EfficientNet V1について構造の説明と実装のメモ書きです。
ただし、論文すべてを見るわけでなく構造のところを中心に見ていきます。
勉強のメモ書き程度でありあまり正確に実装されていませんので、ご了承ください。
学習もうまくできなかったので何か致命的なミスがあるかもしれません。
自分の実力不足で読み解けなくなってきています。難しいです。
以下の論文について実装を行っていきます。
タイトル:EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
Efficient Net
$i$番目の畳み込み層を
$$
Y_i=F_i{X_i}
$$
と定義します。ここで$F_i$はオペレータ、$Y_i$は出力となります。
また、$X_i$は入力でサイズは$$となります。$H_i,W_i$は空間方向の次元(幅、高さ),
$C_i$はチャンネル数です。
畳み込みネットワーク$N$は、次のように層の積み重ねで表すことができます。
N=F_k\odot\cdots\odot F_2\odot F_1(X_1)=\odot_{j=1\cdots k}F_j(X_1)
畳み込みネットワークは同じ構造を持った複数のステージに分けられることが多いので、
N=\odot_{i=1\cdots s}F_i^{L_i}(X_{<H_i,W_i,C_i>})
と定義します。$F_i^{L_i}$は$F_i$がステージ$i$では$L_i$回繰り返されることを表します。
ネットワークの長さ(length)$L_i$、チャンネル数(width)$C_i$、解像度(resolution)$(H_i,W_i)$を、モデルの精度を与えられたリソースで最大化するためにスケールすることを考えます。
max_{d,w,r}\ Accuracy(N(d,w,r))\\
s.t.\ N(d,w,r)=\odot_{i=1\cdots s}\hat{F}_i^{d・L_i}(X_{<r・\hat{H}_i,r・\hat{W}_i,w・\hat{C}_i>} )\\
Memory(N)\leq target\_memory\\
FLOPS(N)\leq target\_flops
ここで、$w,d,r$はwidth,depth,resolutionのスケーリングの定数です。
また、$\hat{F}_i,\hat{L}_i,\hat{H}_i,\hat{W}_i,\hat{C}_i$はベースラインとなるネットワークで定義されたパラメータとなります。
conpound scaling method
それぞれのパラメータのスケーリングは独立していません。
例えば画像の解像度が高い場合は、チャンネル数も増加させなければなりません。
従ってそれぞれのパラメータをバランスよく調整する必要があります。
新しいconpound scaling methodはcompound係数$\phi$を使用して,
width,depth,resolutionを一様にスケールします。
depth:d=\alpha^{\phi}\\
width:w=\beta^{\phi}\\
resolution:r=\gamma^{\phi}\\
s.t.\ \alpha・\beta^2・\gamma^2\approx 2\\
\alpha\geq1,\beta\geq2,\gamma\geq3
ここで、$\alpha,\beta,\gamma$はグリッドサーチなどで決められる定数となります。
今回は、$\alpha・\beta^2・\gamma^2\approx 2$と制限しました。
構造
ベースラインとなるネットワークの構造は次のようになります。
これをEfficientNet-B0と表します。
ここで、MBConvはMobileNetで扱ったmobile inverted bottleneckです。
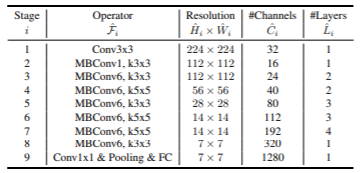
これを起点としてconpound scaling methodを次のように適用します。
EfficientNet-B0($\phi=1$)での最適な$\alpha,\beta,\gamma$は$\alpha=1.2,\beta=1.1,\gamma=1.15$と計算できました。そして、
d=\alpha^{\phi}\\
w=\beta^{\phi}\\
r=\gamma^{\phi}\\
より、算出された$d,w,r$によって、異なる$\phi$でスケールアップされた$B1$から$B7$のネットワークを得ることができます。本来各$\phi$で最適な$\alpha,\beta,\gamma$を計算すべきですが、計算コストなどを考えて固定とします。
今回の実装では
の値を参考にしています。(というより本当の実装はこちらを参照ください。)
学習
最適化手法としてRMSprop、decayは0.9、momentumは0.9です。
weight decayは1e-5とし、学習率は0.256で2.4エポックごとに0.97の減衰率で減少させていきます。
SiLU(Swish-1)を活性化関数として使用しています。
Dropoutの確率はスケールに応じて増加させます。(B0で0.2、B7で0.5)
実装
実装していきます。
改めて勉強目的であるため正確でないことご承知おきください。
内容自体はMobileNetとほぼ変わりません。
keras
まずkerasです。
必要なライブラリのインポートをします。
import tensorflow.keras as keras
import tensorflow as tf
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.layers import Input, Conv2D, Activation, Dense, GlobalAveragePooling2D, BatchNormalization, DepthwiseConv2D, Add, Multiply, ReLU, Dropout
from keras.layers.merge import concatenate
from tensorflow.keras import backend as K
from tensorflow.keras.optimizers import RMSprop
from tensorflow.keras.activations import swish
from tensorflow.keras.callbacks import LearningRateScheduler
import numpy as np
import math
import cv2
活性化関数及び、SE blockの実装をします。
これらはすでに以前の記事で紹介しました。
def hard_sigmoid(x):
return ReLU(6.)(x + 3.) * (1. / 6.)
def hard_swish(x):
return Multiply()([Activation(hard_sigmoid)(x), x])
class SE_Block(Model):
def __init__(self, in_channels, r=0.25):
super().__init__()
self.pool = GlobalAveragePooling2D()
self.fc1 = Dense(int(in_channels*r))
self.relu = Activation(hard_sigmoid)
self.fc2 = Dense(in_channels, activation='sigmoid')
def call(self, x):
out = self.pool(x)
out = self.fc1(out)
out = self.relu(out)
out = self.fc2(out)
out = Multiply()([x, out])
return out
メインはMobileNetで使用したブロックとなります。
class MobileConv(Model):
def __init__(self, in_channels, out_channels, kernel, t, s, r=0.25):
super().__init__()
exp_size = int(t*in_channels)
self.conv1 = Conv2D(filters = exp_size, kernel_size = (1,1), padding = 'same')
self.bn1 = BatchNormalization()
self.relu1 = Activation(swish)
self.conv2 = DepthwiseConv2D(kernel_size = kernel, strides=s, padding = 'same')
self.bn2 = BatchNormalization()
self.relu2 = Activation(swish)
self.conv3 = Conv2D(filters = out_channels, kernel_size = (1,1), padding = 'same')
self.bn3 = BatchNormalization()
self.relu3 = Activation(swish)
self.se = SE_Block(in_channels=out_channels, r=r)
self.drop = Dropout(rate=0.8,noise_shape=(None, 1, 1, 1))
self.add = Add()
def call(self, x):
out = self.conv1(x)
out = self.bn1(out)
out = self.relu1(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu2(out)
out = self.conv3(out)
out = self.bn3(out)
out = self.relu3(out)
out = self.se(out)
if K.int_shape(out) == K.int_shape(x):
out = self.drop(out)
out = self.add([out, x])
return out
EfficirntNet本体の実装をします。
B0~B7でチャンネル数とブロック内のレイヤ数の倍率が異なります。
B0のものをベースに引数で渡す倍率だけ増加させます。
class EfficientNet(Model):
def __init__(self, d,w,p=0.2):
super().__init__()
self.conv1 = Conv2D(filters = 32, kernel_size = 3, strides=2, padding = 'same')
self.bn1 = BatchNormalization()
self.relu1 = Activation(swish)
self.mbconv1 = self._mobile_conv(in_channels=32, out_channels=np.ceil(16*w), kernel=3, L=np.ceil(1*d), t=1, down_sample=False)
self.mbconv2 = self._mobile_conv(in_channels=np.ceil(16*w), out_channels=np.ceil(24*w), kernel=3, L=np.ceil(2*d), t=6, down_sample=True)
self.mbconv3 = self._mobile_conv(in_channels=np.ceil(24*w), out_channels=np.ceil(40*w), kernel=5, L=np.ceil(2*d), t=6, down_sample=True)
self.mbconv4 = self._mobile_conv(in_channels=np.ceil(40*w), out_channels=np.ceil(80*w), kernel=3, L=np.ceil(3*d), t=6, down_sample=True)
self.mbconv5 = self._mobile_conv(in_channels=np.ceil(80*w), out_channels=np.ceil(112*w), kernel=5, L=np.ceil(3*d), t=6, down_sample=False)
self.mbconv6 = self._mobile_conv(in_channels=np.ceil(112*w), out_channels=np.ceil(192*w), kernel=5, L=np.ceil(4*d), t=6, down_sample=True)
self.mbconv7 = self._mobile_conv(in_channels=np.ceil(192*w), out_channels=np.ceil(320*w), kernel=5, L=np.ceil(1*d), t=6, down_sample=False)
self.conv2 = Conv2D(filters = 1280, kernel_size = 1, strides=1, padding = 'same')
self.bn2 = BatchNormalization()
self.relu2 = Activation(swish)
self.pool = GlobalAveragePooling2D()
self.drop1 = Dropout(p)
self.fc1 = Dense(1280)
self.relu3 = Activation(swish)
self.drop2 = Dropout(p)
self.fc2 = Dense(10, activation='softmax')
def call(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu1(x)
x = self.mbconv1(x)
x = self.mbconv2(x)
x = self.mbconv3(x)
x = self.mbconv4(x)
x = self.mbconv5(x)
x = self.mbconv6(x)
x = self.mbconv7(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.relu2(x)
x = self.pool(x)
x = self.drop1(x)
x = self.fc1(x)
x = self.relu3(x)
x = self.drop2(x)
x = self.fc2(x)
return x
def _mobile_conv(self, in_channels, out_channels, kernel, L, t, down_sample=True):
mb_layers = []
for i in range(int(L)):
s = 1
if (i==0):
in_channels=in_channels
if down_sample:
s = 2
else:
in_channels = out_channels
mb_layers.append(MobileConv(in_channels=in_channels, out_channels=out_channels, kernel=kernel, t=t, s=s))
return Sequential(mb_layers)
各モデルの倍率です。
さきほど紹介した実装をもとにしています。
R={'B0':224, 'B1':240, 'B2':260, 'B3':300, 'B4':380, 'B5':456, 'B6':528, 'B7':600}
D={'B0':1, 'B1':1.1, 'B2':1.2, 'B3':1.4, 'B4':1.8, 'B5':2.2, 'B6':2.6, 'B7':3.1} # L
W={'B0':1, 'B1':1, 'B2':1.1, 'B3':1.2, 'B4':1.4, 'B5':1.6, 'B6':1.8, 'B7':2} #C
P={'B0':0.2, 'B1':0.2, 'B2':0.3, 'B3':0.3, 'B4':0.4, 'B5':0.4, 'B6':0.5, 'B7':0.5}
試しにB4の構造を確認します。
model_type='B4'
h=R[model_type]
model = EfficientNet(d=D[model_type], w=W[model_type], p=P[model_type])
model.build((None, h, h, 3)) # build with input shape.
dummy_input = Input(shape=(h, h, 3)) # declare without batch demension.
model_summary = Model(inputs=[dummy_input], outputs=model.call(dummy_input))
model_summary.summary()
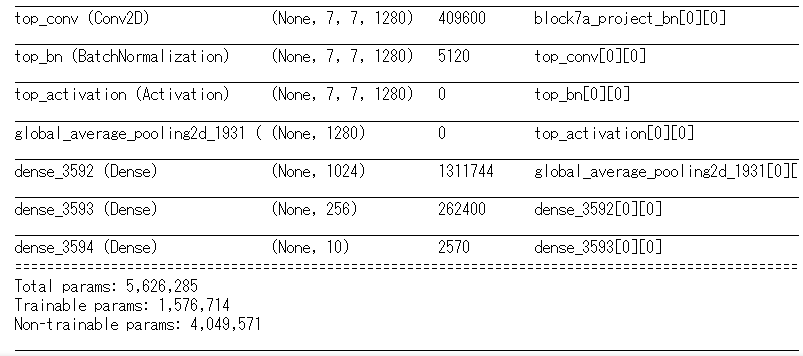
あとは学習の準備をして終わります。
実際に用意したデータで学習させる場合はこれらのパラメータは調整する必要があります。
epochs = 100
initial_lrate = 0.256
def decay(epoch, steps=100):
initial_lrate = 0.256
drop = 0.97
epochs_drop = 3
lrate = initial_lrate * math.pow(drop, math.floor((1+epoch)/epochs_drop))
return lrate
sgd = RMSprop(lr=initial_lrate, rho=0.9, epsilon=1.0, decay=0.9)
lr_sc = LearningRateScheduler(decay, verbose=1)
model = EfficientNet(d=D[model_type], w=W[model_type], p=P[model_type])
model.compile(loss=['categorical_crossentropy'], optimizer=sgd, metrics=['accuracy'])
転移学習(keras)
学習済みモデルが用意されています。
実際はこちらを使うことになると思います。
from tensorflow.keras.applications.efficientnet import EfficientNetB0
input_shape = (224,224,3)
base_model = EfficientNetB0(weights='imagenet', include_top=False, input_shape=input_shape)
x = base_model.output
x = GlobalAveragePooling2D()(x)
x = Dense(1024, activation='relu')(x)
x = Dropout(0.5)(x)
output = Dense(10, activation='softmax')(x)
model = Model(inputs=base_model.input, outputs=output)
for layer in base_model.layers[:250]:
layer.trainable = False
pytorch
pytorchでも同様に実装をします。
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import pytorch_lightning as pl
from torchmetrics import Accuracy as accuracy
SE Blockの実装。
Hardsigmoidなどはもともと用意されています。
class SE_Block(nn.Module):
def __init__(self, in_channels, r):
super().__init__()
self.pool = nn.AdaptiveAvgPool2d((1,1))
self.fc1 = nn.Linear(in_channels, int(in_channels*r))
self.relu = nn.ReLU(inplace=False)
self.fc2 = nn.Linear(int(in_channels*r), in_channels)
self.sigmoid = nn.Hardsigmoid()
def forward(self, x):
out = self.pool(x)
out = out.view(out.shape[0], -1)
out = self.fc1(out)
out = self.relu(out)
out = self.fc2(out)
out = self.sigmoid(out)
out = out.view(out.shape[0], out.shape[1], 1,1).expand_as(x)
return out * x
Mobile Blockの実装
class MobileConv(nn.Module):
def __init__(self, in_channels, out_channels, kernel, s, t, r=0.25):
super().__init__()
exp_size = int(t*in_channels)
activation = nn.Hardswish
self.conv1 = nn.Conv2d(in_channels=in_channels, out_channels=exp_size, kernel_size = 1)
self.bn1 = nn.BatchNorm2d(exp_size)
self.relu1 = activation(False)
self.conv2 = nn.Conv2d(in_channels=exp_size, out_channels=exp_size, kernel_size = kernel, stride=s, groups=exp_size, padding = int((kernel-1)/2))
self.bn2 = nn.BatchNorm2d(exp_size)
self.relu2 = activation(False)
self.conv3 = nn.Conv2d(in_channels=exp_size, out_channels=out_channels, kernel_size = 1)
self.bn3 = nn.BatchNorm2d(out_channels)
self.relu3 = activation(False)
self.se = SE_Block(in_channels=out_channels, r=r)
def forward(self, x):
out = self.conv1(x)
out = self.bn1(out)
out = self.relu1(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu2(out)
out = self.conv3(out)
out = self.bn3(out)
out = self.relu3(out)
out = self.se(out)
if out.shape == x.shape:
out = self.StochasticDepth(out)
out = out + x
return out
def StochasticDepth(self,x):
if not self.training:
return x
prob = torch.rand((x.shape[0],1,1,1))
mask = prob < 0.8
return torch.mul(torch.div(x, 0.8),mask)
EfficientNet本体の実装をします。
倍率を引数にしてモデルの作り分けをできるようにします。
class EfficientNet(nn.Module):
def __init__(self, d, w, p=0.2):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=32, kernel_size = 3, stride=2, padding = 1)
self.bn1 = nn.BatchNorm2d(32)
self.relu1 = nn.Hardswish(False)
self.mbconv1 = self._mobile_conv(in_channels=32, out_channels=np.ceil(16*w), kernel=3, L=np.ceil(1*d), t=1, down_sample=False)
self.mbconv2 = self._mobile_conv(in_channels=np.ceil(16*w), out_channels=np.ceil(24*w), kernel=3, L=np.ceil(2*d), t=6, down_sample=True)
self.mbconv3 = self._mobile_conv(in_channels=np.ceil(24*w), out_channels=np.ceil(40*w), kernel=5, L=np.ceil(2*d), t=6, down_sample=True)
self.mbconv4 = self._mobile_conv(in_channels=np.ceil(40*w), out_channels=np.ceil(80*w), kernel=3, L=np.ceil(3*d), t=6, down_sample=True)
self.mbconv5 = self._mobile_conv(in_channels=np.ceil(80*w), out_channels=np.ceil(112*w), kernel=5, L=np.ceil(3*d), t=6, down_sample=False)
self.mbconv6 = self._mobile_conv(in_channels=np.ceil(112*w), out_channels=np.ceil(192*w), kernel=5, L=np.ceil(4*d), t=6, down_sample=True)
self.mbconv7 = self._mobile_conv(in_channels=np.ceil(192*w), out_channels=np.ceil(320*w), kernel=5, L=np.ceil(1*d), t=6, down_sample=False)
self.conv2 = nn.Conv2d(in_channels=int(np.ceil(320*w)), out_channels=1280, kernel_size = 1, stride=1, padding = 0)
self.bn2 = nn.BatchNorm2d(1280)
self.relu2 = nn.Hardswish(False)
self.pool = nn.AdaptiveAvgPool2d((1,1))
self.drop = nn.Dropout(p)
self.fc = nn.Linear(1280, 1280)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu1(x)
x = self.mbconv1(x)
x = self.mbconv2(x)
x = self.mbconv3(x)
x = self.mbconv4(x)
x = self.mbconv5(x)
x = self.mbconv6(x)
x = self.mbconv7(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.relu2(x)
x = self.pool(x)
x = x.view(x.shape[0], -1)
x = self.drop(x)
x = self.fc(x)
return x
def _mobile_conv(self, in_channels, out_channels, kernel, L, t, down_sample=True):
in_channels = int(in_channels)
out_channels = int(out_channels)
mb_layers = []
for i in range(int(L)):
s = 1
if (i==0):
in_channels=in_channels
if down_sample:
s = 2
else:
in_channels = out_channels
mb_layers.append(MobileConv(in_channels=in_channels, out_channels=out_channels, kernel=kernel, t=t, s=s))
return nn.Sequential(*mb_layers)
構造を確認します。
B7を見てみます。
from torchsummary import summary
R={'B0':224, 'B1':240, 'B2':260, 'B3':300, 'B4':380, 'B5':456, 'B6':528, 'B7':600}
D={'B0':1, 'B1':1.1, 'B2':1.2, 'B3':1.4, 'B4':1.8, 'B5':2.2, 'B6':2.6, 'B7':3.1} # L
W={'B0':1, 'B1':1, 'B2':1.1, 'B3':1.2, 'B4':1.4, 'B5':1.6, 'B6':1.8, 'B7':2} #C
P={'B0':0.2, 'B1':0.2, 'B2':0.3, 'B3':0.3, 'B4':0.4, 'B5':0.4, 'B6':0.5, 'B7':0.5}
model_type='B7'
h=R[model_type]
summary(EfficientNet(d=D[model_type],w=W[model_type]), (3,h,h))
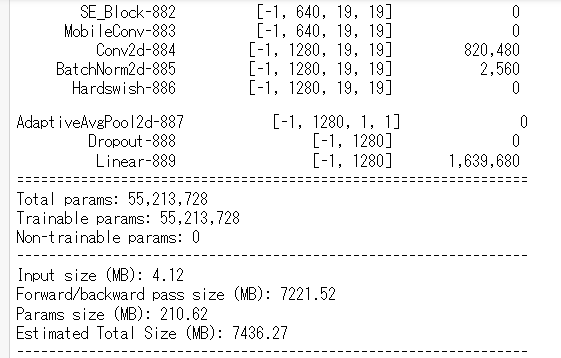
学習の準備をして終わります。
学習の目的に応じて書き換える必要があります。
class EfficientTrainer(pl.LightningModule):
def __init__(self, model_type='B0'):
super(VGGTrainer, self).__init__()
model = EfficientNet(d=D[model_type],w=W[model_type])
def forward(self, x):
x = selfEfficientTrainer.model(x)
return x
def training_step(self, batch, batch_idx):
x, y = batch
#x, y = x.to(device), y.to(device)
y_hat = self.forward(x)
loss = nn.CrossEntropyLoss()(y_hat, y)
return {'loss': loss, 'y_hat':y_hat, 'y':y, 'batch_loss': loss.item()*x.size(0)}
def validation_step(self, batch, batch_idx):
x, y = batch
#x, y = x.to(device), y.to(device)
y_hat = self.forward(x)
loss = nn.CrossEntropyLoss()(y_hat, y)
return {'y_hat':y_hat, 'y':y, 'batch_loss': loss.item()*x.size(0)}
def test_step(self, batch, batch_nb):
x, y = batch
#x, y = x.to(device), y.to(device)
y_hat = self.forward(x)
loss = nn.CrossEntropyLoss()(y_hat, y)
y_label = torch.argmax(y_hat, dim=1)
acc = accuracy()(y_label, y)
return {'test_loss': loss, 'test_acc': acc}
def training_epoch_end(self, train_step_output):
y_hat = torch.cat([val['y_hat'] for val in train_step_outputs], dim=0)
y = torch.cat([val['y'] for val in train_step_outputs], dim=0)
epoch_loss = sum([val['batch_loss'] for val in train_step_outputs]) / y_hat.size(0)
preds = torch.argmax(y_hat, dim=1)
acc = accuracy()(preds, y)
self.log('train_loss', epoch_loss, prog_bar=True, on_epoch=True)
self.log('train_acc', acc, prog_bar=True, on_epoch=True)
print('---------- Current Epoch {} ----------'.format(self.current_epoch + 1))
print('train Loss: {:.4f} train Acc: {:.4f}'.format(epoch_loass, acc))
def validation_epoch_end(self, val_step_outputs):
y_hat = torch.cat([val['y_hat'] for val in val_step_outputs], dim=0)
y = torch.cat([val['y'] for val in val_step_outputs], dim=0)
epoch_loss = sum([val['batch_loss'] for val in val_step_outputs]) / y_hat.size(0)
preds = torch.argmax(y_hat, dim=1)
acc = accuracy()(preds, y)
self.log('val_loss', epoch_loss, prog_bar=True, on_epoch=True)
self.log('val_acc', acc, prog_bar=True, on_epoch=True)
print('valid Loss: {:.4f} valid Acc: {:.4f}'.format(epoch_loss, acc))
# New: テストデータに対するエポックごとの処理
def test_epoch_end(self, test_step_outputs):
y_hat = torch.cat([val['y_hat'] for val in test_step_outputs], dim=0)
y = torch.cat([val['y'] for val in test_step_outputs], dim=0)
epoch_loss = sum([val['batch_loss'] for val in test_step_outputs]) / y_hat.size(0)
preds = torch.argmax(y_hat, dim=1)
acc = accuracy()(preds, y)
self.log('test_loss', epoch_loss, prog_bar=True, on_epoch=True)
self.log('test_acc', acc, prog_bar=True, on_epoch=True)
print('test Loss: {:.4f} test Acc: {:.4f}'.format(epoch_loss, acc))
def configure_optimizers(self):
optimizer = optim.RMSprop(self.parameters(), lr=0.1, eps=1.0, momentum=0.9)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=3, gamma=0.03)
return {'optimizer': optimizer, 'lr_scheduler': scheduler}
転移学習(pytorch)
学習済みモデルが用意されています。
最後の層を目的に応じて書き換えます。
efficientb0 = models.efficientnet_b0(pretrained=True)
efficientb0.classifier[1] = nn.Linear(in_features=1280, out_features=10)
self.model = efficientb0
update_param_names = ['classifier.1.weight', 'classifier.1.bias']
for name, param in self.model.named_parameters():
if name in update_param_names:
param.requires_grad = True
else:
param.requires_grad = False
これでEfficientNetの実装を終わります。
学習させてみようと思いましたが、うまくいかなかったので悩み中です。