体検出を高精度で行う.FSSDとはSSDの複数の階層の畳み込み層の特徴マップを融合することによって文脈情報を付加させもので,参考文献1)の論文によるとDSSDのFPSが29.4なのに対して,FSSDではFPSが43らしい.
モデルは以下のようになっている.
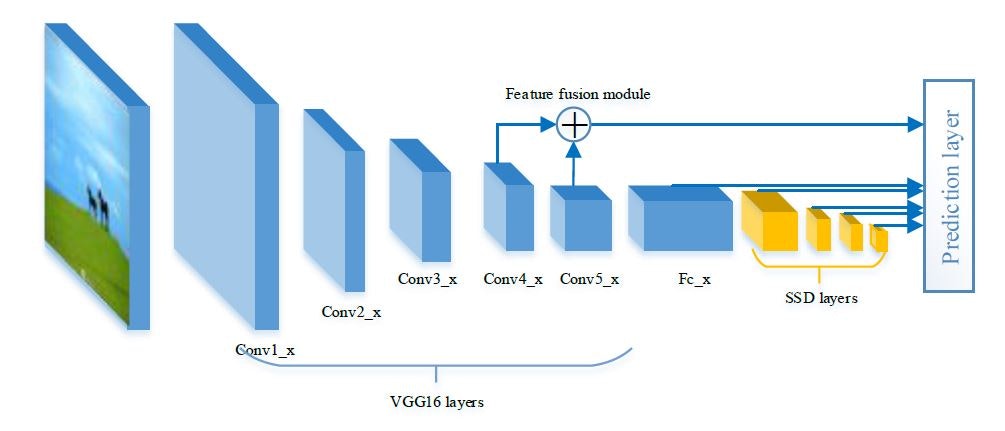
VGG16の畳み込み層の各層は層を深くしていくごとに特徴マップに反映されている物体の大きさは大きくなっていく.
VGG16の畳み込み層第4群3番目と第5群3番目には小物体の情報が刻まれており,オリジナルSSDでは特徴マップ第4群3番目から特徴量を抽出し,コンカチしているが,FSSDでは第4群3番目と第5群3番目の特徴を組み合わせることによって特徴マップに反映されている情報を増やそうというものである.

また,FSSDはDSSDにインスパイアされたモデルで,DSSDのElt-SUMモデルに正規化層を入れたものになっている.
FSSDではElt-SUMモデルと,Concatモデルが提案されており,Concatモデルと比較すると相対的にElt-SUMモデルのほうが多少背景ノイズに弱いが(絶対的に弱いとは言ってない),少ないパラメータで,Concatモデルよりも周囲の状況を加味した検出ができるので,私はElt-SUMモデルを使用している.

参考文献1)より引用
余談であるが,DSSDではElt-SUMモデルのほかに,Elt-Prodモデルなどもあり,DSSDの場合Elt-SUMモデルよりもElt-ProdモデルのほうがMAPは0.2だけ高くなるらしい.
ところで,Normalizeがなぜ10なのか疑問に思った.Deconvolutionを入れているからなのであろうか,レイヤーの大きさが畳み込み4_3に比べて半分だからであろうか...まいっか.
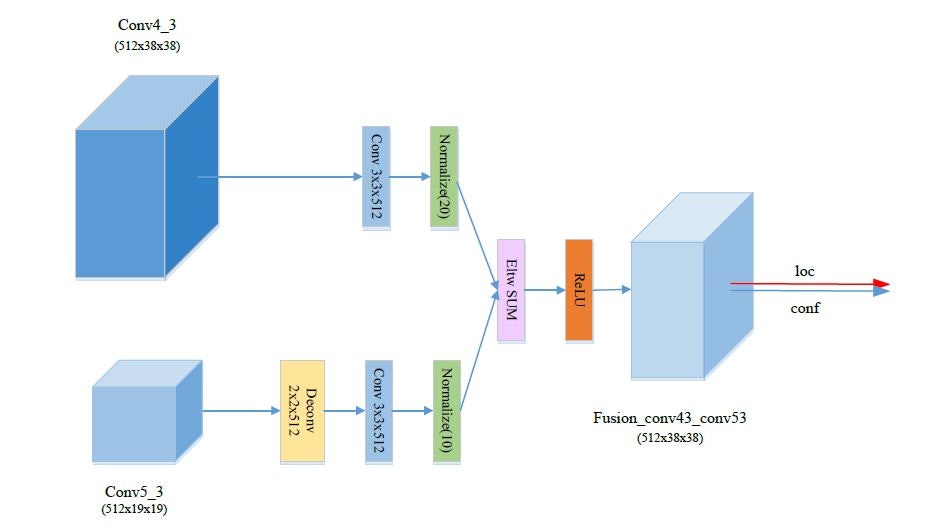
2.FSSDのkeras実装
詳しくは以下のようになっている.

左上あたりフュージョンしているのはお判りいただけただろうか.
SSDGlobalAveragePooling版のSSDとの違いは
Filter=f,stride=s,kernel=k
とすると
・畳み込み特徴マップ4群第3番を畳み込み
→Convolution(f=512,k=(3,3)s=1)
→スケール20でl2正規化・・・1
・畳み込み特徴マップ5群第3番を畳み込み
→Deconvolution(f=512,k=(3,3)s=2)
→スケール10でl2正規化・・・2
・1と2の各要素の足し合わせ→Reluで活性化
といった操作を加えた.
3.考察
もうちょっと精度良くてもいいような気がしたんだけどなあ...(笑)
ただ,少し特徴的なのは,論文にあるように一つのオブジェクトに対して,複数回検出される現象は抑えることができている.
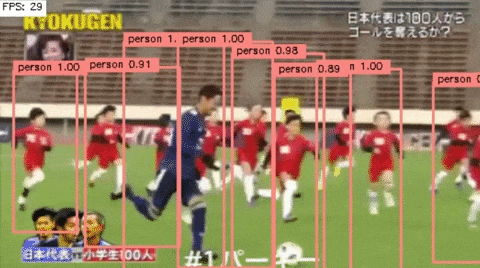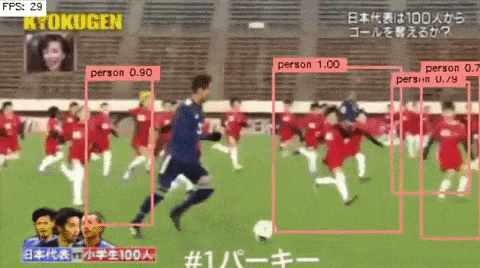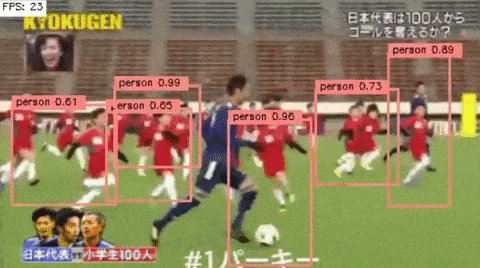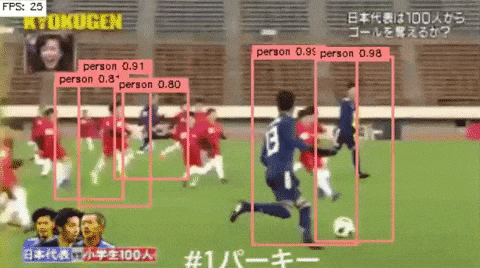
4.終わりに
Keras版の自作ネットワークを作っている方がいたらアドバイスなどお願いします.
https://github.com/tanakataiki/ssd_kerasV2
筆者の環境
CPU:Xenon GPU:GTX1080Ti×2
今後は他のネットワークを載せていくつもりです.
3.参考文献
1)https://arxiv.org/ftp/arxiv/papers/1709/1709.05054.pdf
2)https://arxiv.org/pdf/1712.00960.pdf
3)https://arxiv.org/pdf/1701.06659.pdf