「異常検知と変化検知」は異常検知の本です。アルゴリズム部分をpythonで実装していきたいと思います。たくさんの方が同じ内容をより良い記事でとして投稿しています。
個人的な勉強のメモ書きとなります。
私には難しい内容であり、コードがかなり汚いです。申し訳ありません。
まとめることが目的ではないので本文について参考書とほぼ同じ表現となっています。問題があればお教えください。
興味を持ったり、導出や詳細などを知りたい方は「異常検知と変化検知」を読んでいただければと思います。
参考
前回
サポートベクトルデータ記述法による異常検知
方向データの異常検知
長さが揃ったベクトルについての分布
長さ1の$M$次元ベクトル$N$本からなるデータが$D={\boldsymbol{x}^{(1)},\cdots,\boldsymbol{x}^{(N)}}$のように与えられているとする。($\boldsymbol{x}^{(n)T}\boldsymbol{x}^{(n)}=1$)
この$D$を方向データと呼ぶ。
長さが揃ったベクトルを表現するために最も自然な分布は、フォンミーゼス・フィッシャー分布である。この分布は平均方向と集中度という2つのパラメータを持つ。
それぞれ、$\boldsymbol{\mu}$および$\kappa$と表すと、その確率密度関数$\mathcal{M}(\boldsymbol{x}|\boldsymbol{\mu},\kappa)$は次のようになる。
$$
\mathcal{M}(\boldsymbol{x}|\boldsymbol{\mu},\kappa)=\frac{\kappa^{M/2-1}}{(2\pi)^{M/2}I_{M/2-1}(\kappa)}\exp{(\kappa\boldsymbol{\mu}^T\boldsymbol{x})}
$$
ただし、平均方向$\boldsymbol{\mu}$は単位ベクトルで$\boldsymbol{\mu}^T\boldsymbol{\mu}=1$を満たす。
また、分母の$I_{(M/2)-1}(\kappa)$は第1種変形ベッセル関数である。
一般に、$\alpha$階の第1種変形ベッセル関数$I_\alpha$は次のように定義される。
$$
I_\alpha(\kappa)=\frac{2^{-\alpha}\kappa^{\alpha}}{\sqrt{\pi}\Gamma(\alpha+(1/2))}\int_0^\pi d\phi\sin^{2\alpha}\phi e^{\kappa\cos\phi}
$$
from scipy.special import iv
import numpy as np
import matplotlib.pyplot as plt
def von_mises_fisher_dist(x, mu, kappa, M=None):
"""
フォンミーゼス・フィッシャー分布
iv(alpha, kappa): 第1種変形ベッセル関数
"""
if M is None:
M = len(x)
return (kappa**(M/2-1)) / ((2*np.pi)**(M/2)*iv(M/2-1, kappa)) * np.exp(kappa*mu.T@x)
M = 10 # 次元
mu = np.zeros(M)
mu[:2] = 1/np.sqrt(2) # 平均値(今回は2つの次元に値を与える)
# 球面上の座標を与える
thetas = np.linspace(-np.pi, np.pi, 100)
_mu_rot = mu[:2]@np.array([[np.cos(thetas), -np.sin(thetas)],[np.sin(thetas), np.cos(thetas)]])
X = np.zeros((M, 100))
X[:2,:] = _mu_rot
# κの値をいくつか用意
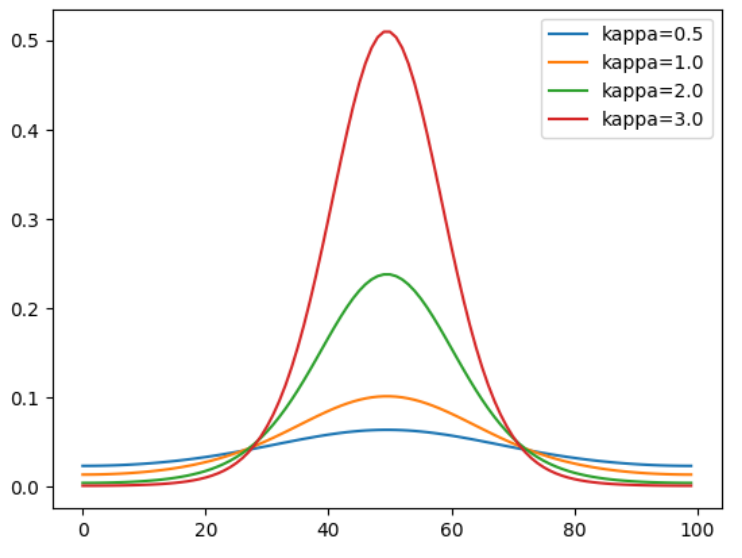
kappas = [0.5, 1.0, 2.0, 3.0]
for k in kappas:
plt.plot(von_mises_fisher_dist(X, mu, k, M), label='kappa='+str(k))
plt.legend();
平均方向の最尤推定
$\mathcal{M}(\boldsymbol{x}|\boldsymbol{\mu},\kappa)$に含まれる2つのパラメータをデータ$D$から決めることを考える。
ここで、係数を次のように$c_M(\kappa)$と表す。
$$
c_M(\kappa)=\frac{\kappa^{M/2-1}}{(2\pi)^{M/2}I_{(M/2-1)}(\kappa)}
$$
$D$に基づく尤度は次のように書ける。
L(\boldsymbol{\mu},\kappa|D)=\ln \prod_{n=1}^Nc_M(\kappa)e^{\kappa\boldsymbol{\mu}^T\boldsymbol{x}^{(n)}}=\sum_{n=1}^N\bigg\{\ln c_M(\kappa)+\kappa\boldsymbol{\mu}\boldsymbol{x}^{(n)} \bigg\}
条件$\boldsymbol{\mu}^T\boldsymbol{\mu}=1$をラグランジュ係数を使って取り込み計算することで、$\boldsymbol{\mu}$の最尤推定値$\hat{\boldsymbol{\mu}}$が、
$$
\hat{\boldsymbol{\mu}}=\frac{\boldsymbol{m}}{\sqrt{\boldsymbol{m}^T\boldsymbol{m}}},\ \boldsymbol{m}=\frac{1}{N}\sum_{n=1}^N\boldsymbol{x}^{(n)}
$$
と得られる。
集中度$\kappa$は、最尤推定は解析的にできない。
しかし、異常検知という目的のためには、$\kappa$を最尤推定で明示的に求める必要は必ずしもない。
M = 3 # 次元
N = 200 # データ数
# 球面上の座標を取得(長さ1に正規化)
X = np.random.normal(size=(N,M), loc=1, scale=0.3)
X = X / np.sqrt(np.sum(X**2, axis=1).reshape(-1,1))
# μの推定値
m = np.mean(X, axis=0)
mu_hat = m / np.sqrt(m.T@m)
print('mu_hat: ', mu_hat)
方向データの異常度とその確率分布
新たな方向データ$\boldsymbol{x}'$が来たときの異常度は、異常度の一般的な枠組みに従えば$\mathcal{M}(\boldsymbol{x}'|\hat{\boldsymbol{\mu}},\kappa)$の負の対数尤度から、
$$
a(\boldsymbol{x}')=1-\hat{\boldsymbol{\mu}}^T\boldsymbol{x}'
$$
と定義することができる。
データ$D={\boldsymbol{x}^{(n)}|n=1,\cdots,N}$および新たな観測値$\boldsymbol{x}'$が独立にフォンミーゼス・フィッシャー分布に従うという前提のもとで、異常度の確率分布を考えると、
異常度$a$の分布は自由度$M-1$、スケール因子$1/(2\kappa)$のカイ2乗分布に従うことが示される。(計算は省略)
定理(方向データの異常度の確率分布)
$\boldsymbol{x}'\sim \mathcal{M}(\boldsymbol{x}'|\hat{\boldsymbol{\mu}},\kappa)$のとき、$\kappa$が十分に大きければ、近似的に
$$
1-\boldsymbol{\mu}^T\boldsymbol{x}'\sim \chi^2\bigg(M-1,\frac{1}{2\kappa} \bigg)
$$
積率法によるカイ2乗分布の当てはめ
カイ2乗分布のパラメータを推定するために実用上便利な方法として、**積率法(モーメント法)**という方法がある。
改めて
$$
a^{(1)},\cdots,a^{(N)}\sim \chi^2(m,s)
$$
と置くことにすると、積率法により(説明は省略)
\hat{m}_{mo}=\frac{2<a>^2}{<a^2>-<a>^2}\\
\hat{s}_{mo}=\frac{<a^2>-<a>^2}{2<a>}
が得られる。
ここで、
<a>\approx \frac{1}{N}\sum_{n=1}^Na^{(n)}\\
<a^2>\approx \frac{1}{N}\sum_{n=1}^Na^{(n)2}
である。
アルゴリズム(方向データの異常検知)
- 訓練時
異常度の確率分布をデータから学習する
- 訓練データ$D={\boldsymbol{x}^{(1)},\cdots,\boldsymbol{x}^{(N)}}$に対して、最尤推定値$\hat{\mu}$を
$$
\hat{\boldsymbol{\mu}}=\frac{\boldsymbol{m}}{\sqrt{\boldsymbol{m}^T\boldsymbol{m}}},\ \boldsymbol{m}=\frac{1}{N}\sum_{n=1}^N\boldsymbol{x}^{(n)}
$$
にて計算する。- 各標本$\boldsymbol{x}^{(n)}$について、異常度$a(\boldsymbol{x}^{(n)})$を
$$
a(\boldsymbol{x}^{(n)})=1-\hat{\boldsymbol{\mu}}^T\boldsymbol{x}^{(n)}
$$- 積率法を用いて、計算された異常度$a(\boldsymbol{x}^{(1)}),\cdots,a(\boldsymbol{x}^{(N)})$に対しカイ2乗分布$\chi^{2}(\hat{m}_{mo},\hat{s}_{mo})$ を当てはめる。
- 運用時
当てはめられたカイ2乗分布をもとに、異常度の閾値$a_{th}$を求めておく
- 観測データ$\boldsymbol{x}'$に対して、異常度$a(\boldsymbol{x}')$を
$$
a(\boldsymbol{x}')=1-\hat{\boldsymbol{\mu}}^T\boldsymbol{x}'
$$
にて計算する。- $a(\boldsymbol{x}')>a_{th}$なら異常と判定、警報をだす
from scipy.stats import chi2
# 最尤推定値μの計算
m = np.mean(X, axis=0)
mu_hat = m / np.sqrt(m.T@m)
print('mu_hat: ', mu_hat)
# 各標本での異常度
a = 1 - mu_hat@X.T
# 積率法によるパラメータの推定
a_mean = np.mean(a)
a_squre_mean = np.mean(a**2)
m_mo = (2*a_mean**2)/(a_squre_mean - a_mean**2)
s_mo = (a_squre_mean-a_mean**2)/(2*a_mean)
print('m_mo: ', m_mo)
print('s_mo: ', s_mo)
# 閾値の決定
alpha = 0.05
ath = chi2.ppf(q=1-alpha, df=m_mo, scale=s_mo)
print('ath: ', ath)

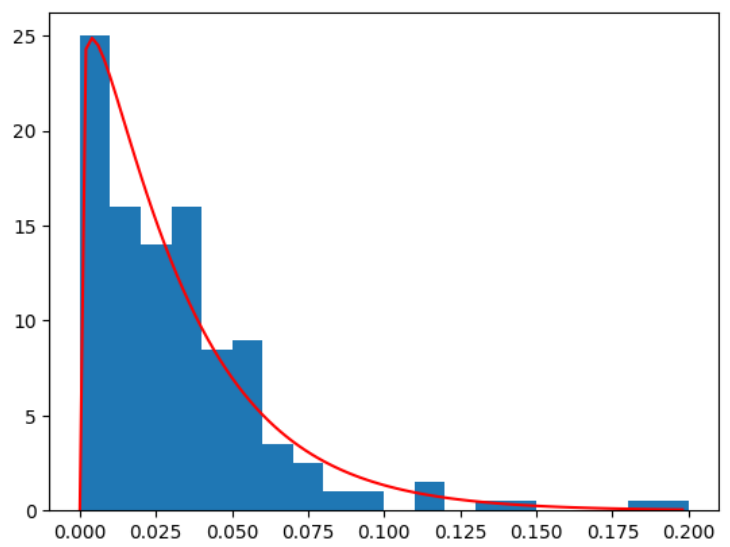
# 異常度の分布の確認
x=np.arange(0,0.2,0.002)
plt.hist(a, density=True, range=(0,0.2), bins=20)
plt.plot(x,chi2.pdf(x, df=m_mo, scale=s_mo), color='red')
# テストデータの作成
theta1, theta2 = np.mgrid[0:2*np.pi:100j, 0:2*np.pi:100j]
x = np.cos(theta1)*np.sin(theta2)
y = np.sin(theta1)*np.sin(theta2)
z = np.cos(theta2)
x_sp =np.concatenate([x.reshape(-1,1),
y.reshape(-1,1),
z.reshape(-1,1)],
axis=1)
# 異常度の計算
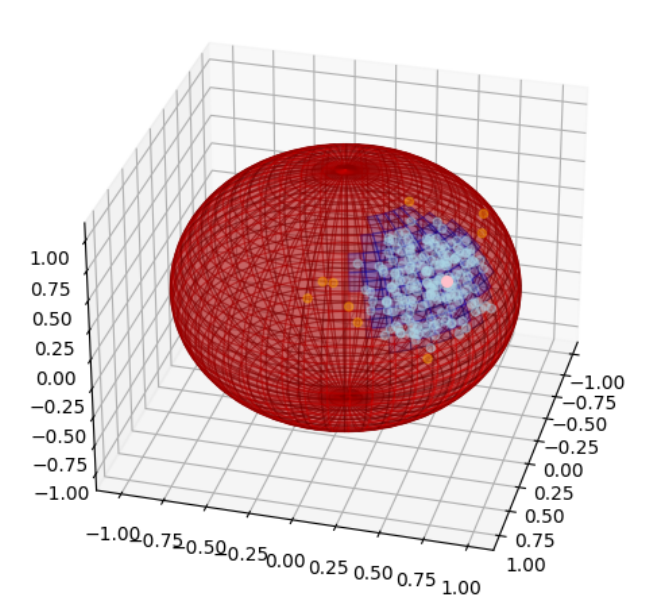
a_sp = (1 - mu_hat@x_sp.T).reshape(100,100)
# 可視化
colors = np.empty(x.shape, dtype=str)
for yy in range(len(y)):
for xx in range(len(x)):
colors[xx, yy] = 'r' if a_sp[xx,yy] > ath else 'b'
fig = plt.figure(figsize=(6,6))
ax = fig.add_subplot(111, projection='3d')
ax.scatter(X[a<=ath,0]*1.1,X[a<=ath,1]*1.1,X[a<=ath,2]*1.1, alpha=.4, color='lightblue')
ax.scatter(X[a>ath,0]*1.1,X[a>ath,1]*1.1,X[a>ath,2]*1.1, alpha=.4, color='orange')
ax.scatter(mu_hat[0]*1.3,mu_hat[1]*1.3,mu_hat[2]*1.3, color='pink', s=30)
ax.plot_wireframe(x, y, z, color='black', linewidth=0.5, alpha=0.5)
ax.plot_surface(x,y,z,facecolors=colors, alpha=.2,edgecolor ='none')
ax.view_init(elev=30, azim=15)
スパムメールのデータに適用してみる。
ここでは、語の数が10語以上のもののみを対象としてTF-IDFにより変換したデータを使用して異常検知を行うこととする。
(かなり汚いコードですがご容赦ください。)
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.feature_extraction.text import CountVectorizer
# データの読み込み
df = pd.read_csv('spam.csv', encoding='latin-1')
# 検証データと訓練データを分ける
X = pd.DataFrame(df['Message'])
Y = pd.DataFrame(df['Type'])
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, train_size=0.5, random_state=20)
X_train_spam = X_train[Y_train['Type']=='spam'].reset_index(drop=True)
X_train_ham = X_train[Y_train['Type']=='ham'].reset_index(drop=True)
X_test_spam = X_test[Y_test['Type']=='spam'].reset_index(drop=True)
X_test_ham = X_test[Y_test['Type']=='ham'].reset_index(drop=True)
# tfidf
tfidf_vectorizer = TfidfVectorizer(max_features=1500, min_df=1, max_df=10)
tfidf_vectorizer.fit(X_train['Message'])
# 訓練データの単語の出現頻度を数える
count_vectorizer = CountVectorizer()
count_vectorizer.fit(X_train['Message'])
X_train_ham_count = count_vectorizer.transform(X_train_ham['Message']).toarray().sum(axis=1)
X_train_spam_count = count_vectorizer.transform(X_train_spam['Message']).toarray().sum(axis=1)
X_test_ham_count = count_vectorizer.transform(X_test_ham['Message']).toarray().sum(axis=1)
X_test_spam_count = count_vectorizer.transform(X_test_spam['Message']).toarray().sum(axis=1)
# tfidfで変換、単語が10個以下の文は対象外とする
X_train_ham_vec = tfidf_vectorizer.transform(X_train_ham['Message']).toarray()[X_train_ham_count>10]
X_train_spam_vec = tfidf_vectorizer.transform(X_train_spam['Message']).toarray()[X_train_spam_count>10]
X_test_ham_vec = tfidf_vectorizer.transform(X_test_ham['Message']).toarray()[X_test_ham_count>10]
X_test_spam_vec = tfidf_vectorizer.transform(X_test_spam['Message']).toarray()[X_test_spam_count>10]
# 長さが1になるようにする
X_train_ham_vec = (X_train_ham_vec.T / np.sqrt((X_train_ham_vec**2).sum(axis=1))).T
X_train_spam_vec = (X_train_spam_vec.T / np.sqrt((X_train_spam_vec**2).sum(axis=1))).T
X_test_ham_vec = (X_test_ham_vec.T / np.sqrt((X_test_ham_vec**2).sum(axis=1))).T
X_test_spam_vec = (X_test_spam_vec.T / np.sqrt((X_test_spam_vec**2).sum(axis=1))).T
# 最尤推定値μの計算
m = np.mean(X_train_ham_vec, axis=0)
mu_hat = m / np.sqrt(m.T@m)
# 各標本での異常度
a = 1 - mu_hat@X_train_ham_vec.T
# 積率法によるパラメータの推定
a_mean = np.mean(a)
a_squre_mean = np.mean(a**2)
m_mo = (2*a_mean**2)/(a_squre_mean - a_mean**2)
s_mo = (a_squre_mean-a_mean**2)/(2*a_mean)
a_train_spam = (1 - mu_hat@X_train_spam_vec.T)
a_train_ham = (1 - mu_hat@X_train_ham_vec.T)
a_test_spam = (1 - mu_hat@X_test_spam_vec.T)
a_test_ham = (1 - mu_hat@X_test_ham_vec.T)
# 閾値の決定
alpha = 0.05
ath = chi2.ppf(q=1-alpha, df=m_mo, scale=s_mo)
print('ath: ', ath)
print(sum(a_train_ham>=ath)/len(a_train_ham))
print(sum(a_train_spam>=ath)/len(a_train_spam))
print(sum(a_test_ham>=ath)/len(a_test_ham))
print(sum(a_test_spam>=ath)/len(a_test_spam))
plt.hist(a_train_ham, alpha=.4, bins=np.arange(0.7,1.1,0.01), label='train_ham');
plt.hist(a_train_spam, alpha=.4, bins=np.arange(0.7,1.1,0.01), label='train_spam');
plt.hist(a_test_ham, alpha=.4, bins=np.arange(0.7,1.1,0.01), label='test_ham');
plt.hist(a_test_spam, alpha=.4, bins=np.arange(0.7,1.1,0.01), label='test_spam');
plt.legend();
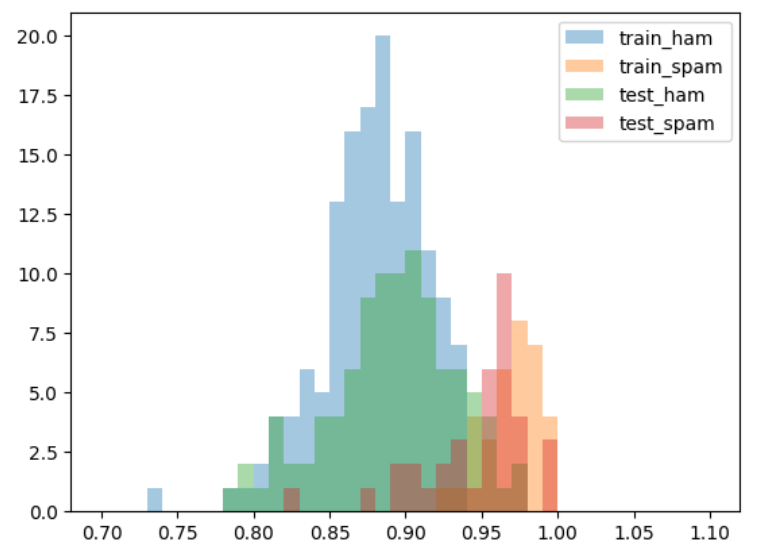
以前単純ベイズ法で扱った時より精度はよいとは言えなかった。前者は分類問題であったこともあるが、本手法でははっきりと話題が違うなど「意味」が異なるものを検知したい場合に適している可能性が考えられる。
今回はメールであり、さらにスパムメールという本物に似せて作られたものであったため難しかったのかもしれない。
ただし、こちらの記事でも同様に文書の異常検知について扱われており、こちらでは精度よく異常を検出している。
単語の出現数に基づくベクトル化ではなくdoc2vecなど文書の意味を反映したベクトル化などで精度が上がる可能性がある。
以上となります。
方向データという概念はここで知ったので、使える機会を探りたいと思いました。
次回
ガウス過程回帰による異常検知