アヤメの花を分類するDeepLearing(TensorFlow使用)
共有すること
・TensorFlowを使ってDeepLearningを実装する方法
・CSVデータをTensorFlowで実装したDeepLearningに学習させる
この記事はこんな人に向いています
・とりあえず、TensorFlowを動かしてみたい
・TensorFlowのチュートリアルに挑戦したいけど、英語に自信がない
この記事はこんな人には向いていません
・DeepLearingとは何か? TensorFlowとは何か? アヤメの分類とは何か?と感じている方
・英語に自信がある方(TensorFlow HPに丁寧に書かれているので、そちらが確実です)
参考資料
Google TensorFlow - Get Started with Eager Execution
https://www.tensorflow.org/get_started/eager
(詳細は上記ページ《英語》を確認してください。)
コード例
下記コードは、TensorFlow HPに掲載されているものをまとめたもの
iris_prediction_tensorflow.py
#IRIS prediction by TensorFlow
#https://www.tensorflow.org/get_started/eager
from __future__ import absolute_import, division, print_function
import os
import matplotlib.pyplot as plt
import tensorflow as tf
import tensorflow.contrib.eager as tfe
## TensorFlowのバージョンチェック
tf.enable_eager_execution()
print("TensorFlow version: {}".format(tf.VERSION))
print("Eager execution: {}".format(tf.executing_eagerly()))
## 訓練データ(CSV)を指定URLからダウンロード
train_dataset_url = "http://download.tensorflow.org/data/iris_training.csv"
train_dataset_fp = tf.keras.utils.get_file(fname=os.path.basename(train_dataset_url),origin=train_dataset_url)
print("Local copy of the dataset file: {}".format(train_dataset_fp))
## ダウンロードしたデータを整形
def parse_csv(line):
example_defaults = [[0.], [0.], [0.], [0.], [0]] # sets field types
parsed_line = tf.decode_csv(line, example_defaults)
# First 4 fields are features, combine into single tensor
features = tf.reshape(parsed_line[:-1], shape=(4,))
# Last field is the label
label = tf.reshape(parsed_line[-1], shape=())
return features, label
## Create the training tf.data.Dataset
train_dataset = tf.data.TextLineDataset(train_dataset_fp)
train_dataset = train_dataset.skip(1) # skip the first header row
train_dataset = train_dataset.map(parse_csv) # parse each row
train_dataset = train_dataset.shuffle(buffer_size=1000) # randomize
train_dataset = train_dataset.batch(32)
## View a single example entry from a batch
features, label = tfe.Iterator(train_dataset).next()
print("example features:", features[0])
print("example label:", label[0])
## Using Keras Model
model = tf.keras.Sequential([
tf.keras.layers.Dense(10, activation="relu", input_shape=(4,)), # input shape required
tf.keras.layers.Dense(10, activation="relu"),
tf.keras.layers.Dense(3)
])
## Train model(訓練モデル)
def loss(model, x, y):
y_ = model(x)
return tf.losses.sparse_softmax_cross_entropy(labels=y, logits=y_)
def grad(model, inputs, targets):
with tfe.GradientTape() as tape:
loss_value = loss(model, inputs, targets)
return tape.gradient(loss_value, model.variables)
# optimizer
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01)
## Train Loop
## Note: Rerunning this cell uses the same model variables
# keep results for plotting
train_loss_results = []
train_accuracy_results = []
## 学習回数の設定
num_epochs = 201
for epoch in range(num_epochs):
epoch_loss_avg = tfe.metrics.Mean()
epoch_accuracy = tfe.metrics.Accuracy()
# Training loop - using batches of 32
for x, y in tfe.Iterator(train_dataset):
# Optimize the model
grads = grad(model, x, y)
optimizer.apply_gradients(zip(grads, model.variables),
global_step=tf.train.get_or_create_global_step())
# Track progress
epoch_loss_avg(loss(model, x, y)) # add current batch loss
# compare predicted label to actual label
epoch_accuracy(tf.argmax(model(x), axis=1, output_type=tf.int32), y)
# end epoch
train_loss_results.append(epoch_loss_avg.result())
train_accuracy_results.append(epoch_accuracy.result())
# 学習回数50回ごとにLossとAccuracyを表示
if epoch % 50 == 0:
print("Epoch {:03d}: Loss: {:.3f}, Accuracy: {:.3%}".format(epoch,
epoch_loss_avg.result(),
epoch_accuracy.result()))
##Visualize the loss function
fig, axes = plt.subplots(2, sharex=True, figsize=(12, 8))
fig.suptitle('Training Metrics')
axes[0].set_ylabel("Loss", fontsize=14)
axes[0].plot(train_loss_results)
axes[1].set_ylabel("Accuracy", fontsize=14)
axes[1].set_xlabel("Epoch", fontsize=14)
axes[1].plot(train_accuracy_results)
plt.show()
##Evaluate the model effectives(学習過程の可視化)
test_url = "http://download.tensorflow.org/data/iris_test.csv"
test_fp = tf.keras.utils.get_file(fname=os.path.basename(test_url),
origin=test_url)
test_dataset = tf.data.TextLineDataset(test_fp)
test_dataset = test_dataset.skip(1) # skip header row
test_dataset = test_dataset.map(parse_csv) # parse each row with the funcition created earlier
test_dataset = test_dataset.shuffle(1000) # randomize
test_dataset = test_dataset.batch(32) # use the same batch size as the training set
##Evaluate test data set
test_accuracy = tfe.metrics.Accuracy()
for (x, y) in tfe.Iterator(test_dataset):
prediction = tf.argmax(model(x), axis=1, output_type=tf.int32)
test_accuracy(prediction, y)
print("Test set accuracy: {:.3%}".format(test_accuracy.result()))
##Use the trained model to make prediction
class_ids = ["Iris setosa", "Iris versicolor", "Iris virginica"]
##予測したいアヤメの情報を入力
predict_dataset = tf.convert_to_tensor([
[5.1, 3.3, 1.7, 0.5,],
[5.9, 3.0, 4.2, 1.5,],
[6.9, 3.1, 5.4, 2.1],
])
predictions = model(predict_dataset)
#予測結果の表示
for i, logits in enumerate(predictions):
class_idx = tf.argmax(logits).numpy()
name = class_ids[class_idx]
print("Example {} prediction: {}".format(i, name))
出力結果
出力結果
TensorFlow version: 1.7.0
Eager execution: True
Local copy of the dataset file: /Users/tanakadaichi_1989/.keras/datasets/iris_training.csv
2018-04-16 19:50:08.092376: I tensorflow/core/platform/cpu_feature_guard.cc:140] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
example features: tf.Tensor([6.2 2.2 4.5 1.5], shape=(4,), dtype=float32)
example label: tf.Tensor(1, shape=(), dtype=int32)
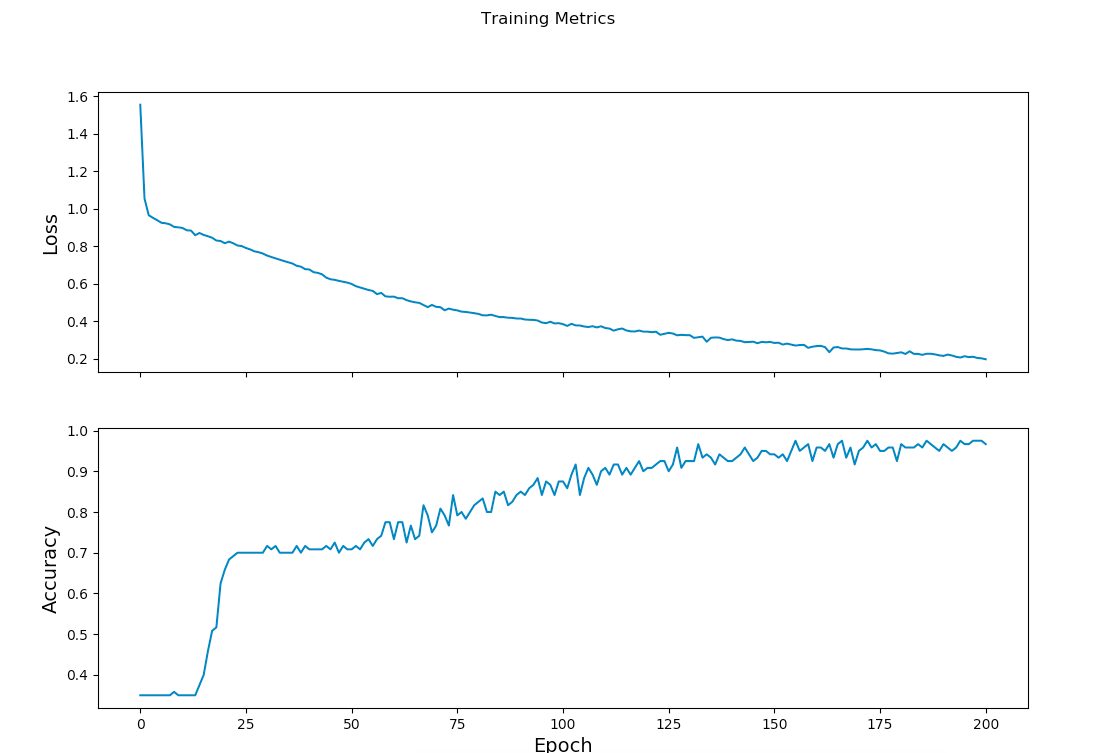
Epoch 000: Loss: 1.556, Accuracy: 35.000%
Epoch 050: Loss: 0.600, Accuracy: 70.833%
Epoch 100: Loss: 0.385, Accuracy: 87.500%
Epoch 150: Loss: 0.285, Accuracy: 94.167%
Epoch 200: Loss: 0.198, Accuracy: 96.667%
Test set accuracy: 93.333%
Example 0 prediction: Iris setosa
Example 1 prediction: Iris versicolor
Example 2 prediction: Iris virginica
学習過程を可視化したグラフ
TensorFlow HPの内容をまとめた感想
・新しい技術を得るためには、英語力は必要(案外簡単な英語で書かれていた)
・「難しそう」と思っていたTensorFlowも、一回やってみたら身近に感じられる
・余裕があれば、自分が用意したCSVデータをTensorFlowに学習させて実装したい